 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneously Reconciled Quantile Forecasting of Hierarchically Related Time Series
Feb 25, 2021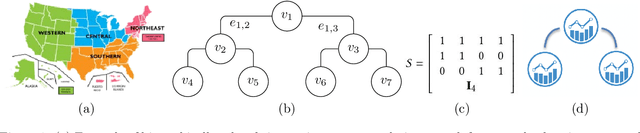
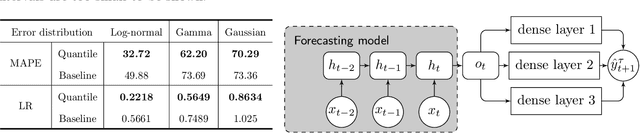
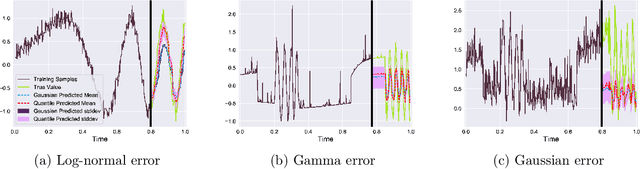

Many real-life applications involve simultaneously forecasting multiple time series that are hierarchically related via aggregation or disaggregation operations. For instance, commercial organizations often want to forecast inventories simultaneously at store, city, and state levels for resource planning purposes. In such applications, it is important that the forecasts, in addition to being reasonably accurate, are also consistent w.r.t one another. Although forecasting such hierarchical time series has been pursued by economists and data scientists, the current state-of-the-art models use strong assumptions, e.g., all forecasts being unbiased estimates, noise distribution being Gaussian. Besides, state-of-the-art models have not harnessed the power of modern nonlinear models, especially ones based on deep learning. In this paper, we propose using a flexible nonlinear model that optimizes quantile regression loss coupled with suitable regularization terms to maintain the consistency of forecasts across hierarchies. The theoretical framework introduced herein can be applied to any forecasting model with an underlying differentiable loss function. A proof of optimality of our proposed method is also provided. Simulation studies over a range of datasets highlight the efficacy of our approach.
Particle Clustering Machine: A Dynamical System Based Approach
Dec 30, 2017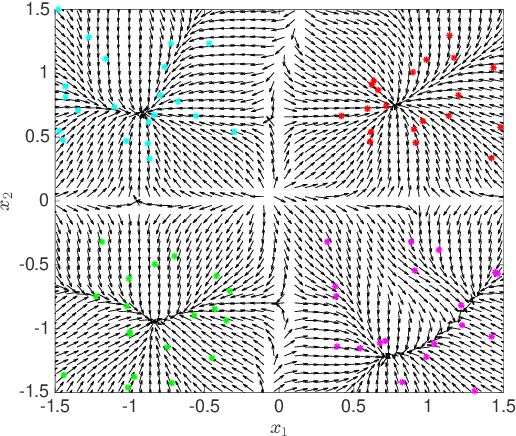

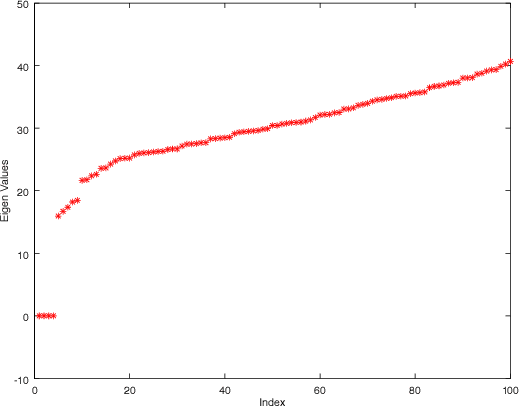
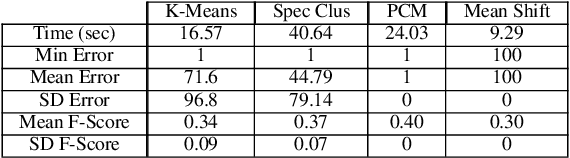
Identification of the clusters from an unlabeled data set is one of the most important problems in Unsupervised Machine Learning. The state of the art clustering algorithms are based on either the statistical properties or the geometric properties of the data set. In this work, we propose a novel method to cluster the data points using dynamical systems theory. After constructing a gradient dynamical system using interaction potential, we prove that the asymptotic dynamics of this system will determine the cluster centers, when the dynamical system is initialized at the data points. Most of the existing heuristic-based clustering techniques suffer from a disadvantage, namely the stochastic nature of the solution. Whereas, the proposed algorithm is deterministic, and the outcome would not change over multiple runs of the proposed algorithm with the same input data. Another advantage of the proposed method is that the number of clusters, which is difficult to determine in practice, does not have to be specified in advance. Simulation results with are presented, and comparisons are made with the existing methods.