 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-The-Shelf Image-to-Image Models Are All You Need To Defeat Image Protection Schemes
Feb 25, 2026Advances in Generative AI (GenAI) have led to the development of various protection strategies to prevent the unauthorized use of images. These methods rely on adding imperceptible protective perturbations to images to thwart misuse such as style mimicry or deepfake manipulations. Although previous attacks on these protections required specialized, purpose-built methods, we demonstrate that this is no longer necessary. We show that off-the-shelf image-to-image GenAI models can be repurposed as generic ``denoisers" using a simple text prompt, effectively removing a wide range of protective perturbations. Across 8 case studies spanning 6 diverse protection schemes, our general-purpose attack not only circumvents these defenses but also outperforms existing specialized attacks while preserving the image's utility for the adversary. Our findings reveal a critical and widespread vulnerability in the current landscape of image protection, indicating that many schemes provide a false sense of security. We stress the urgent need to develop robust defenses and establish that any future protection mechanism must be benchmarked against attacks from off-the-shelf GenAI models. Code is available in this repository: https://github.com/mlsecviswanath/img2imgdenoiser
Evaluation of LLMs in Medical Text Summarization: The Role of Vocabulary Adaptation in High OOV Settings
May 27, 2025



Large Language Models (LLMs) recently achieved great success in medical text summarization by simply using in-context learning. However, these recent efforts do not perform fine-grained evaluations under difficult settings where LLMs might fail. They typically report performance scores over the entire dataset. Through our benchmarking study, we show that LLMs show a significant performance drop for data points with high concentration of out-of-vocabulary (OOV) words or with high novelty. Vocabulary adaptation is an intuitive solution to this vocabulary mismatch issue where the LLM vocabulary gets updated with certain expert domain (here, medical) words or subwords. An interesting finding from our study is that Llama-3.1, even with a vocabulary size of around 128K tokens, still faces over-fragmentation issue with medical words. To that end, we show vocabulary adaptation helps improve the LLM summarization performance even in difficult settings. Through extensive experimentation of multiple vocabulary adaptation strategies, two continual pretraining strategies, and three benchmark medical summarization datasets, we gain valuable insights into the role of vocabulary adaptation strategies for customizing LLMs to the medical domain. We also performed a human evaluation study with medical experts where they found that vocabulary adaptation results in more relevant and faithful summaries. Our codebase is made publicly available at https://github.com/gb-kgp/LLM-MedicalSummarization-Benchmark.
Adaptive BPE Tokenization for Enhanced Vocabulary Adaptation in Finetuning Pretrained Language Models
Oct 04, 2024



In this work, we show a fundamental limitation in vocabulary adaptation approaches that use Byte-Pair Encoding (BPE) tokenization scheme for fine-tuning pretrained language models (PLMs) to expert domains. Current approaches trivially append the target domain-specific vocabulary at the end of the PLM vocabulary. This approach leads to a lower priority score and causes sub-optimal tokenization in BPE that iteratively uses merge rules to tokenize a given text. To mitigate this issue, we propose AdaptBPE where the BPE tokenization initialization phase is modified to first perform the longest string matching on the added (target) vocabulary before tokenizing at the character level. We perform an extensive evaluation of AdaptBPE versus the standard BPE over various classification and summarization tasks; AdaptBPE improves by 3.57% (in terms of accuracy) and 1.87% (in terms of Rouge-L), respectively. AdaptBPE for MEDVOC works particularly well when reference summaries have high OOV concentration or are longer in length. We also conduct a human evaluation, revealing that AdaptBPE generates more relevant and more faithful summaries as compared to MEDVOC. We make our codebase publicly available at https://github.com/gb-kgp/adaptbpe.
