 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDVOC: Vocabulary Adaptation for Fine-tuning Pre-trained Language Models on Medical Text Summarization
Paper and Code

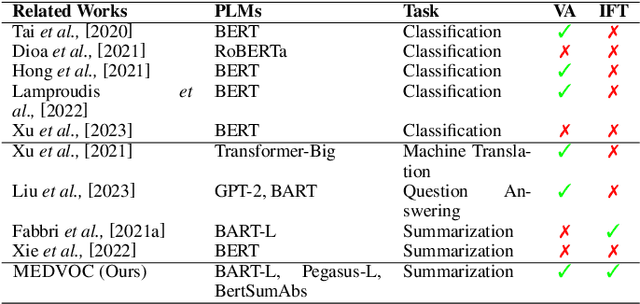
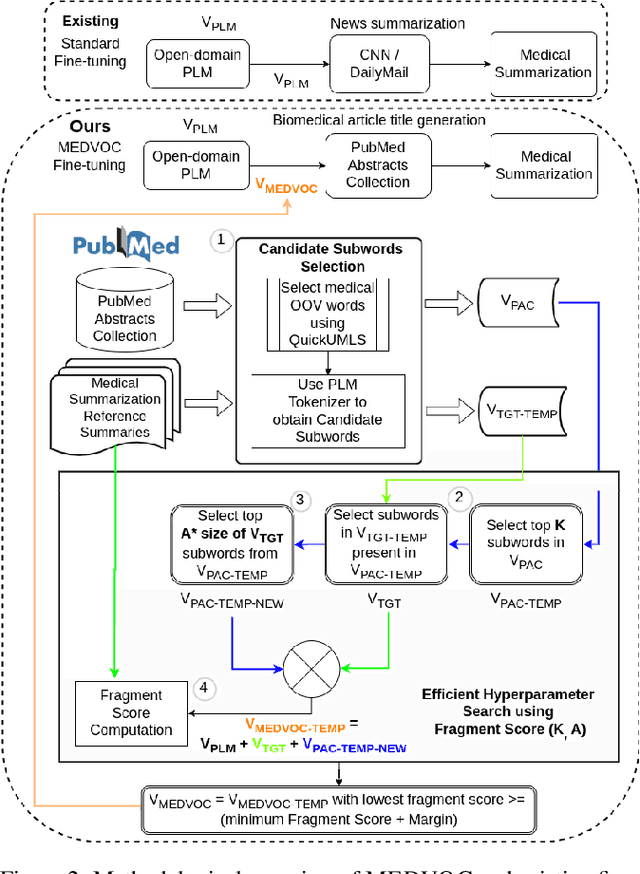
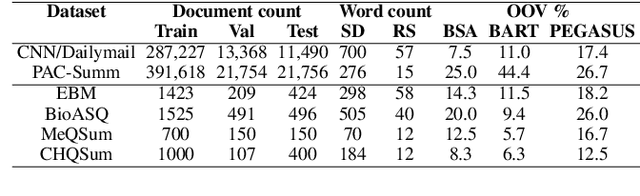
This work presents a dynamic vocabulary adaptation strategy, MEDVOC, for fine-tuning pre-trained language models (PLMs) like BertSumAbs, BART, and PEGASUS for improved medical text summarization. In contrast to existing domain adaptation approaches in summarization, MEDVOC treats vocabulary as an optimizable parameter and optimizes the PLM vocabulary based on fragment score conditioned only on the downstream task's reference summaries. Unlike previous works on vocabulary adaptation (limited only to classification tasks), optimizing vocabulary based on summarization tasks requires an extremely costly intermediate fine-tuning step on large summarization datasets. To that end, our novel fragment score-based hyperparameter search very significantly reduces this fine-tuning time -- from 450 days to less than 2 days on average. Furthermore, while previous works on vocabulary adaptation are often primarily tied to single PLMs, MEDVOC is designed to be deployable across multiple PLMs (with varying model vocabulary sizes, pre-training objectives, and model sizes) -- bridging the limited vocabulary overlap between the biomedical literature domain and PLMs. MEDVOC outperforms baselines by 15.74% in terms of Rouge-L in zero-shot setting and shows gains of 17.29% in high Out-Of-Vocabulary (OOV) concentrations. Our human evaluation shows MEDVOC generates more faithful medical summaries (88% compared to 59% in baselines). We make the codebase publicly available at https://github.com/gb-kgp/MEDVOC.