 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Prototypical Transformer for Whole Slide Image Classification
Jul 05, 2023Whole slide image (WSI) classification is an essential task in computational pathology. Despite the recent advances in multiple instance learning (MIL) for WSI classification, accurate classification of WSIs remains challenging due to the extreme imbalance between the positive and negative instances in bags, and the complicated pre-processing to fuse multi-scale information of WSI. To this end, we propose a novel multi-scale prototypical Transformer (MSPT) for WSI classification, which includes a prototypical Transformer (PT) module and a multi-scale feature fusion module (MFFM). The PT is developed to reduce redundant instances in bags by integrating prototypical learning into the Transformer architecture. It substitutes all instances with cluster prototypes, which are then re-calibrated through the self-attention mechanism of the Trans-former. Thereafter, an MFFM is proposed to fuse the clustered prototypes of different scales, which employs MLP-Mixer to enhance the information communication between prototypes. The experimental results on two public WSI datasets demonstrate that the proposed MSPT outperforms all the compared algorithms, suggesting its potential applications.
Multi-scale Efficient Graph-Transformer for Whole Slide Image Classification
May 25, 2023The multi-scale information among the whole slide images (WSIs) is essential for cancer diagnosis. Although the existing multi-scale vision Transformer has shown its effectiveness for learning multi-scale image representation, it still cannot work well on the gigapixel WSIs due to their extremely large image sizes. To this end, we propose a novel Multi-scale Efficient Graph-Transformer (MEGT) framework for WSI classification. The key idea of MEGT is to adopt two independent Efficient Graph-based Transformer (EGT) branches to process the low-resolution and high-resolution patch embeddings (i.e., tokens in a Transformer) of WSIs, respectively, and then fuse these tokens via a multi-scale feature fusion module (MFFM). Specifically, we design an EGT to efficiently learn the local-global information of patch tokens, which integrates the graph representation into Transformer to capture spatial-related information of WSIs. Meanwhile, we propose a novel MFFM to alleviate the semantic gap among different resolution patches during feature fusion, which creates a non-patch token for each branch as an agent to exchange information with another branch by cross-attention. In addition, to expedite network training, a novel token pruning module is developed in EGT to reduce the redundant tokens. Extensive experiments on TCGA-RCC and CAMELYON16 datasets demonstrate the effectiveness of the proposed MEGT.
Pseudo-Data based Self-Supervised Federated Learning for Classification of Histopathological Images
May 31, 2022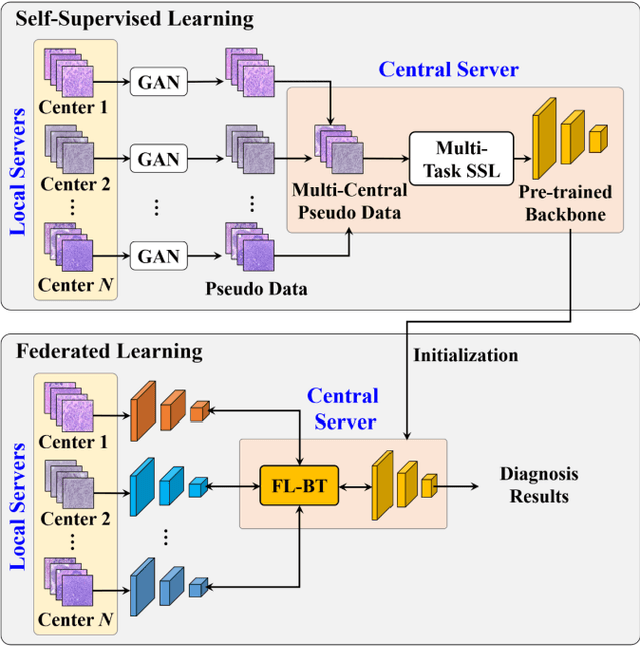
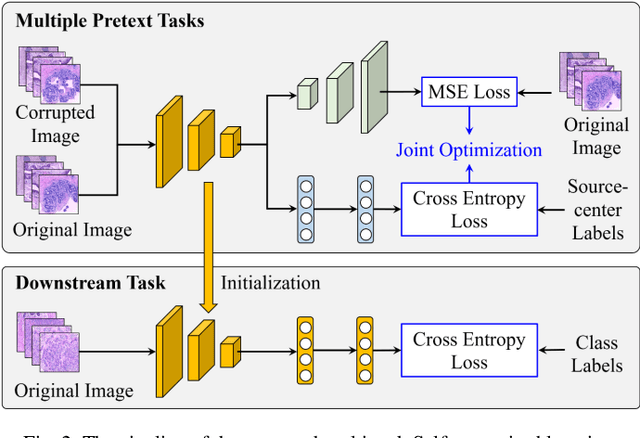
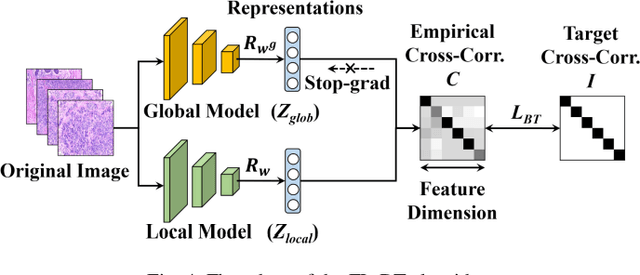
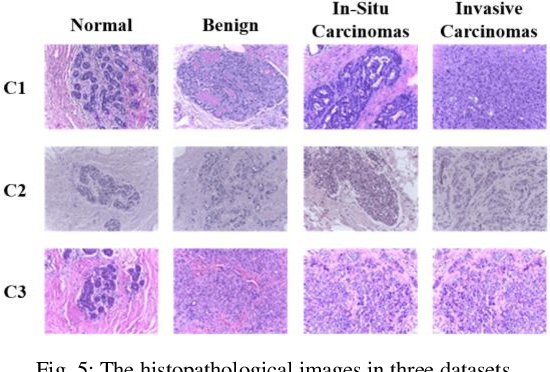
Computer-aided diagnosis (CAD) can help pathologists improve diagnostic accuracy together with consistency and repeatability for cancers. However, the CAD models trained with the histopathological images only from a single center (hospital) generally suffer from the generalization problem due to the straining inconsistencies among different centers. In this work, we propose a pseudo-data based self-supervised federated learning (FL) framework, named SSL-FT-BT, to improve both the diagnostic accuracy and generalization of CAD models. Specifically, the pseudo histopathological images are generated from each center, which contains inherent and specific properties corresponding to the real images in this center, but does not include the privacy information. These pseudo images are then shared in the central server for self-supervised learning (SSL). A multi-task SSL is then designed to fully learn both the center-specific information and common inherent representation according to the data characteristics. Moreover, a novel Barlow Twins based FL (FL-BT) algorithm is proposed to improve the local training for the CAD model in each center by conducting contrastive learning, which benefits the optimization of the global model in the FL procedure. The experimental results on three public histopathological image datasets indicate the effectiveness of the proposed SSL-FL-BT on both diagnostic accuracy and generalization.