 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparable study: Intrinsic difficulties of practical plant diagnosis from wide-angle images
Nov 22, 2019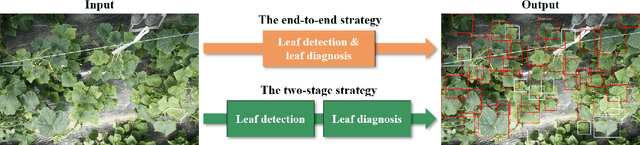



Practical automated detection and diagnosis of plant disease from wide-angle images (i.e. in-field images containing multiple leaves using a fixed-position camera) is a very important application for large-scale farm management, in view of the need to ensure global food security. However, developing automated systems for disease diagnosis is often difficult, because labeling a reliable wide-angle disease dataset from actual field images is very laborious. In addition, the potential similarities between the training and test data lead to a serious problem of model overfitting. In this paper, we investigate changes in performance when applying disease diagnosis systems to different scenarios involving wide-angle cucumber test data captured on real farms, and propose an effective diagnostic strategy. We show that leading object recognition techniques such as SSD and Faster R-CNN achieve excellent end-to-end disease diagnostic performance only for a test dataset that is collected from the same population as the training dataset (with F1-score of 81.5% - 84.1% for diagnosed cases of disease), but their performance markedly deteriorates for a completely different test dataset (with F1-score of 4.4 - 6.2%). In contrast, our proposed two-stage systems using independent leaf detection and leaf diagnosis stages attain a promising disease diagnostic performance that is more than six times higher than end-to-end systems (with F1-score of 33.4 - 38.9%) on an unseen target dataset. We also confirm the efficiency of our proposal based on visual assessment, concluding that a two-stage model is a suitable and reasonable choice for practical applications.
End-to-End Text Classification via Image-based Embedding using Character-level Networks
Oct 10, 2018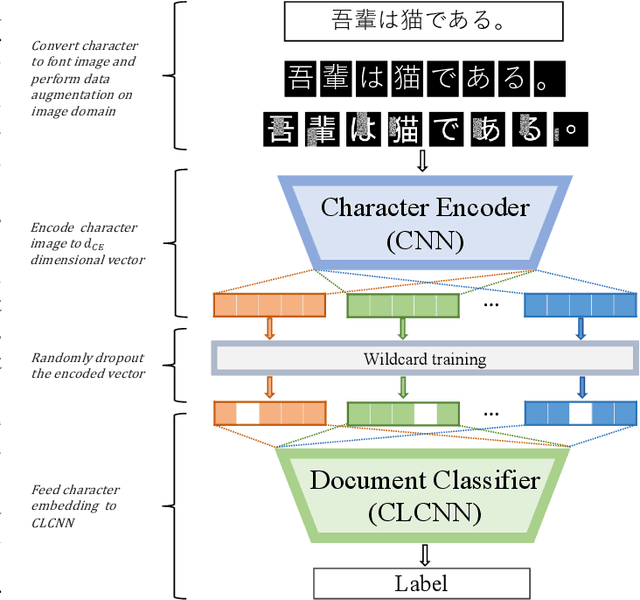


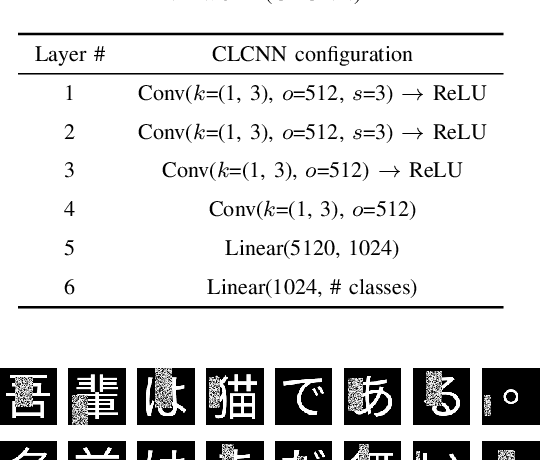
For analysing and/or understanding languages having no word boundaries based on morphological analysis such as Japanese, Chinese, and Thai, it is desirable to perform appropriate word segmentation before word embeddings. But it is inherently difficult in these languages. In recent years, various language models based on deep learning have made remarkable progress, and some of these methodologies utilizing character-level features have successfully avoided such a difficult problem. However, when a model is fed character-level features of the above languages, it often causes overfitting due to a large number of character types. In this paper, we propose a CE-CLCNN, character-level convolutional neural networks using a character encoder to tackle these problems. The proposed CE-CLCNN is an end-to-end learning model and has an image-based character encoder, i.e. the CE-CLCNN handles each character in the target document as an image. Through various experiments, we found and confirmed that our CE-CLCNN captured closely embedded features for visually and semantically similar characters and achieves state-of-the-art results on several open document classification tasks. In this paper we report the performance of our CE-CLCNN with the Wikipedia title estimation task and analyse the internal behaviour.