 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-based surgical skill assessment using 3D convolutional neural networks
Mar 06, 2019
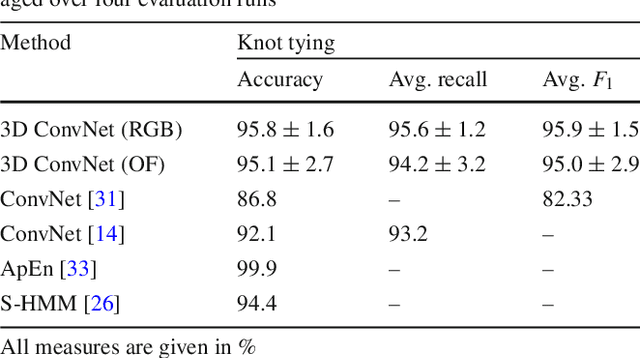


Purpose: A profound education of novice surgeons is crucial to ensure that surgical interventions are effective and safe. One important aspect is the teaching of technical skills for minimally invasive or robot-assisted procedures. This includes the objective and preferably automatic assessment of surgical skill. Recent studies presented good results for automatic, objective skill evaluation by collecting and analyzing motion data such as trajectories of surgical instruments. However, obtaining the motion data generally requires additional equipment for instrument tracking or the availability of a robotic surgery system to capture kinematic data. In contrast, we investigate a method for automatic, objective skill assessment that requires video data only. This has the advantage that video can be collected effortlessly during minimally invasive and robot-assisted training scenarios. Methods: Our method builds on recent advances in deep learning-based video classification. Specifically, we propose to use an inflated 3D ConvNet to classify snippets of optical flow extracted from surgical video. The network is extended into a Temporal Segment Network during training. Results: On the publicly available JIGSAWS dataset, our approach achieves high skill classification accuracies ranging from 95.1% to 100.0%. Conclusions: Our results demonstrate the feasibility of deep learning-based assessment of technical skill from surgical video. The 3D ConvNet is able to learn meaningful patterns directly from the data, alleviating the need for manual feature engineering. Further evaluation will require more annotated data for training and testing.
Prediction of laparoscopic procedure duration using unlabeled, multimodal sensor data
Nov 08, 2018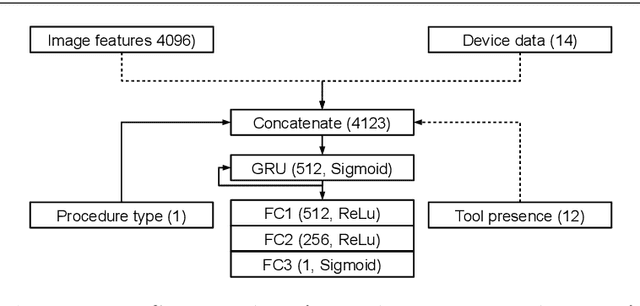
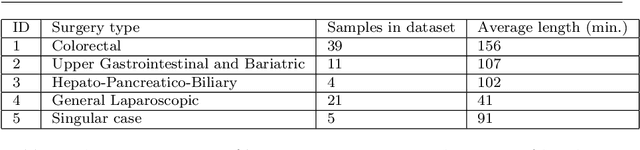
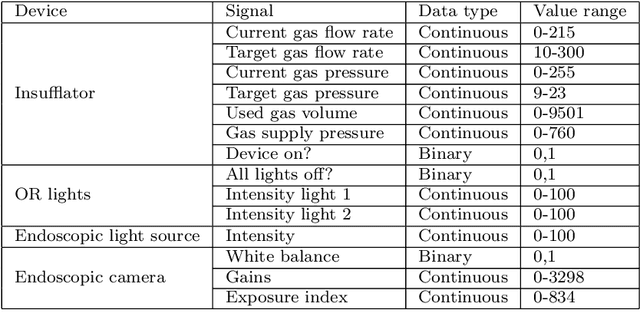
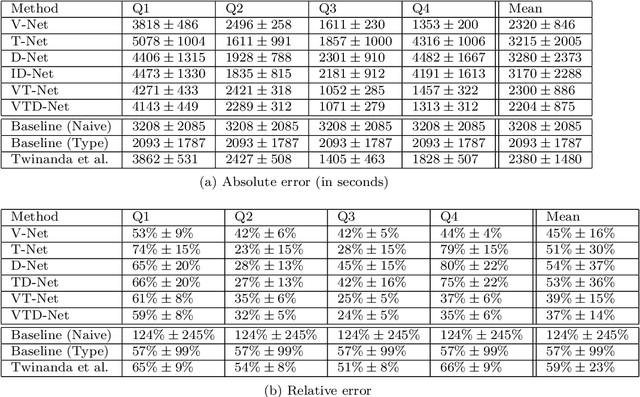
