 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning-based network intrusion detection for big and imbalanced data using oversampling, stacking feature embedding and feature extraction
Jan 22, 2024
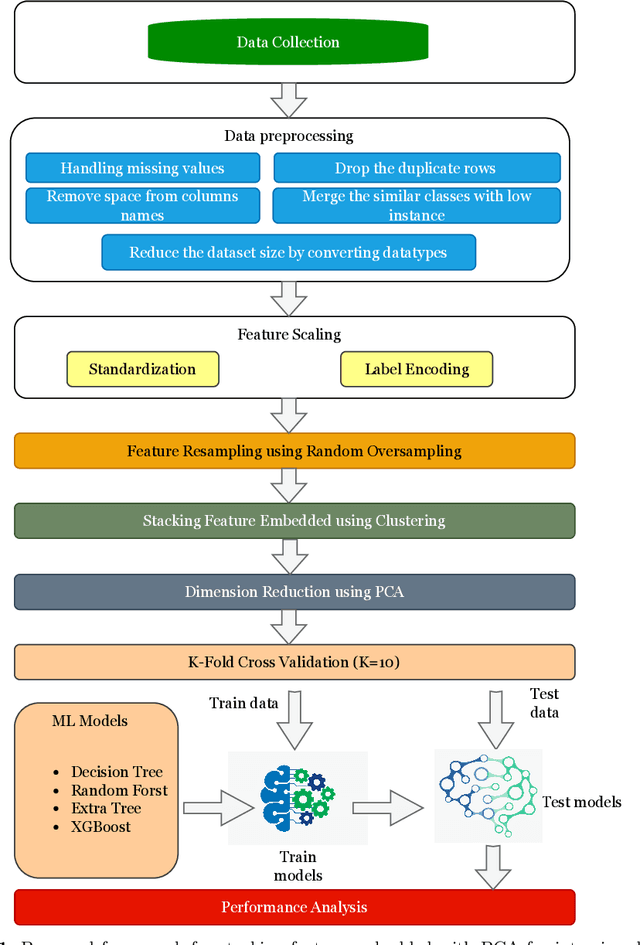

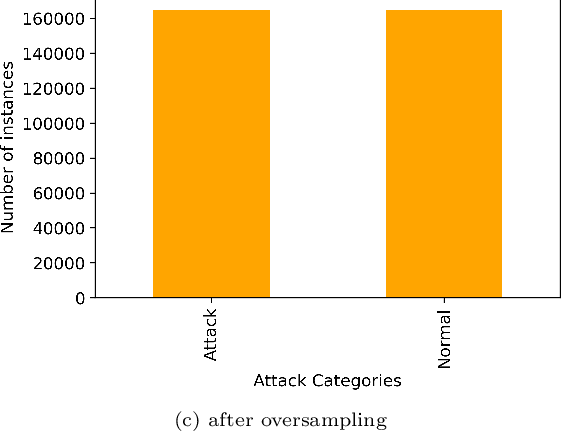
Cybersecurity has emerged as a critical global concern. Intrusion Detection Systems (IDS) play a critical role in protecting interconnected networks by detecting malicious actors and activities. Machine Learning (ML)-based behavior analysis within the IDS has considerable potential for detecting dynamic cyber threats, identifying abnormalities, and identifying malicious conduct within the network. However, as the number of data grows, dimension reduction becomes an increasingly difficult task when training ML models. Addressing this, our paper introduces a novel ML-based network intrusion detection model that uses Random Oversampling (RO) to address data imbalance and Stacking Feature Embedding based on clustering results, as well as Principal Component Analysis (PCA) for dimension reduction and is specifically designed for large and imbalanced datasets. This model's performance is carefully evaluated using three cutting-edge benchmark datasets: UNSW-NB15, CIC-IDS-2017, and CIC-IDS-2018. On the UNSW-NB15 dataset, our trials show that the RF and ET models achieve accuracy rates of 99.59% and 99.95%, respectively. Furthermore, using the CIC-IDS2017 dataset, DT, RF, and ET models reach 99.99% accuracy, while DT and RF models obtain 99.94% accuracy on CIC-IDS2018. These performance results continuously outperform the state-of-art, indicating significant progress in the field of network intrusion detection. This achievement demonstrates the efficacy of the suggested methodology, which can be used practically to accurately monitor and identify network traffic intrusions, thereby blocking possible threats.
