 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Side Information in Probabilistic Matrix Factorization with Gaussian Processes
Aug 09, 2014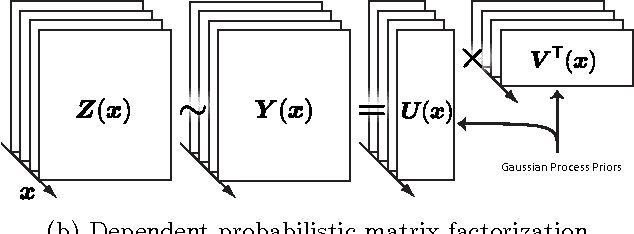
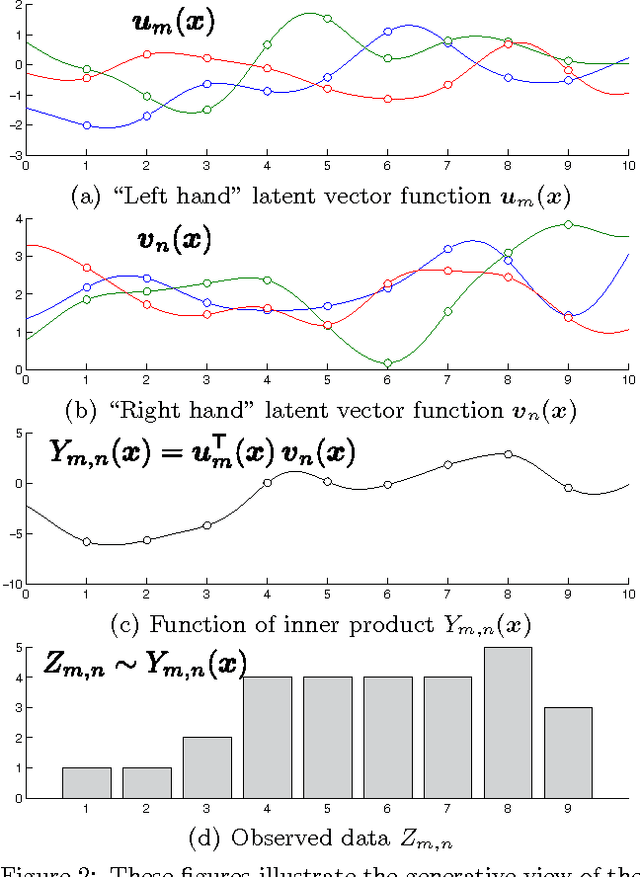
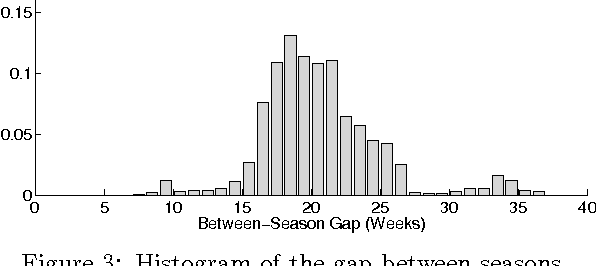

