 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Symmetrical Convolutional Transformer Networks for Speech to Singing Voice Style Transfer
Aug 26, 2022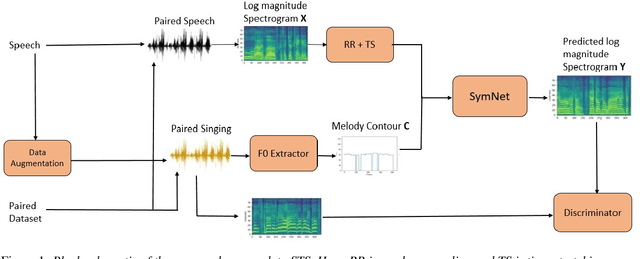

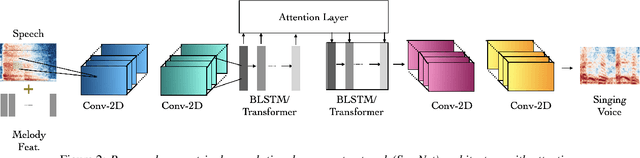
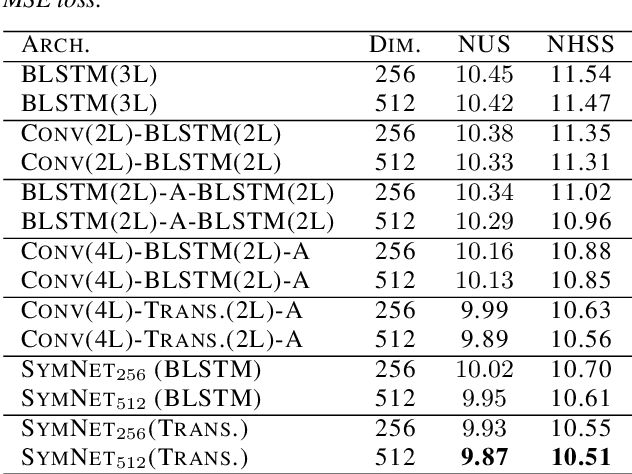
In this paper, we propose a model to perform style transfer of speech to singing voice. Contrary to the previous signal processing-based methods, which require high-quality singing templates or phoneme synchronization, we explore a data-driven approach for the problem of converting natural speech to singing voice. We develop a novel neural network architecture, called SymNet, which models the alignment of the input speech with the target melody while preserving the speaker identity and naturalness. The proposed SymNet model is comprised of symmetrical stack of three types of layers - convolutional, transformer, and self-attention layers. The paper also explores novel data augmentation and generative loss annealing methods to facilitate the model training. Experiments are performed on the NUS and NHSS datasets which consist of parallel data of speech and singing voice. In these experiments, we show that the proposed SymNet model improves the objective reconstruction quality significantly over the previously published methods and baseline architectures. Further, a subjective listening test confirms the improved quality of the audio obtained using the proposed approach (absolute improvement of 0.37 in mean opinion score measure over the baseline system).
End-to-end lyrics Recognition with Voice to Singing Style Transfer
Feb 17, 2021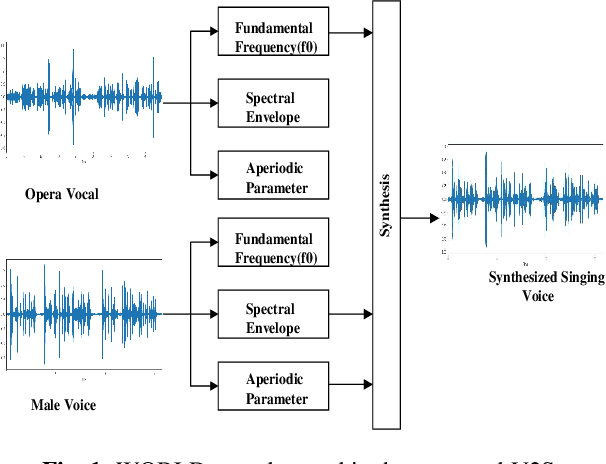

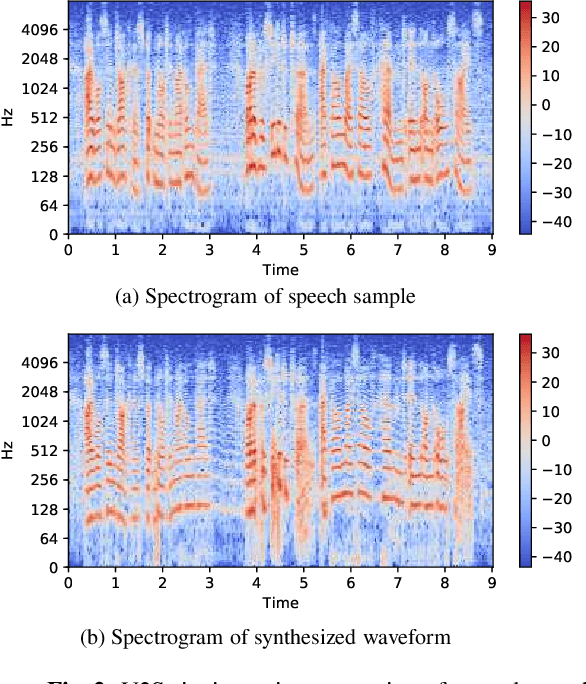
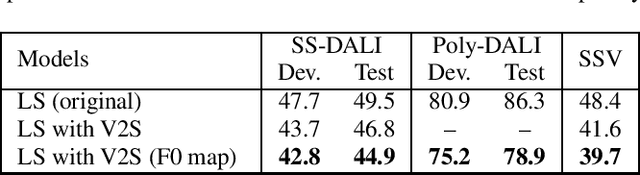
Automatic transcription of monophonic/polyphonic music is a challenging task due to the lack of availability of large amounts of transcribed data. In this paper, we propose a data augmentation method that converts natural speech to singing voice based on vocoder based speech synthesizer. This approach, called voice to singing (V2S), performs the voice style conversion by modulating the F0 contour of the natural speech with that of a singing voice. The V2S model based style transfer can generate good quality singing voice thereby enabling the conversion of large corpora of natural speech to singing voice that is useful in building an E2E lyrics transcription system. In our experiments on monophonic singing voice data, the V2S style transfer provides a significant gain (relative improvements of 21%) for the E2E lyrics transcription system. We also discuss additional components like transfer learning and lyrics based language modeling to improve the performance of the lyrics transcription system.