 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaPhysiCa: OOD Robustness in Physics-informed Machine Learning
Mar 06, 2023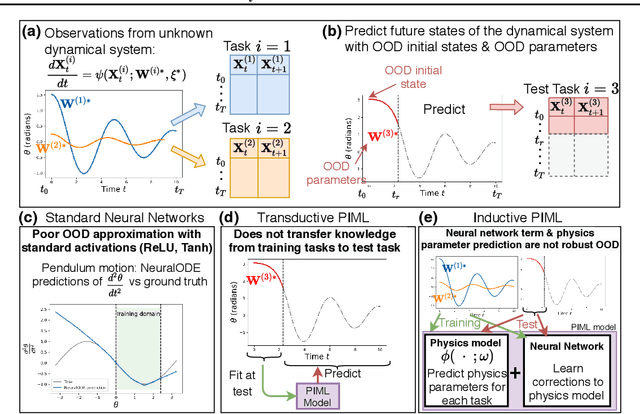

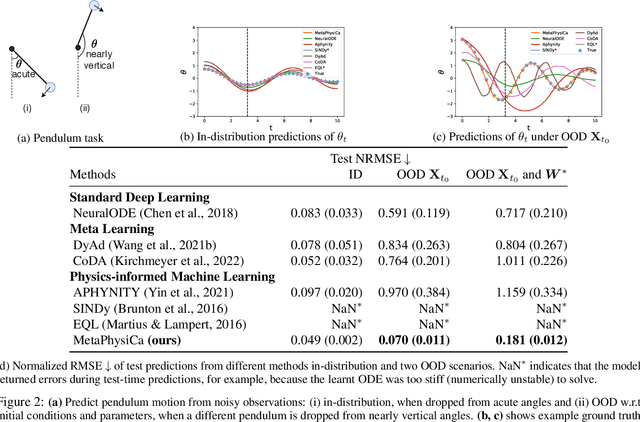

A fundamental challenge in physics-informed machine learning (PIML) is the design of robust PIML methods for out-of-distribution (OOD) forecasting tasks. These OOD tasks require learning-to-learn from observations of the same (ODE) dynamical system with different unknown ODE parameters, and demand accurate forecasts even under out-of-support initial conditions and out-of-support ODE parameters. In this work we propose a solution for such tasks, which we define as a meta-learning procedure for causal structure discovery (including invariant risk minimization). Using three different OOD tasks, we empirically observe that the proposed approach significantly outperforms existing state-of-the-art PIML and deep learning methods.
Bias Challenges in Counterfactual Data Augmentation
Sep 13, 2022

Deep learning models tend not to be out-of-distribution robust primarily due to their reliance on spurious features to solve the task. Counterfactual data augmentations provide a general way of (approximately) achieving representations that are counterfactual-invariant to spurious features, a requirement for out-of-distribution (OOD) robustness. In this work, we show that counterfactual data augmentations may not achieve the desired counterfactual-invariance if the augmentation is performed by a context-guessing machine, an abstract machine that guesses the most-likely context of a given input. We theoretically analyze the invariance imposed by such counterfactual data augmentations and describe an exemplar NLP task where counterfactual data augmentation by a context-guessing machine does not lead to robust OOD classifiers.
Neural Networks for Learning Counterfactual G-Invariances from Single Environments
Apr 20, 2021

