 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximin Robust Bayesian Experimental Design
Mar 14, 2026We address the brittleness of Bayesian experimental design under model misspecification by formulating the problem as a max--min game between the experimenter and an adversarial nature subject to information-theoretic constraints. We demonstrate that this approach yields a robust objective governed by Sibson's $α$-mutual information~(MI), which identifies the $α$-tilted posterior as the robust belief update and establishes the Rényi divergence as the appropriate measure of conditional information gain. To mitigate the bias and variance of nested Monte Carlo estimators needed to estimate Sibson's $α$-MI, we adopt a PAC-Bayes framework to search over stochastic design policies, yielding rigorous high-probability lower bounds on the robust expected information gain that explicitly control finite-sample error.
Online Bayesian Experimental Design for Partially Observed Dynamical Systems
Nov 06, 2025
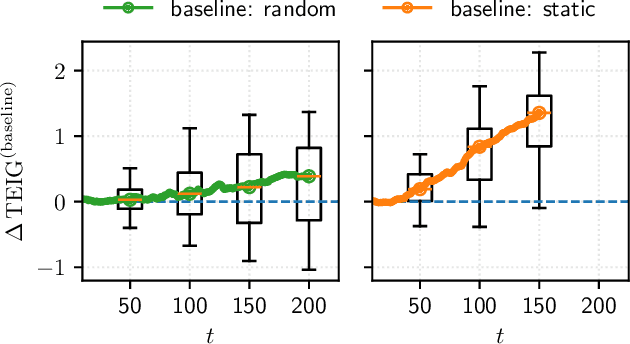
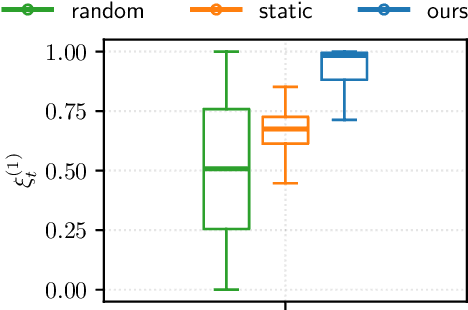
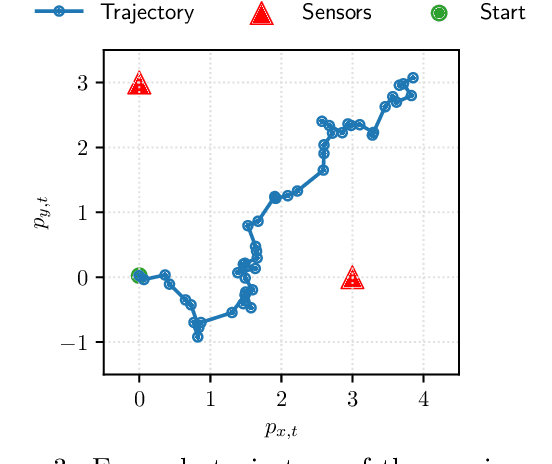
Bayesian experimental design (BED) provides a principled framework for optimizing data collection, but existing approaches do not apply to crucial real-world settings such as dynamical systems with partial observability, where only noisy and incomplete observations are available. These systems are naturally modeled as state-space models (SSMs), where latent states mediate the link between parameters and data, making the likelihood -- and thus information-theoretic objectives like the expected information gain (EIG) -- intractable. In addition, the dynamical nature of the system requires online algorithms that update posterior distributions and select designs sequentially in a computationally efficient manner. We address these challenges by deriving new estimators of the EIG and its gradient that explicitly marginalize latent states, enabling scalable stochastic optimization in nonlinear SSMs. Our approach leverages nested particle filters (NPFs) for efficient online inference with convergence guarantees. Applications to realistic models, such as the susceptible-infected-recovered (SIR) and a moving source location task, show that our framework successfully handles both partial observability and online computation.
