 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Emotion Embeddings to Transfer Knowledge Between Emotions, Languages, and Annotation Formats
Oct 31, 2022The need for emotional inference from text continues to diversify as more and more disciplines integrate emotions into their theories and applications. These needs include inferring different emotion types, handling multiple languages, and different annotation formats. A shared model between different configurations would enable the sharing of knowledge and a decrease in training costs, and would simplify the process of deploying emotion recognition models in novel environments. In this work, we study how we can build a single model that can transition between these different configurations by leveraging multilingual models and Demux, a transformer-based model whose input includes the emotions of interest, enabling us to dynamically change the emotions predicted by the model. Demux also produces emotion embeddings, and performing operations on them allows us to transition to clusters of emotions by pooling the embeddings of each cluster. We show that Demux can simultaneously transfer knowledge in a zero-shot manner to a new language, to a novel annotation format and to unseen emotions. Code is available at https://github.com/gchochla/Demux-MEmo .
Leveraging Label Correlations in a Multi-label Setting: A Case Study in Emotion
Oct 28, 2022


Detecting emotions expressed in text has become critical to a range of fields. In this work, we investigate ways to exploit label correlations in multi-label emotion recognition models to improve emotion detection. First, we develop two modeling approaches to the problem in order to capture word associations of the emotion words themselves, by either including the emotions in the input, or by leveraging Masked Language Modeling (MLM). Second, we integrate pairwise constraints of emotion representations as regularization terms alongside the classification loss of the models. We split these terms into two categories, local and global. The former dynamically change based on the gold labels, while the latter remain static during training. We demonstrate state-of-the-art performance across Spanish, English, and Arabic in SemEval 2018 Task 1 E-c using monolingual BERT-based models. On top of better performance, we also demonstrate improved robustness. Code is available at https://github.com/gchochla/Demux-MEmo.
Crypto Pump and Dump Detection via Deep Learning Techniques
May 10, 2022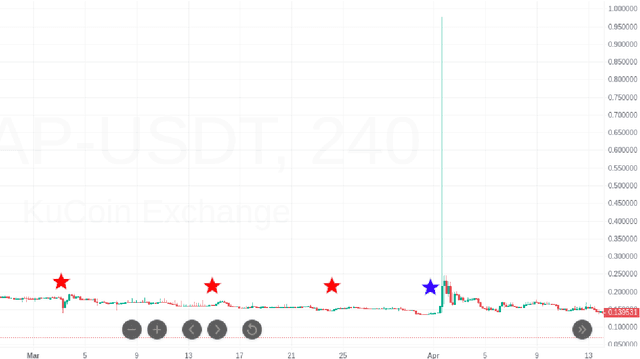
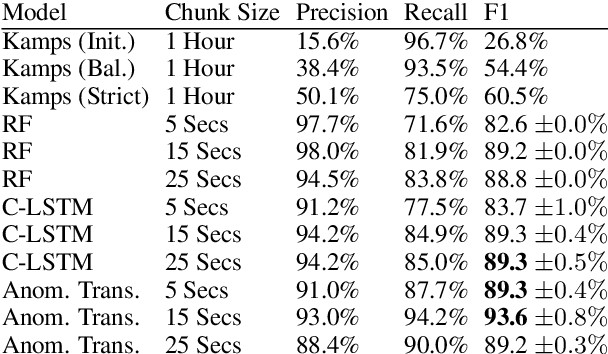
Despite the fact that cryptocurrencies themselves have experienced an astonishing rate of adoption over the last decade, cryptocurrency fraud detection is a heavily under-researched problem area. Of all fraudulent activity regarding cryptocurrencies, pump and dump schemes are some of the most common. Though some studies have been done on these kinds of scams in the stock market, the lack of labelled stock data and the volatility unique to the cryptocurrency space constrains the applicability of studies on the stock market toward this problem domain. Furthermore, the only work done in this space thus far has been either statistical in nature, or has been concerned with classical machine learning models such as random forest trees. We propose the novel application of two existing neural network architectures to this problem domain and show that deep learning solutions can significantly outperform all other existing pump and dump detection methods for cryptocurrencies.