The course of surgical procedures is often unpredictable, making it difficult to estimate the duration of procedures beforehand. This uncertainty makes scheduling surgical procedures a difficult task. A context-aware method that analyses the workflow of an intervention online and automatically predicts the remaining duration would alleviate these problems. As basis for such an estimate, information regarding the current state of the intervention is a requirement. Today, the operating room contains a diverse range of sensors. During laparoscopic interventions, the endoscopic video stream is an ideal source of such information. Extracting quantitative information from the video is challenging though, due to its high dimensionality. Other surgical devices (e.g. insufflator, lights, etc.) provide data streams which are, in contrast to the video stream, more compact and easier to quantify. Though whether such streams offer sufficient information for estimating the duration of surgery is uncertain. In this paper, we propose and compare methods, based on convolutional neural networks, for continuously predicting the duration of laparoscopic interventions based on unlabeled data, such as from endoscopic image and surgical device streams. The methods are evaluated on 80 recorded laparoscopic interventions of various types, for which surgical device data and the endoscopic video streams are available. Here the combined method performs best with an overall average error of 37% and an average halftime error of approximately 28%.
Active Learning using Deep Bayesian Networks for Surgical Workflow Analysis
Nov 08, 2018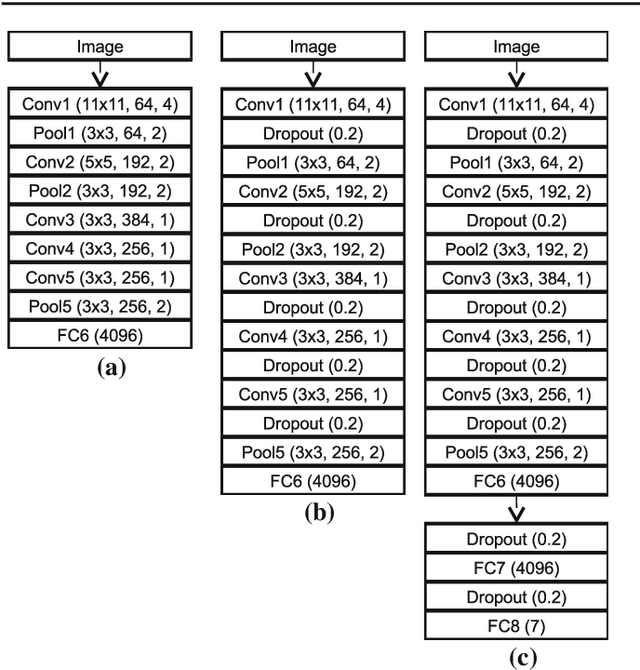

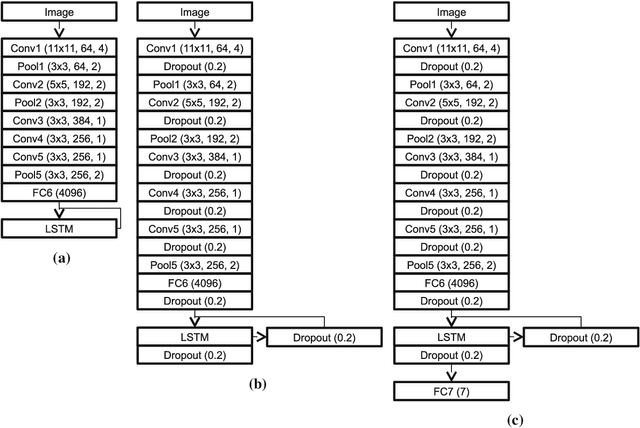
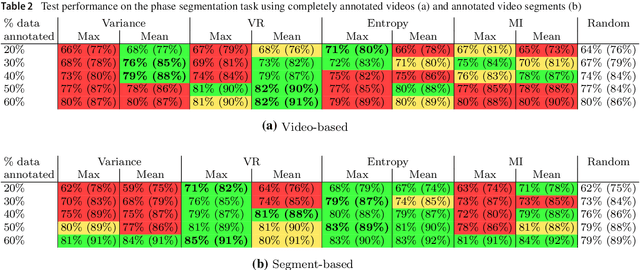
For many applications in the field of computer assisted surgery, such as providing the position of a tumor, specifying the most probable tool required next by the surgeon or determining the remaining duration of surgery, methods for surgical workflow analysis are a prerequisite. Often machine learning based approaches serve as basis for surgical workflow analysis. In general machine learning algorithms, such as convolutional neural networks (CNN), require large amounts of labeled data. While data is often available in abundance, many tasks in surgical workflow analysis need data annotated by domain experts, making it difficult to obtain a sufficient amount of annotations. The aim of using active learning to train a machine learning model is to reduce the annotation effort. Active