 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Deep Neural Structures and their Interpretability in the Domain of Voice Conversion
Paper and Code

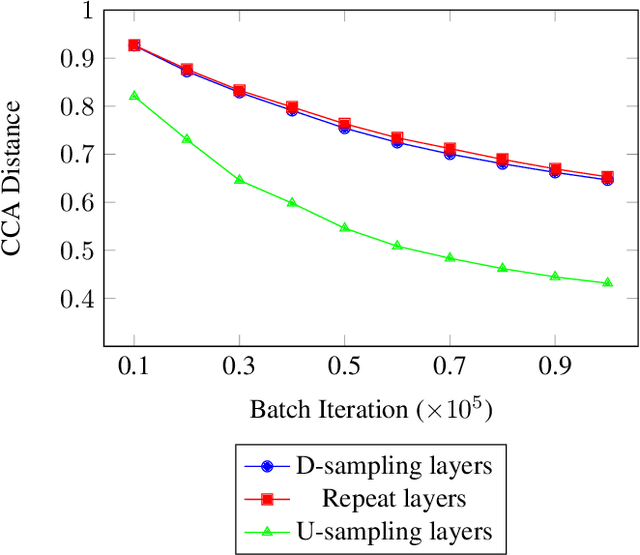


Generative Adversarial Networks (GANs) are machine learning networks based around creating synthetic data. Voice Conversion (VC) is a subset of voice translation that involves translating the paralinguistic features of a source speaker to a target speaker while preserving the linguistic information. The aim of non-parallel conditional GANs for VC is to translate an acoustic speech feature sequence from one domain to another without the use of paired data. In the study reported here, we investigated the interpretability of state-of-the-art implementations of non-parallel GANs in the domain of VC. We show that the learned representations in the repeating layers of a particular GAN architecture remain close to their original random initialised parameters, demonstrating that it is the number of repeating layers that is more responsible for the quality of the output. We also analysed the learned representations of a model trained on one particular dataset when used during transfer learning on another dataset. This showed extremely high levels of similarity across the entire network. Together, these results provide new insight into how the learned representations of deep generative networks change during learning and the importance in the number of layers.