 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHATTER: A Character Attribution Dataset for Narrative Understanding
Nov 07, 2024Computational narrative understanding studies the identification, description, and interaction of the elements of a narrative: characters, attributes, events, and relations. Narrative research has given considerable attention to defining and classifying character types. However, these character-type taxonomies do not generalize well because they are small, too simple, or specific to a domain. We require robust and reliable benchmarks to test whether narrative models truly understand the nuances of the character's development in the story. Our work addresses this by curating the Chatter dataset that labels whether a character portrays some attribute for 88148 character-attribute pairs, encompassing 2998 characters, 13324 attributes and 660 movies. We validate a subset of Chatter, called ChatterEval, using human annotations to serve as an evaluation benchmark for the character attribution task in movie scripts. ChatterEval assesses narrative understanding and the long-context modeling capacity of language models.
Using Emotion Embeddings to Transfer Knowledge Between Emotions, Languages, and Annotation Formats
Oct 31, 2022The need for emotional inference from text continues to diversify as more and more disciplines integrate emotions into their theories and applications. These needs include inferring different emotion types, handling multiple languages, and different annotation formats. A shared model between different configurations would enable the sharing of knowledge and a decrease in training costs, and would simplify the process of deploying emotion recognition models in novel environments. In this work, we study how we can build a single model that can transition between these different configurations by leveraging multilingual models and Demux, a transformer-based model whose input includes the emotions of interest, enabling us to dynamically change the emotions predicted by the model. Demux also produces emotion embeddings, and performing operations on them allows us to transition to clusters of emotions by pooling the embeddings of each cluster. We show that Demux can simultaneously transfer knowledge in a zero-shot manner to a new language, to a novel annotation format and to unseen emotions. Code is available at https://github.com/gchochla/Demux-MEmo .
Leveraging Label Correlations in a Multi-label Setting: A Case Study in Emotion
Oct 28, 2022


Detecting emotions expressed in text has become critical to a range of fields. In this work, we investigate ways to exploit label correlations in multi-label emotion recognition models to improve emotion detection. First, we develop two modeling approaches to the problem in order to capture word associations of the emotion words themselves, by either including the emotions in the input, or by leveraging Masked Language Modeling (MLM). Second, we integrate pairwise constraints of emotion representations as regularization terms alongside the classification loss of the models. We split these terms into two categories, local and global. The former dynamically change based on the gold labels, while the latter remain static during training. We demonstrate state-of-the-art performance across Spanish, English, and Arabic in SemEval 2018 Task 1 E-c using monolingual BERT-based models. On top of better performance, we also demonstrate improved robustness. Code is available at https://github.com/gchochla/Demux-MEmo.
Representation of professions in entertainment media: Insights into frequency and sentiment trends through computational text analysis
Oct 11, 2021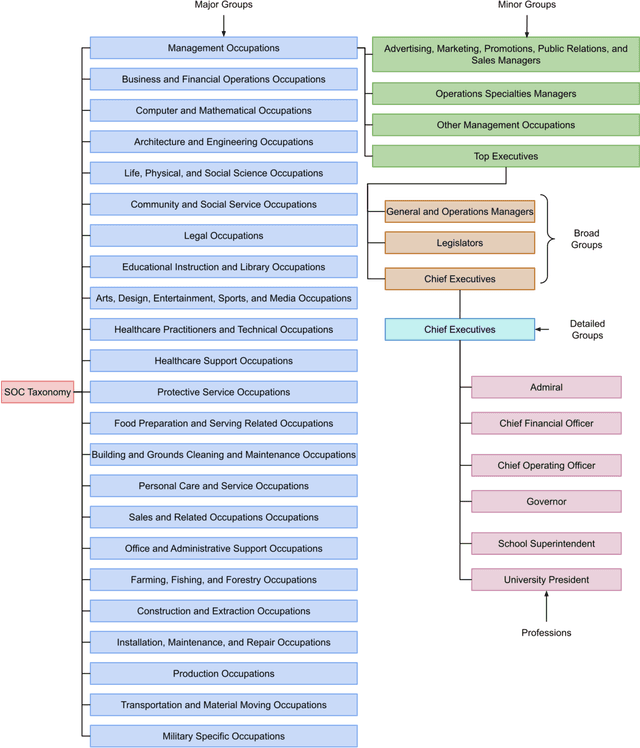


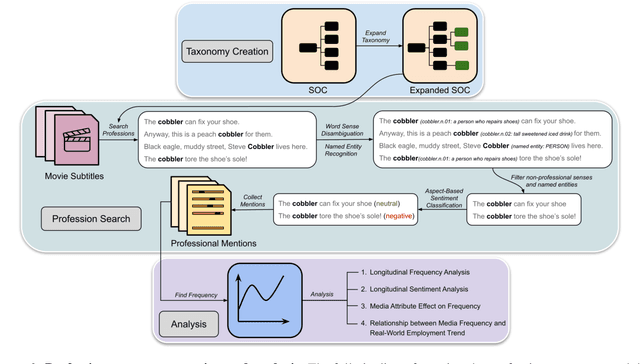
Societal ideas and trends dictate media narratives and cinematic depictions which in turn influences people's beliefs and perceptions of the real world. Media portrayal of culture, education, government, religion, and family affect their function and evolution over time as people interpret and perceive these representations and incorporate them into their beliefs and actions. It is important to study media depictions of these social structures so that they do not propagate or reinforce negative stereotypes, or discriminate against any demographic section. In this work, we examine media representation of professions and provide computational insights into their incidence, and sentiment expressed, in entertainment media content. We create a searchable taxonomy of professional groups and titles to facilitate their retrieval from speaker-agnostic text passages like movie and television (TV) show subtitles. We leverage this taxonomy and relevant natural language processing (NLP) models to create a corpus of professional mentions in media content, spanning more than 136,000 IMDb titles over seven decades (1950-2017). We analyze the frequency and sentiment trends of different occupations, study the effect of media attributes like genre, country of production, and title type on these trends, and investigate if the incidence of professions in media subtitles correlate with their real-world employment statistics. We observe increased media mentions of STEM, arts, sports, and entertainment occupations in the analyzed subtitles, and a decreased frequency of manual labor jobs and military occupations. The sentiment expressed toward lawyers, police, and doctors is becoming negative over time, whereas astronauts, musicians, singers, and engineers are mentioned favorably. Professions that employ more people have increased media frequency, supporting our hypothesis that media acts as a mirror to society.
