 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUOD: Universal One-shot Detection of Anatomical Landmarks
Jun 14, 2023One-shot medical landmark detection gains much attention and achieves great success for its label-efficient training process. However, existing one-shot learning methods are highly specialized in a single domain and suffer domain preference heavily in the situation of multi-domain unlabeled data. Moreover, one-shot learning is not robust that it faces performance drop when annotating a sub-optimal image. To tackle these issues, we resort to developing a domain-adaptive one-shot landmark detection framework for handling multi-domain medical images, named Universal One-shot Detection (UOD). UOD consists of two stages and two corresponding universal models which are designed as combinations of domain-specific modules and domain-shared modules. In the first stage, a domain-adaptive convolution model is self-supervised learned to generate pseudo landmark labels. In the second stage, we design a domain-adaptive transformer to eliminate domain preference and build the global context for multi-domain data. Even though only one annotated sample from each domain is available for training, the domain-shared modules help UOD aggregate all one-shot samples to detect more robust and accurate landmarks. We investigated both qualitatively and quantitatively the proposed UOD on three widely-used public X-ray datasets in different anatomical domains (i.e., head, hand, chest) and obtained state-of-the-art performances in each domain.
Information-guided pixel augmentation for pixel-wise contrastive learning
Nov 14, 2022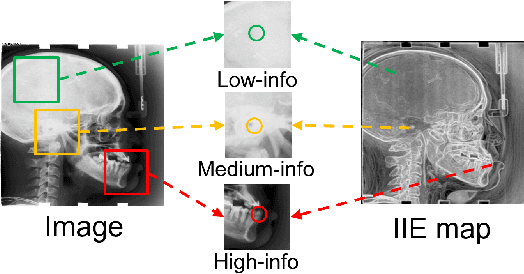
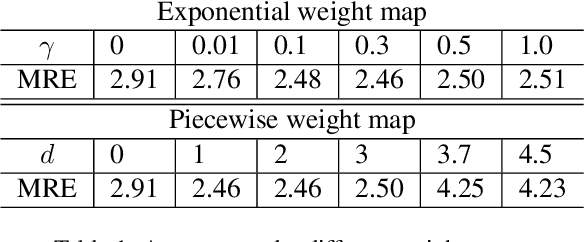
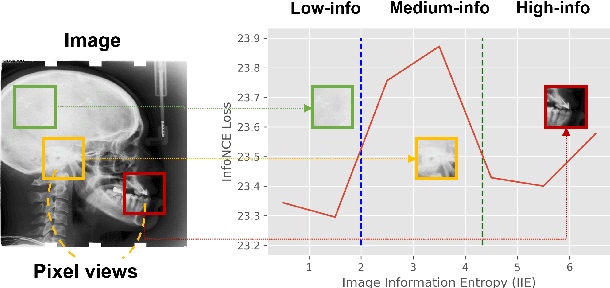

Contrastive learning (CL) is a form of self-supervised learning and has been widely used for various tasks. Different from widely studied instance-level contrastive learning, pixel-wise contrastive learning mainly helps with pixel-wise tasks such as medical landmark detection. The counterpart to an instance in instance-level CL is a pixel, along with its neighboring context, in pixel-wise CL. Aiming to build better feature representation, there is a vast literature about designing instance augmentation strategies for instance-level CL; but there is little similar work on pixel augmentation for pixel-wise CL with a pixel granularity. In this paper, we attempt to bridge this gap. We first classify a pixel into three categories, namely low-, medium-, and high-informative, based on the information quantity the pixel contains. Inspired by the ``InfoMin" principle, we then design separate augmentation strategies for each category in terms of augmentation intensity and sampling ratio. Extensive experiments validate that our information-guided pixel augmentation strategy succeeds in encoding more discriminative representations and surpassing other competitive approaches in unsupervised local feature matching. Furthermore, our pretrained model improves the performance of both one-shot and fully supervised models. To the best of our knowledge, we are the first to propose a pixel augmentation method with a pixel granularity for enhancing unsupervised pixel-wise contrastive learning.