 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressive Recovery of Signals Defined on Perturbed Graphs
Feb 16, 2024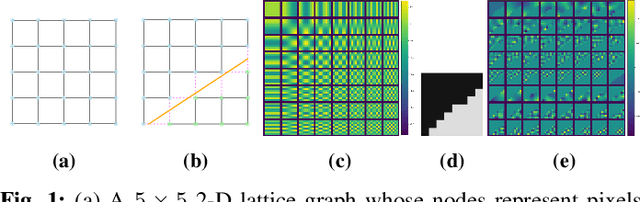
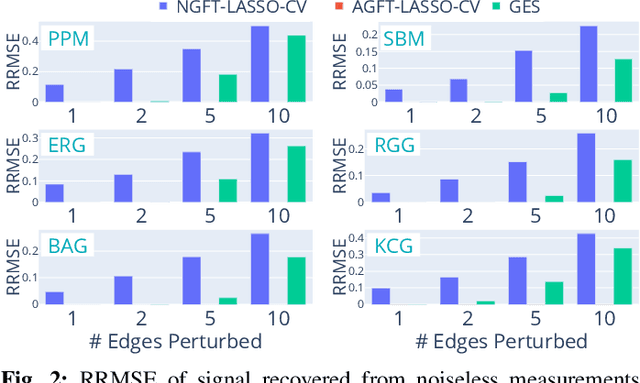
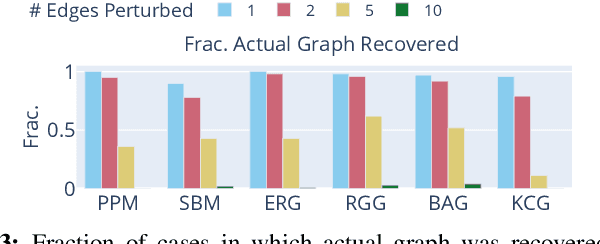
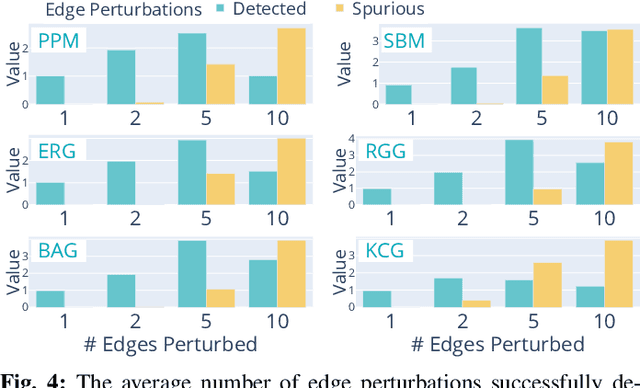
Recovery of signals with elements defined on the nodes of a graph, from compressive measurements is an important problem, which can arise in various domains such as sensor networks, image reconstruction and group testing. In some scenarios, the graph may not be accurately known, and there may exist a few edge additions or deletions relative to a ground truth graph. Such perturbations, even if small in number, significantly affect the Graph Fourier Transform (GFT). This impedes recovery of signals which may have sparse representations in the GFT bases of the ground truth graph. We present an algorithm which simultaneously recovers the signal from the compressive measurements and also corrects the graph perturbations. We analyze some important theoretical properties of the algorithm. Our approach to correction for graph perturbations is based on model selection techniques such as cross-validation in compressed sensing. We validate our algorithm on signals which have a sparse representation in the GFT bases of many commonly used graphs in the network science literature. An application to compressive image reconstruction is also presented, where graph perturbations are modeled as undesirable graph edges linking pixels with significant intensity difference. In all experiments, our algorithm clearly outperforms baseline techniques which either ignore the perturbations or use first order approximations to the perturbations in the GFT bases.