Sequential Monte Carlo for Policy Optimization in Continuous POMDPs
May 22, 2025



Optimal decision-making under partial observability requires agents to balance reducing uncertainty (exploration) against pursuing immediate objectives (exploitation). In this paper, we introduce a novel policy optimization framework for continuous partially observable Markov decision processes (POMDPs) that explicitly addresses this challenge. Our method casts policy learning as probabilistic inference in a non-Markovian Feynman--Kac model that inherently captures the value of information gathering by anticipating future observations, without requiring extrinsic exploration bonuses or handcrafted heuristics. To optimize policies under this model, we develop a nested sequential Monte Carlo~(SMC) algorithm that efficiently estimates a history-dependent policy gradient under samples from the optimal trajectory distribution induced by the POMDP. We demonstrate the effectiveness of our algorithm across standard continuous POMDP benchmarks, where existing methods struggle to act under uncertainty.
Recursive Nested Filtering for Efficient Amortized Bayesian Experimental Design
Sep 09, 2024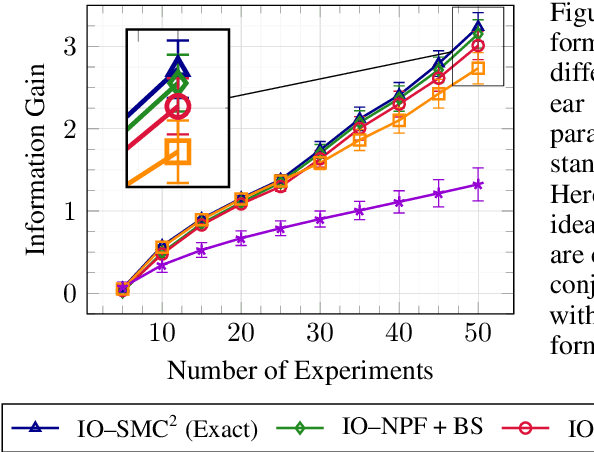
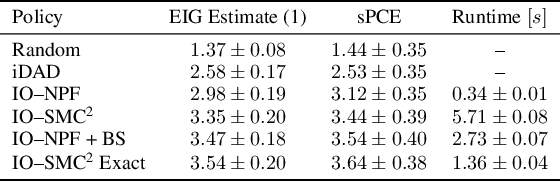


This paper introduces the Inside-Out Nested Particle Filter (IO-NPF), a novel, fully recursive, algorithm for amortized sequential Bayesian experimental design in the non-exchangeable setting. We frame policy optimization as maximum likelihood estimation in a non-Markovian state-space model, achieving (at most) $\mathcal{O}(T^2)$ computational complexity in the number of experiments. We provide theoretical convergence guarantees and introduce a backward sampling algorithm to reduce trajectory degeneracy. IO-NPF offers a practical, extensible, and provably consistent approach to sequential Bayesian experimental design, demonstrating improved efficiency over existing methods.
Nesting Particle Filters for Experimental Design in Dynamical Systems
Feb 12, 2024In this paper, we propose a novel approach to Bayesian Experimental Design (BED) for non-exchangeable data that formulates it as risk-sensitive policy optimization. We develop the Inside-Out SMC^2 algorithm that uses a nested sequential Monte Carlo (SMC) estimator of the expected information gain and embeds it into a particle Markov chain Monte Carlo (pMCMC) framework to perform gradient-based policy optimization. This is in contrast to recent approaches that rely on biased estimators of the expected information gain (EIG) to amortize the cost of experiments by learning a design policy in advance. Numerical validation on a set of dynamical systems showcases the efficacy of our method in comparison to other state-of-the-art strategies.
Risk-Sensitive Stochastic Optimal Control as Rao-Blackwellized Markovian Score Climbing
Dec 21, 2023Stochastic optimal control of dynamical systems is a crucial challenge in sequential decision-making. Recently, control-as-inference approaches have had considerable success, providing a viable risk-sensitive framework to address the exploration-exploitation dilemma. Nonetheless, a majority of these techniques only invoke the inference-control duality to derive a modified risk objective that is then addressed within a reinforcement learning framework. This paper introduces a novel perspective by framing risk-sensitive stochastic control as Markovian score climbing under samples drawn from a conditional particle filter. Our approach, while purely inference-centric, provides asymptotically unbiased estimates for gradient-based policy optimization with optimal importance weighting and no explicit value function learning. To validate our methodology, we apply it to the task of learning neural non-Gaussian feedback policies, showcasing its efficacy on numerical benchmarks of stochastic dynamical systems.