 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Rules Generalizing Labeled Exemplars
May 15, 2020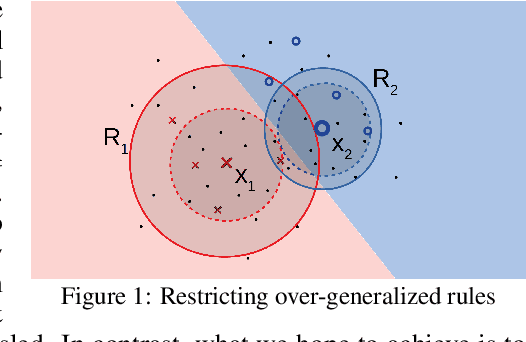
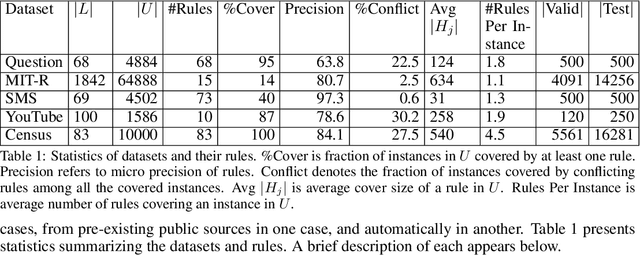
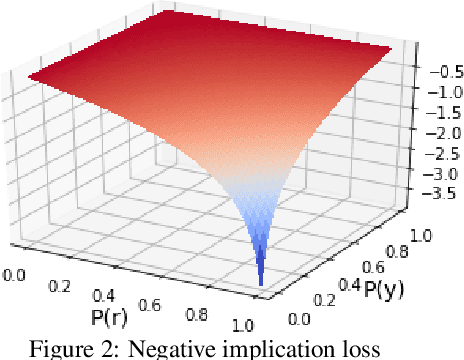
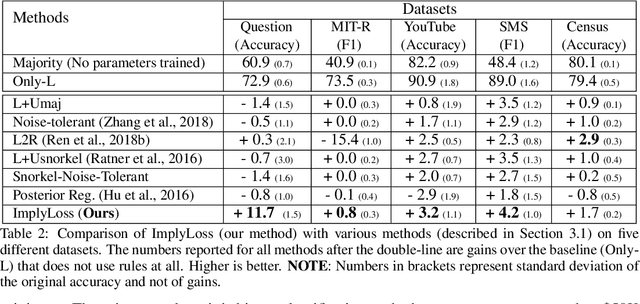
In many applications labeled data is not readily available, and needs to be collected via pain-staking human supervision. We propose a rule-exemplar method for collecting human supervision to combine the efficiency of rules with the quality of instance labels. The supervision is coupled such that it is both natural for humans and synergistic for learning. We propose a training algorithm that jointly denoises rules via latent coverage variables, and trains the model through a soft implication loss over the coverage and label variables. The denoised rules and trained model are used jointly for inference. Empirical evaluation on five different tasks shows that (1) our algorithm is more accurate than several existing methods of learning from a mix of clean and noisy supervision, and (2) the coupled rule-exemplar supervision is effective in denoising rules.
Parallel Iterative Edit Models for Local Sequence Transduction
Oct 07, 2019

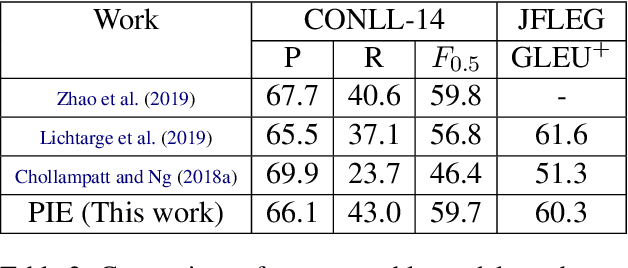
We present a Parallel Iterative Edit (PIE) model for the problem of local sequence transduction arising in tasks like Grammatical error correction (GEC). Recent approaches are based on the popular encoder-decoder (ED) model for sequence to sequence learning. The ED model auto-regressively captures full dependency among output tokens but is slow due to sequential decoding. The PIE model does parallel decoding, giving up the advantage of modelling full dependency in the output, yet it achieves accuracy competitive with the ED model for four reasons: 1.~predicting edits instead of tokens, 2.~labeling sequences instead of generating sequences, 3.~iteratively refining predictions to capture dependencies, and 4.~factorizing logits over edits and their token argument to harness pre-trained language models like BERT. Experiments on tasks spanning GEC, OCR correction and spell correction demonstrate that the PIE model is an accurate and significantly faster alternative for local sequence transduction.