learning methods determine which unlabeled data points would provide the most information according to some metric, such as prediction uncertainty. Experts will then be asked to only annotate these data points. The model is then retrained with the new data and used to select further data for annotation. Recently, active learning has been applied to CNN by means of Deep Bayesian Networks (DBN). These networks make it possible to assign uncertainties to predictions. In this paper, we present a DBN-based active learning approach adapted for image-based surgical workflow analysis task. Furthermore, by using a recurrent architecture, we extend this network to video-based surgical workflow analysis. We evaluate these approaches on the Cholec80 dataset by performing instrument presence detection and surgical phase segmentation. Here we are able to show that using a DBN-based active learning approach for selecting what data points to annotate next outperforms a baseline based on randomly selecting data points.
Temporal coherence-based self-supervised learning for laparoscopic workflow analysis
Sep 07, 2018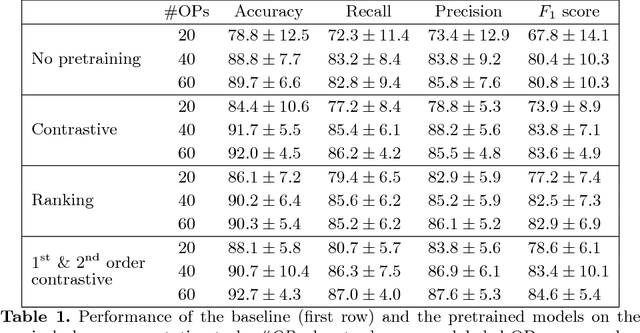
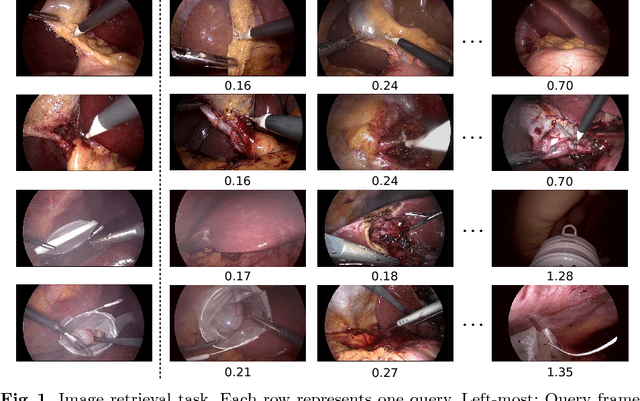
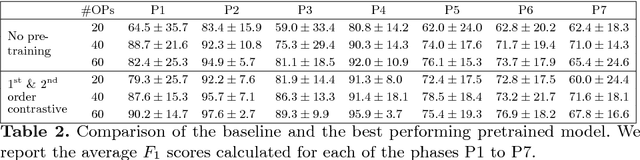
In order to provide the right type of assistance at the right time, computer-assisted surgery systems need context awareness. To achieve this, methods for surgical workflow analysis are crucial. Currently, convolutional neural networks provide the best performance for video-based workflow analysis tasks. For training such networks, large amounts of annotated data are necessary. However, collecting a sufficient amount of data is often costly, time-consuming, and not always feasible. In this paper, we address this problem by presenting and comparing different approaches for self-supervised pretraining of neural networks on unlabeled laparoscopic videos using temporal coherence. We evaluate our pretrained networks on Cholec80, a publicly available dataset for surgical phase segmentation, on which a maximum F1 score of 84.6 was reached. Furthermore, we were able to achieve an increase of the F1 score of up to 10 points when compared to a non-pretrained neural network.
* Accepted at the Workshop on Context-Aware Operating Theaters (OR 2.0), a MICCAI satellite event