MEDVOC: Vocabulary Adaptation for Fine-tuning Pre-trained Language Models on Medical Text Summarization
May 07, 2024
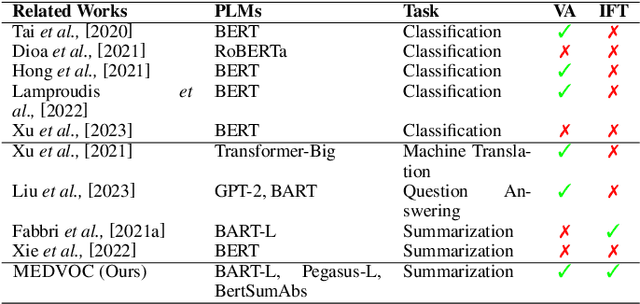
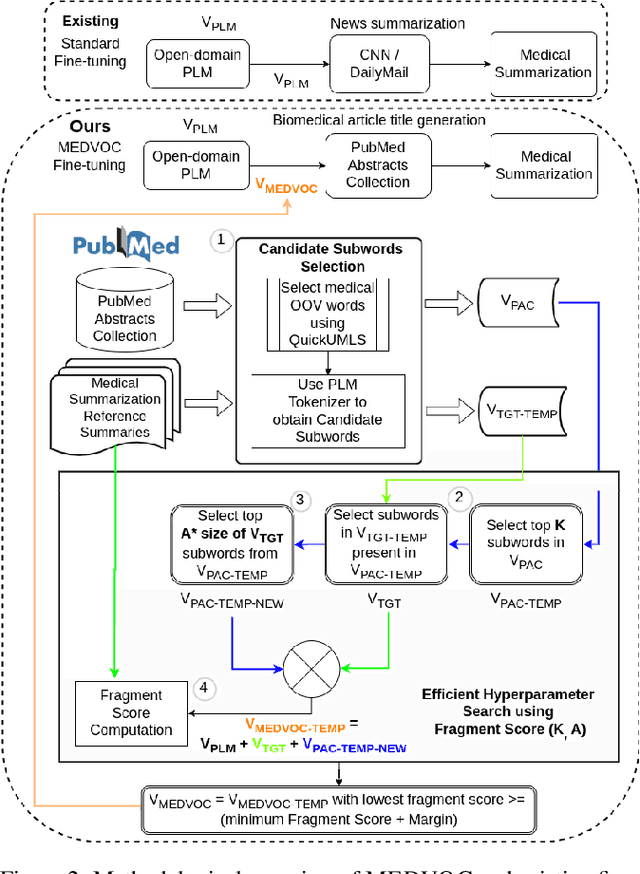
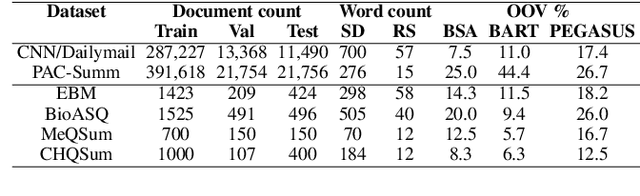
This work presents a dynamic vocabulary adaptation strategy, MEDVOC, for fine-tuning pre-trained language models (PLMs) like BertSumAbs, BART, and PEGASUS for improved medical text summarization. In contrast to existing domain adaptation approaches in summarization, MEDVOC treats vocabulary as an optimizable parameter and optimizes the PLM vocabulary based on fragment score conditioned only on the downstream task's reference summaries. Unlike previous works on vocabulary adaptation (limited only to classification tasks), optimizing vocabulary based on summarization tasks requires an extremely costly intermediate fine-tuning step on large summarization datasets. To that end, our novel fragment score-based hyperparameter search very significantly reduces this fine-tuning time -- from 450 days to less than 2 days on average. Furthermore, while previous works on vocabulary adaptation are often primarily tied to single PLMs, MEDVOC is designed to be deployable across multiple PLMs (with varying model vocabulary sizes, pre-training objectives, and model sizes) -- bridging the limited vocabulary overlap between the biomedical literature domain and PLMs. MEDVOC outperforms baselines by 15.74% in terms of Rouge-L in zero-shot setting and shows gains of 17.29% in high Out-Of-Vocabulary (OOV) concentrations. Our human evaluation shows MEDVOC generates more faithful medical summaries (88% compared to 59% in baselines). We make the codebase publicly available at https://github.com/gb-kgp/MEDVOC.
"Dummy Grandpa, do you know anything?": Identifying and Characterizing Ad hominem Fallacy Usage in the Wild
Sep 05, 2022
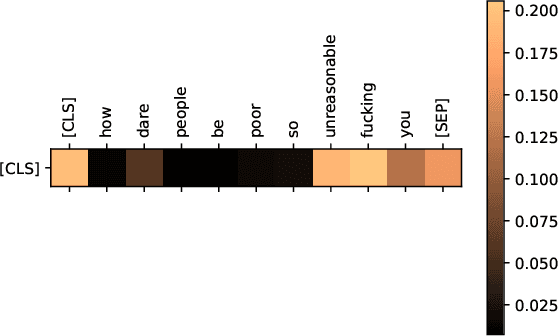
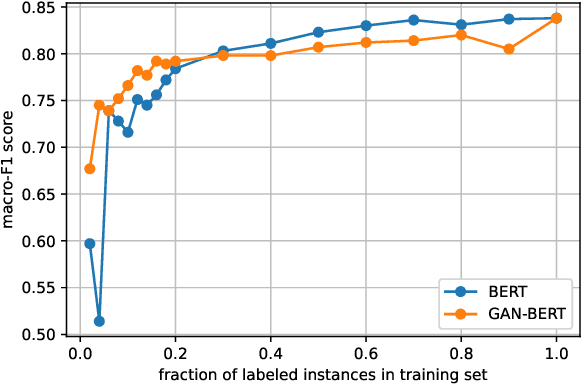

Today, participating in discussions on online forums is extremely commonplace and these discussions have started rendering a strong influence on the overall opinion of online users. Naturally, twisting the flow of the argument can have a strong impact on the minds of naive users, which in the long run might have socio-political ramifications, for example, winning an election or spreading targeted misinformation. Thus, these platforms are potentially highly vulnerable to malicious players who might act individually or as a cohort to breed fallacious arguments with a motive to sway public opinion. Ad hominem arguments are one of the most effective forms of such fallacies. Although a simple fallacy, it is effective enough to sway public debates in offline world and can be used as a precursor to shutting down the voice of opposition by slander. In this work, we take a first step in shedding light on the usage of ad hominem fallacies in the wild. First, we build a powerful ad hominem detector with high accuracy (F1 more than 83%, showing a significant improvement over prior work), even for datasets for which annotated instances constitute a very small fraction. We then used our detector on 265k arguments collected from the online debate forum - CreateDebate. Our crowdsourced surveys validate our in-the-wild predictions on CreateDebate data (94% match with manual annotation). Our analysis revealed that a surprising 31.23% of CreateDebate content contains ad hominem fallacy, and a cohort of highly active users post significantly more ad hominem to suppress opposing views. Then, our temporal analysis revealed that ad hominem argument usage increased significantly since the 2016 US Presidential election, not only for topics like Politics, but also for Science and Law. We conclude by discussing important implications of our work to detect and defend against ad hominem fallacies.