Cross Domain Emotion Recognition using Few Shot Knowledge Transfer
Oct 11, 2021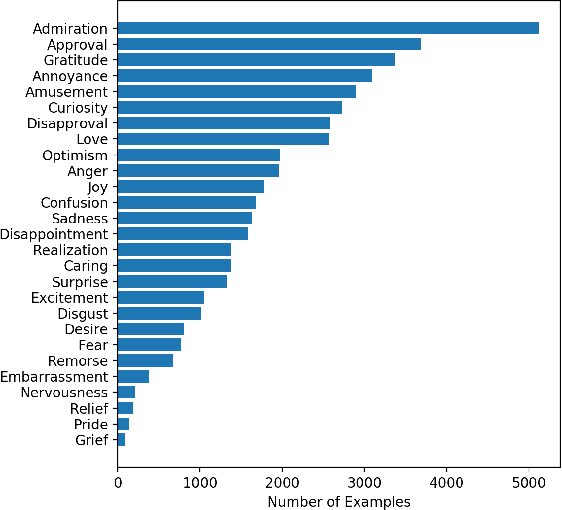
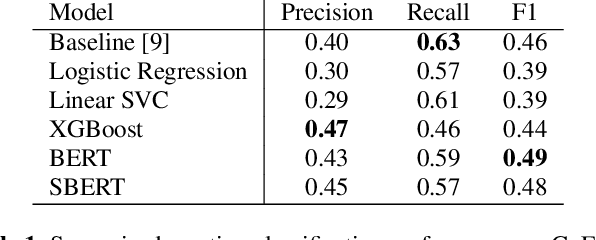
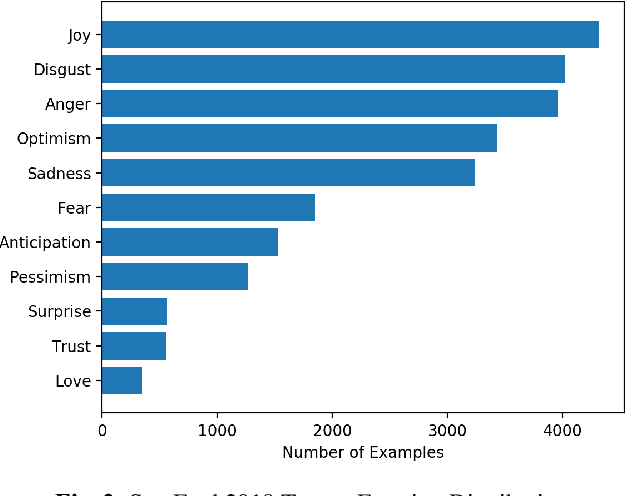
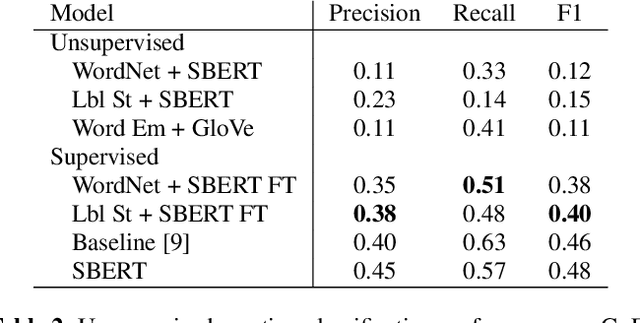
Emotion recognition from text is a challenging task due to diverse emotion taxonomies, lack of reliable labeled data in different domains, and highly subjective annotation standards. Few-shot and zero-shot techniques can generalize across unseen emotions by projecting the documents and emotion labels onto a shared embedding space. In this work, we explore the task of few-shot emotion recognition by transferring the knowledge gained from supervision on the GoEmotions Reddit dataset to the SemEval tweets corpus, using different emotion representation methods. The results show that knowledge transfer using external knowledge bases and fine-tuned encoders perform comparably as supervised baselines, requiring minimal supervision from the task dataset.