 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrugal Prompting for Dialog Models
May 24, 2023



The use of large language models (LLMs) in natural language processing (NLP) tasks is rapidly increasing, leading to changes in how researchers approach problems in the field. To fully utilize these models' abilities, a better understanding of their behavior for different input protocols is required. With LLMs, users can directly interact with the models through a text-based interface to define and solve various tasks. Hence, understanding the conversational abilities of these LLMs, which may not have been specifically trained for dialog modeling, is also important. This study examines different approaches for building dialog systems using LLMs by considering various aspects of the prompt. As part of prompt tuning, we experiment with various ways of providing instructions, exemplars, current query and additional context. The research also analyzes the representations of dialog history that have the optimal usable-information density. Based on the findings, the paper suggests more compact ways of providing dialog history information while ensuring good performance and reducing model's inference-API costs. The research contributes to a better understanding of how LLMs can be effectively used for building interactive systems.
End-to-end lyrics Recognition with Voice to Singing Style Transfer
Feb 17, 2021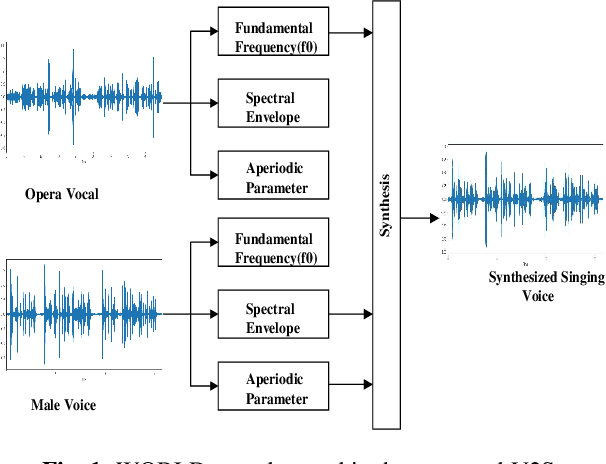

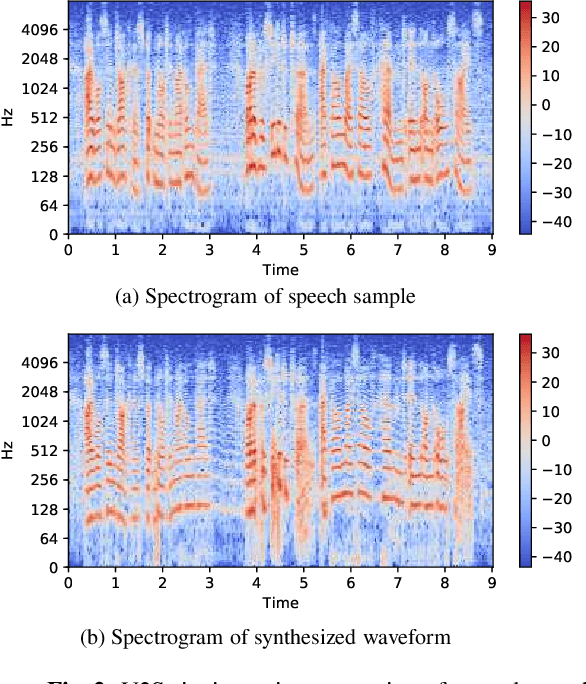
Automatic transcription of monophonic/polyphonic music is a challenging task due to the lack of availability of large amounts of transcribed data. In this paper, we propose a data augmentation method that converts natural speech to singing voice based on vocoder based speech synthesizer. This approach, called voice to singing (V2S), performs the voice style conversion by modulating the F0 contour of the natural speech with that of a singing voice. The V2S model based style transfer can generate good quality singing voice thereby enabling the conversion of large corpora of natural speech to singing voice that is useful in building an E2E lyrics transcription system. In our experiments on monophonic singing voice data, the V2S style transfer provides a significant gain (relative improvements of 21%) for the E2E lyrics transcription system. We also discuss additional components like transfer learning and lyrics based language modeling to improve the performance of the lyrics transcription system.
Improving Voice Separation by Incorporating End-to-end Speech Recognition
Nov 29, 2019
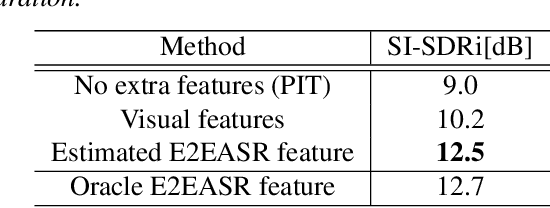
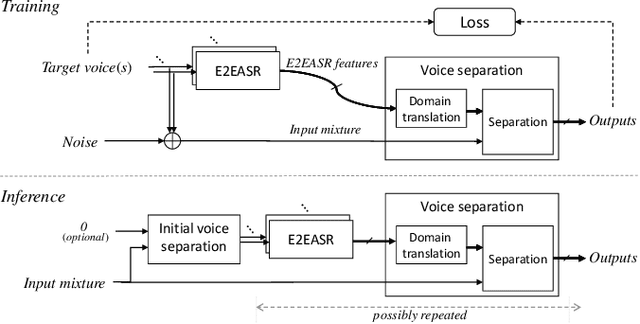

Despite recent advances in voice separation methods, many challenges remain in realistic scenarios such as noisy recording and the limits of available data. In this work, we propose to explicitly incorporate the phonetic and linguistic nature of speech by taking a transfer learning approach using an end-to-end automatic speech recognition (E2EASR) system. The voice separation is conditioned on deep features extracted from E2EASR to cover the long-term dependence of phonetic aspects. Experimental results on speech separation and enhancement task on the AVSpeech dataset show that the proposed method significantly improves the signal-to-distortion ratio over the baseline model and even outperforms an audio visual model, that utilizes visual information of lip movements.