Deceptive Deletions for Protecting Withdrawn Posts on Social Platforms
May 28, 2020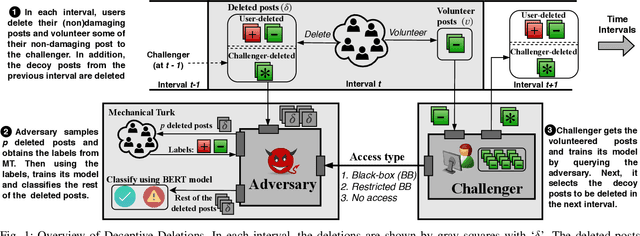
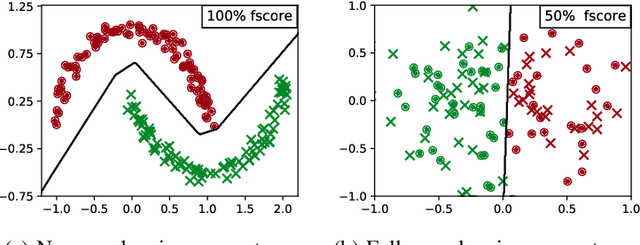
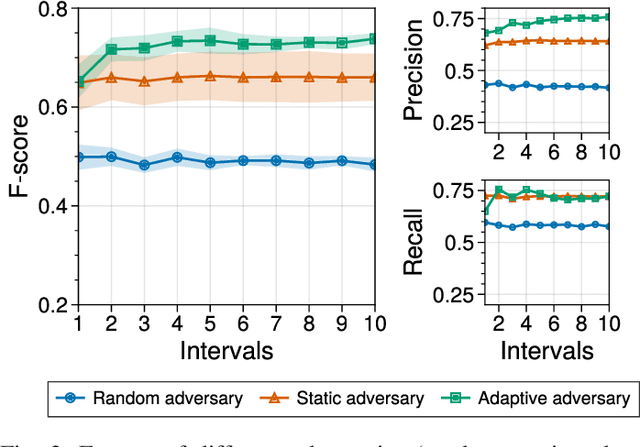
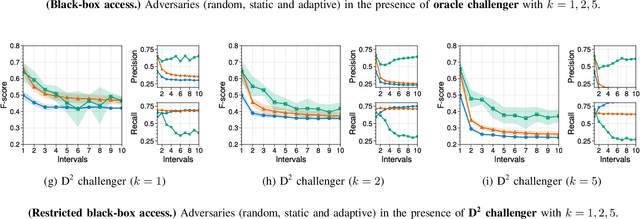
Over-sharing poorly-worded thoughts and personal information is prevalent on online social platforms. In many of these cases, users regret posting such content. To retrospectively rectify these errors in users' sharing decisions, most platforms offer (deletion) mechanisms to withdraw the content, and social media users often utilize them. Ironically and perhaps unfortunately, these deletions make users more susceptible to privacy violations by malicious actors who specifically hunt post deletions at large scale. The reason for such hunting is simple: deleting a post acts as a powerful signal that the post might be damaging to its owner. Today, multiple archival services are already scanning social media for these deleted posts. Moreover, as we demonstrate in this work, powerful machine learning models can detect damaging deletions at scale. Towards restraining such a global adversary against users' right to be forgotten, we introduce Deceptive Deletion, a decoy mechanism that minimizes the adversarial advantage. Our mechanism injects decoy deletions, hence creating a two-player minmax game between an adversary that seeks to classify damaging content among the deleted posts and a challenger that employs decoy deletions to masquerade real damaging deletions. We formalize the Deceptive Game between the two players, determine conditions under which either the adversary or the challenger provably wins the game, and discuss the scenarios in-between these two extremes. We apply the Deceptive Deletion mechanism to a real-world task on Twitter: hiding damaging tweet deletions. We show that a powerful global adversary can be beaten by a powerful challenger, raising the bar significantly and giving a glimmer of hope in the ability to be really forgotten on social platforms.