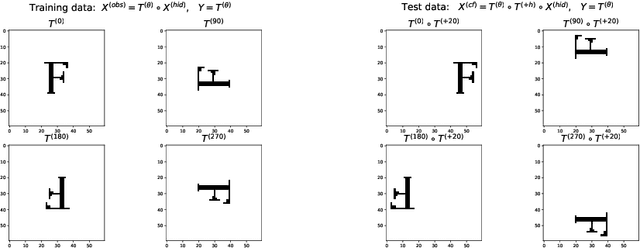

Despite -- or maybe because of -- their astonishing capacity to fit data, neural networks are believed to have difficulties extrapolating beyond training data distribution. This work shows that, for extrapolations based on finite transformation groups, a model's inability to extrapolate is unrelated to its capacity. Rather, the shortcoming is inherited from a learning hypothesis: Examples not explicitly observed with infinitely many training examples have underspecified outcomes in the learner's model. In order to endow neural networks with the ability to extrapolate over group transformations, we introduce a learning framework counterfactually-guided by the learning hypothesis that any group invariance to (known) transformation groups is mandatory even without evidence, unless the learner deems it inconsistent with the training data. Unlike existing invariance-driven methods for (counterfactual) extrapolations, this framework allows extrapolations from a single environment. Finally, we introduce sequence and image extrapolation tasks that validate our framework and showcase the shortcomings of traditional approaches.
Deceptive Deletions for Protecting Withdrawn Posts on Social Platforms
May 28, 2020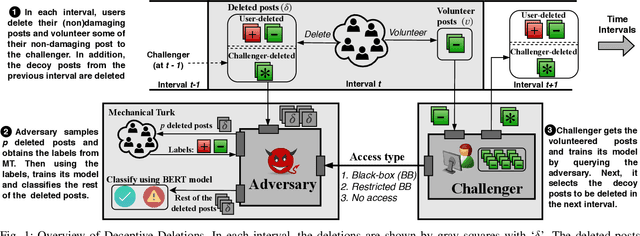
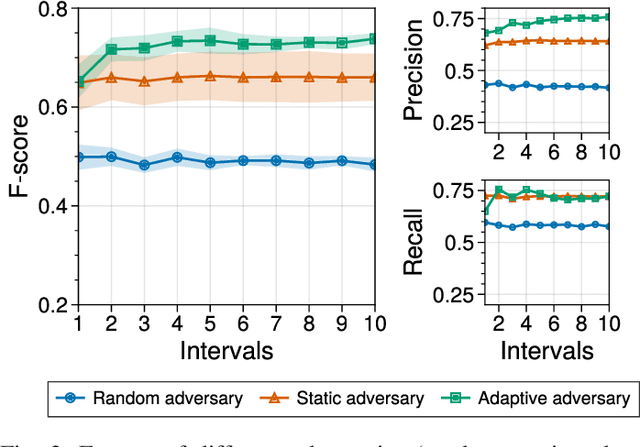
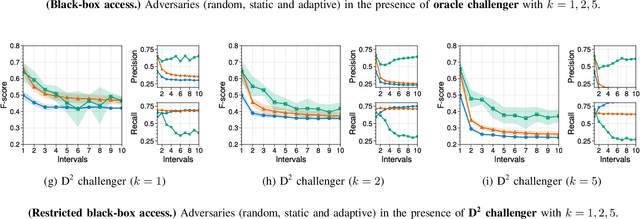
Over-sharing poorly-worded thoughts and personal information is prevalent on online social platforms. In many of these cases, users regret posting such content. To retrospectively rectify these errors in users' sharing decisions, most platforms offer (deletion) mechanisms to withdraw the content, and social media users often utilize them. Ironically and perhaps unfortunately, these deletions make users more susceptible to privacy violations by malicious actors who specifically hunt post deletions at large scale. The reason for such hunting is simple: deleting a post acts as a powerful signal that the post might be damaging to its owner. Today, multiple archival services are already scanning social media for these deleted posts. Moreover, as we demonstrate in this work, powerful machine learning models can detect damaging deletions at scale. Towards restraining such a global adversary against users' right to be forgotten, we introduce Deceptive Deletion, a decoy mechanism that minimizes the adversarial advantage. Our mechanism injects decoy deletions, hence creating a two-player minmax game between an adversary that seeks to classify damaging content among the deleted posts and a challenger that employs decoy deletions to masquerade real damaging deletions. We formalize the Deceptive Game between the two players, determine conditions under which either the adversary or the challenger provably wins the game, and discuss the scenarios in-between these two extremes. We apply the Deceptive Deletion mechanism to a real-world task on Twitter: hiding damaging tweet deletions. We show that a powerful global adversary can be beaten by a powerful challenger, raising the bar significantly and giving a glimmer of hope in the ability to be really forgotten on social platforms.
Deep Lifetime Clustering
Oct 02, 2019The goal of lifetime clustering is to develop an inductive model that maps subjects into $K$ clusters according to their underlying (unobserved) lifetime distribution. We introduce a neural-network based lifetime clustering model that can find cluster assignments by directly maximizing the divergence between the empirical lifetime distributions of the clusters. Accordingly, we define a novel clustering loss function over the lifetime distributions (of entire clusters) based on a tight upper bound of the two-sample Kuiper test p-value. The resultant model is robust to the modeling issues associated with the unobservability of termination signals, and does not assume proportional hazards. Our results in real and synthetic datasets show significantly better lifetime clusters (as evaluated by C-index, Brier Score, Logrank score and adjusted Rand index) as compared to competing approaches.