Efficient Neural Network based Classification and Outlier Detection for Image Moderation using Compressed Sensing and Group Testing
May 12, 2023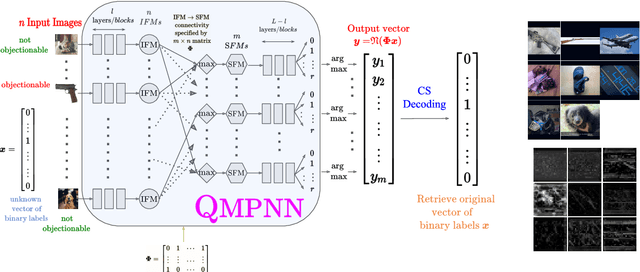

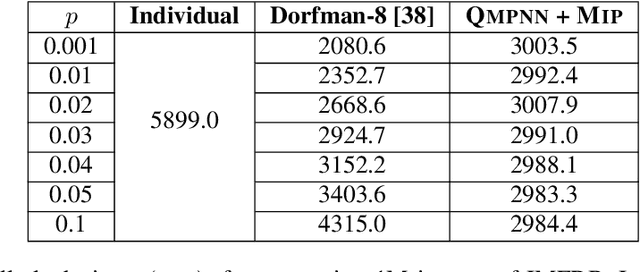
Popular social media platforms employ neural network based image moderation engines to classify images uploaded on them as having potentially objectionable content. Such moderation engines must answer a large number of queries with heavy computational cost, even though the actual number of images with objectionable content is usually a tiny fraction. Inspired by recent work on Neural Group Testing, we propose an approach which exploits this fact to reduce the overall computational cost of such engines using the technique of Compressed Sensing (CS). We present the quantitative matrix-pooled neural network (QMPNN), which takes as input $n$ images, and a $m \times n$ binary pooling matrix with $m < n$, whose rows indicate $m$ pools of images i.e. selections of $r$ images out of $n$. The QMPNN efficiently outputs the product of this matrix with the unknown sparse binary vector indicating whether each image is objectionable or not, i.e. it outputs the number of objectionable images in each pool. For suitable matrices, this is decoded using CS decoding algorithms to predict which images were objectionable. The computational cost of running the QMPNN and the CS algorithms is significantly lower than the cost of using a neural network with the same number of parameters separately on each image to classify the images, which we demonstrate via extensive experiments. Our technique is inherently resilient to moderate levels of errors in the prediction from the QMPNN. Furthermore, we present pooled deep outlier detection, which brings CS and group testing techniques to deep outlier detection, to provide for the case when the objectionable images do not belong to a set of pre-defined classes. This technique enables efficient automated moderation of off-topic images shared on topical forums dedicated to sharing images of a certain single class, many of which are currently human-moderated.
Learning from Rules Generalizing Labeled Exemplars