Predicting Patient COVID-19 Disease Severity by means of Statistical and Machine Learning Analysis of Blood Cell Transcriptome Data
Nov 19, 2020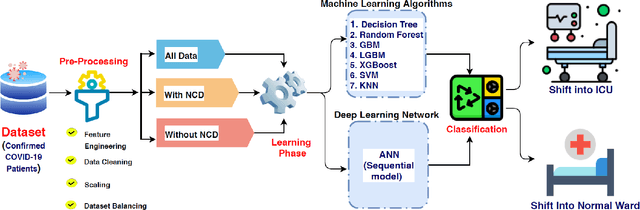
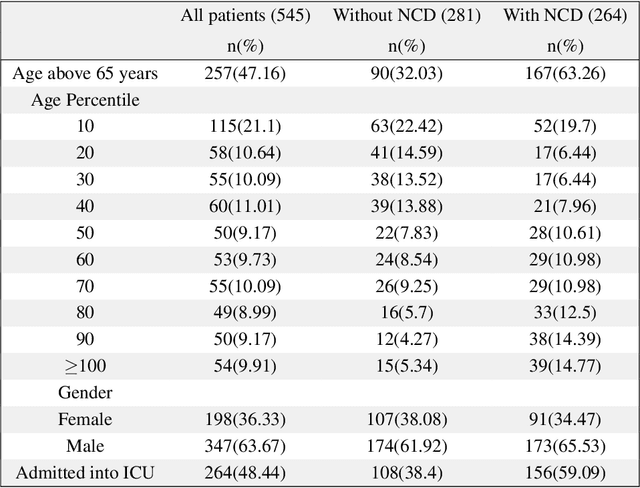
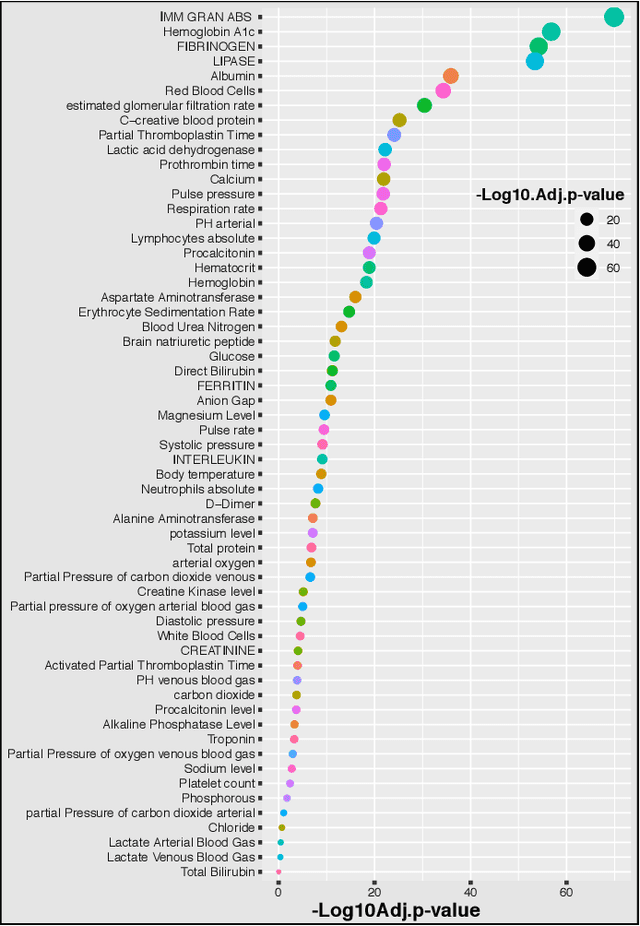
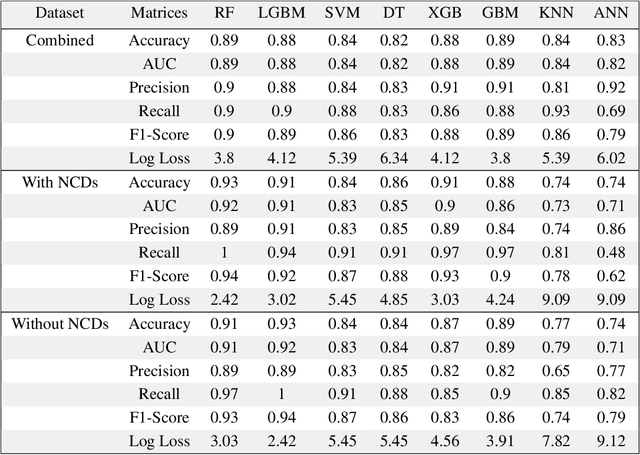
Introduction: For COVID-19 patients accurate prediction of disease severity and mortality risk would greatly improve care delivery and resource allocation. There are many patient-related factors, such as pre-existing comorbidities that affect disease severity. Since rapid automated profiling of peripheral blood samples is widely available, we investigated how such data from the peripheral blood of COVID-19 patients might be used to predict clinical outcomes. Methods: We thus investigated such clinical datasets from COVID-19 patients with known outcomes by combining statistical comparison and correlation methods with machine learning algorithms; the latter included decision tree, random forest, variants of gradient boosting machine, support vector machine, K-nearest neighbour and deep learning methods. Results: Our work revealed several clinical parameters measurable in blood samples, which discriminated between healthy people and COVID-19 positive patients and showed predictive value for later severity of COVID-19 symptoms. We thus developed a number of analytic methods that showed accuracy and precision for disease severity and mortality outcome predictions that were above 90%. Conclusions: In sum, we developed methodologies to analyse patient routine clinical data which enables more accurate prediction of COVID-19 patient outcomes. This type of approaches could, by employing standard hospital laboratory analyses of patient blood, be utilised to identify, COVID-19 patients at high risk of mortality and so enable their treatment to be optimised.