 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end lyrics Recognition with Voice to Singing Style Transfer
Paper and Code
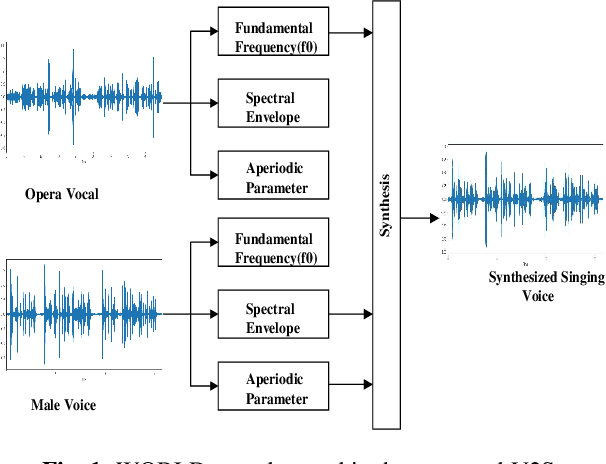

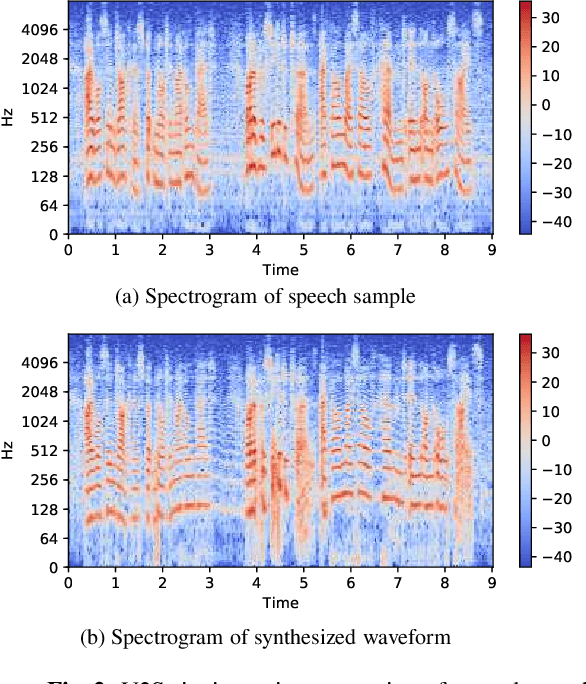
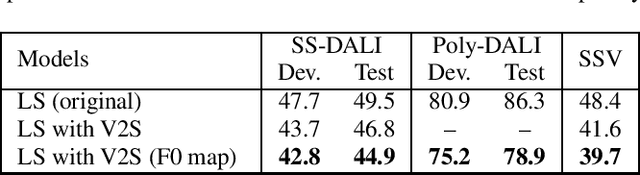
Automatic transcription of monophonic/polyphonic music is a challenging task due to the lack of availability of large amounts of transcribed data. In this paper, we propose a data augmentation method that converts natural speech to singing voice based on vocoder based speech synthesizer. This approach, called voice to singing (V2S), performs the voice style conversion by modulating the F0 contour of the natural speech with that of a singing voice. The V2S model based style transfer can generate good quality singing voice thereby enabling the conversion of large corpora of natural speech to singing voice that is useful in building an E2E lyrics transcription system. In our experiments on monophonic singing voice data, the V2S style transfer provides a significant gain (relative improvements of 21%) for the E2E lyrics transcription system. We also discuss additional components like transfer learning and lyrics based language modeling to improve the performance of the lyrics transcription system.