 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Text Classification via Image-based Embedding using Character-level Networks
Paper and Code
Oct 10, 2018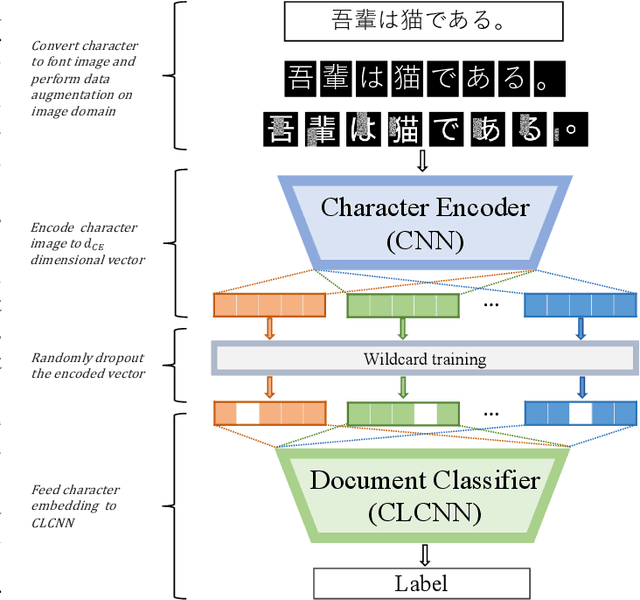


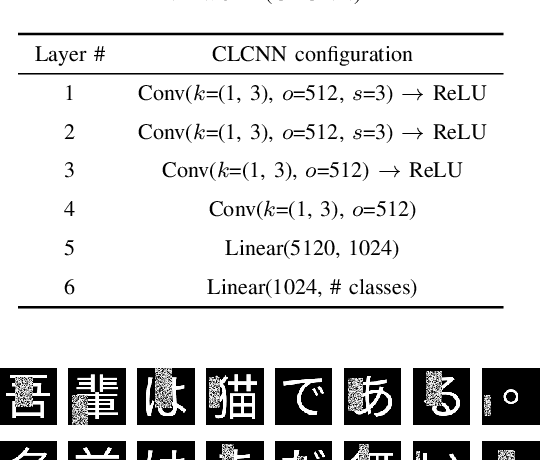
For analysing and/or understanding languages having no word boundaries based on morphological analysis such as Japanese, Chinese, and Thai, it is desirable to perform appropriate word segmentation before word embeddings. But it is inherently difficult in these languages. In recent years, various language models based on deep learning have made remarkable progress, and some of these methodologies utilizing character-level features have successfully avoided such a difficult problem. However, when a model is fed character-level features of the above languages, it often causes overfitting due to a large number of character types. In this paper, we propose a CE-CLCNN, character-level convolutional neural networks using a character encoder to tackle these problems. The proposed CE-CLCNN is an end-to-end learning model and has an image-based character encoder, i.e. the CE-CLCNN handles each character in the target document as an image. Through various experiments, we found and confirmed that our CE-CLCNN captured closely embedded features for visually and semantically similar characters and achieves state-of-the-art results on several open document classification tasks. In this paper we report the performance of our CE-CLCNN with the Wikipedia title estimation task and analyse the internal behaviour.