May 15, 2020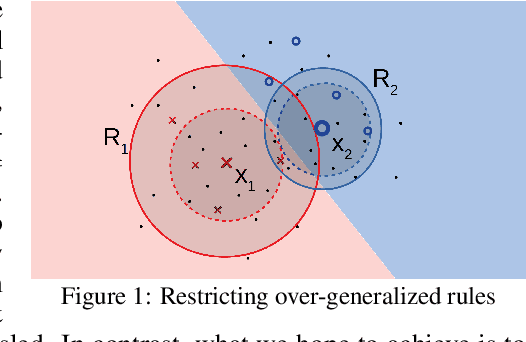
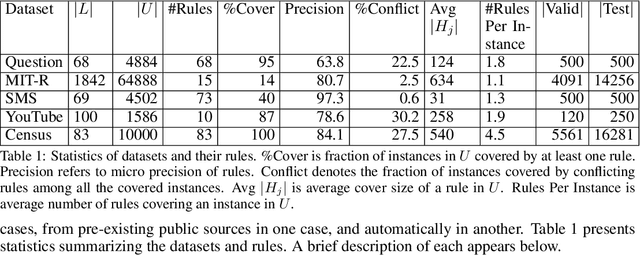
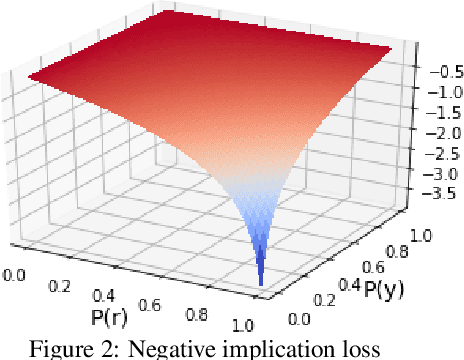
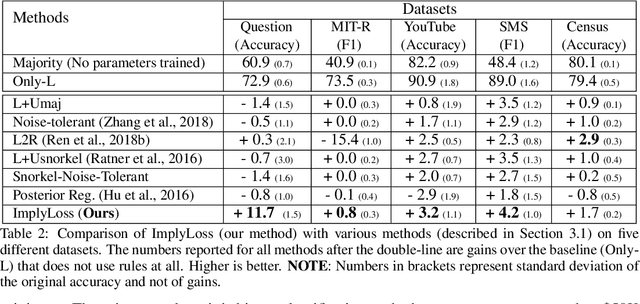
In many applications labeled data is not readily available, and needs to be collected via pain-staking human supervision. We propose a rule-exemplar method for collecting human supervision to combine the efficiency of rules with the quality of instance labels. The supervision is coupled such that it is both natural for humans and synergistic for learning. We propose a training algorithm that jointly denoises rules via latent coverage variables, and trains the model through a soft implication loss over the coverage and label variables. The denoised rules and trained model are used jointly for inference. Empirical evaluation on five different tasks shows that (1) our algorithm is more accurate than several existing methods of learning from a mix of clean and noisy supervision, and (2) the coupled rule-exemplar supervision is effective in denoising rules.
Parallel Iterative Edit Models for Local Sequence Transduction
Oct 07, 2019

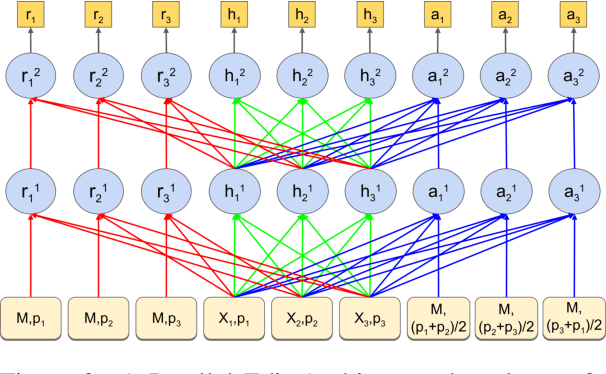
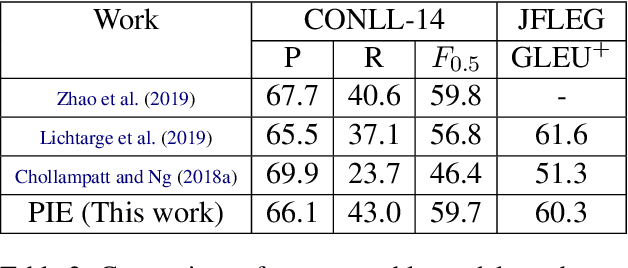
We present a Parallel Iterative Edit (PIE) model for the problem of local sequence transduction arising in tasks like Grammatical error correction (GEC). Recent approaches are based on the popular encoder-decoder (ED) model for sequence to sequence learning. The ED model auto-regressively captures full dependency among output tokens but is slow due to sequential decoding. The PIE model does parallel decoding, giving up the advantage of modelling full dependency in the output, yet it achieves accuracy competitive with the ED model for four reasons: 1.~predicting edits instead of tokens, 2.~labeling sequences instead of generating sequences, 3.~iteratively refining predictions to capture dependencies, and 4.~factorizing logits over edits and their token argument to harness pre-trained language models like BERT. Experiments on tasks spanning GEC, OCR correction and spell correction demonstrate that the PIE model is an accurate and significantly faster alternative for local sequence transduction.