Probabilistic matrix factorization (PMF) is a powerful method for modeling data associ- ated with pairwise relationships, Finding use in collaborative Filtering, computational bi- ology, and document analysis, among other areas. In many domains, there are additional covariates that can assist in prediction. For example, when modeling movie ratings, we might know when the rating occurred, where the user lives, or what actors appear in the movie. It is difficult, however, to incorporate this side information into the PMF model. We propose a framework for incorporating side information by coupling together multi- ple PMF problems via Gaussian process priors. We replace scalar latent features with func- tions that vary over the covariate space. The GP priors on these functions require them to vary smoothly and share information. We apply this new method to predict the scores of professional basketball games, where side information about the venue and date of the game are relevant for the outcome.
Freeze-Thaw Bayesian Optimization
Jun 16, 2014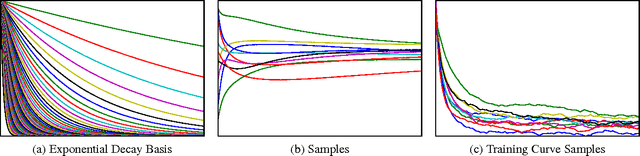
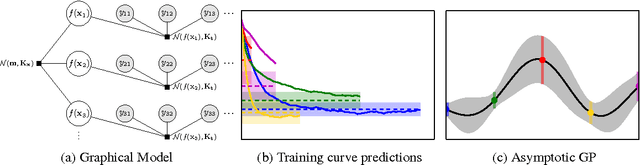
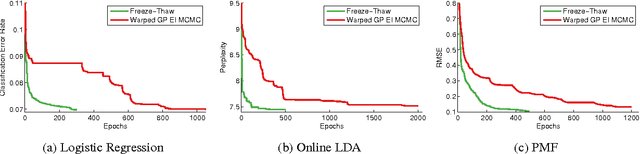
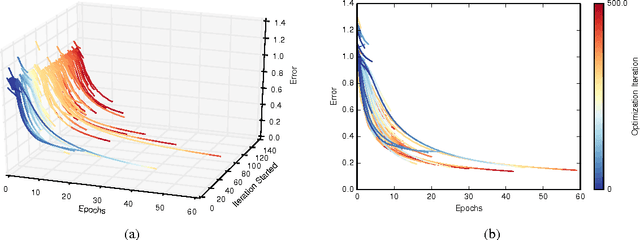
In this paper we develop a dynamic form of Bayesian optimization for machine learning models with the goal of rapidly finding good hyperparameter settings. Our method uses the partial information gained during the training of a machine learning model in order to decide whether to pause training and start a new model, or resume the training of a previously-considered model. We specifically tailor our method to machine learning problems by developing a novel positive-definite covariance kernel to capture a variety of training curves. Furthermore, we develop a Gaussian process prior that scales gracefully with additional temporal observations. Finally, we provide an information-theoretic framework to automate the decision process. Experiments on several common machine learning models show that our approach is extremely effective in practice.
Gaussian Process Kernels for Pattern Discovery and Extrapolation
Dec 31, 2013
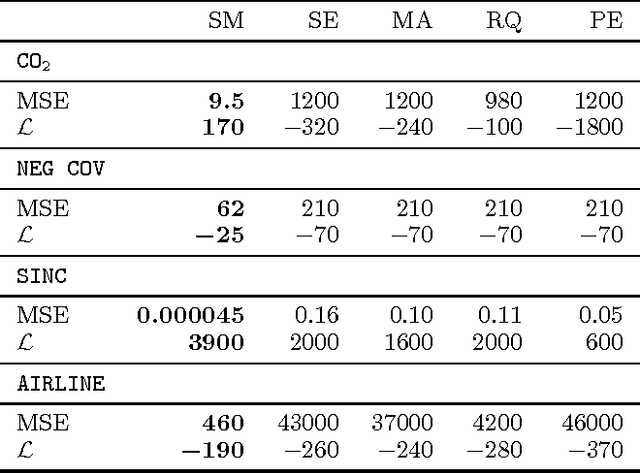
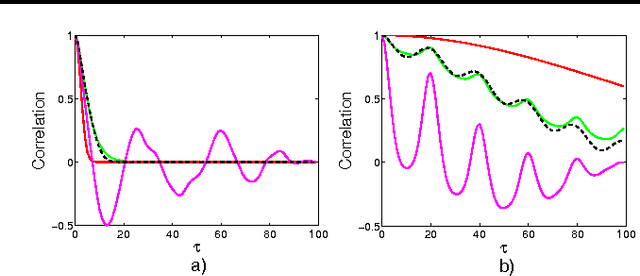
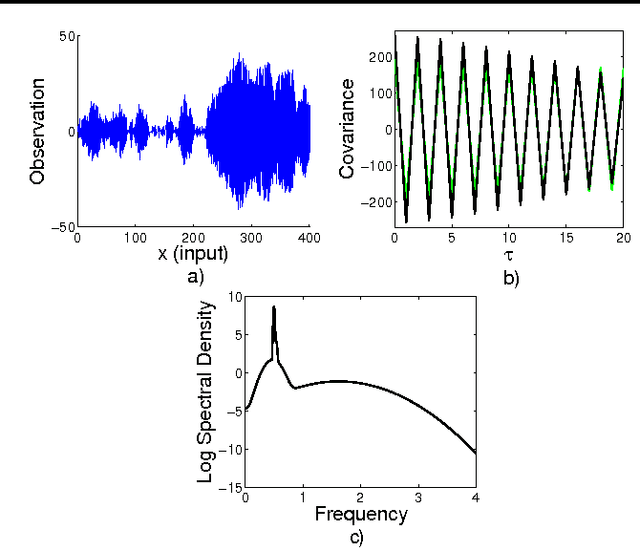
Gaussian processes are rich distributions over functions, which provide a Bayesian nonparametric approach to smoothing and interpolation. We introduce simple closed form kernels that can be used with Gaussian processes to discover patterns and enable extrapolation. These kernels are derived by modelling a spectral density -- the Fourier transform of a kernel -- with a Gaussian mixture. The proposed kernels support a broad class of stationary covariances, but Gaussian process inference remains simple and analytic. We demonstrate the proposed kernels by discovering patterns and performing long range extrapolation on synthetic examples, as well as atmospheric CO2 trends and airline passenger data. We also show that we can reconstruct standard covariances within our framework.
* 10 pages, 5 figures, 1 table. Minor edits and titled changed from "Gaussian Process Covariance Kernels for Pattern Discovery and Extrapolation" to "Gaussian Process Kernels for Pattern Discovery and Extrapolation". Appears at the International Conference on Machine Learning (ICML), JMLR W&CP 28(3):1067-1075, 2013
High-Dimensional Probability Estimation with Deep Density Models
Feb 20, 2013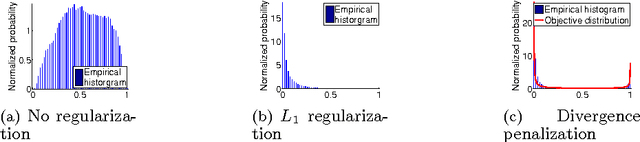

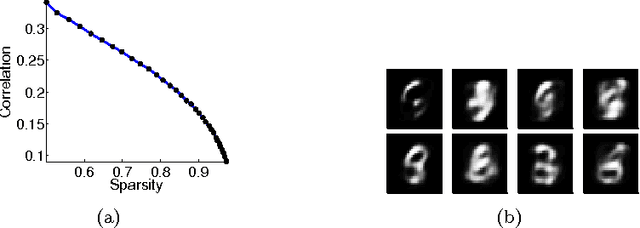

One of the fundamental problems in machine learning is the estimation of a probability distribution from data. Many techniques have been proposed to study the structure of data, most often building around the assumption that observations lie on a lower-dimensional manifold of high probability. It has been more difficult, however, to exploit this insight to build explicit, tractable density models for high-dimensional data. In this paper, we introduce the deep density model (DDM), a new approach to density estimation. We exploit insights from deep learning to construct a bijective map to a representation space, under which the transformation of the distribution of the data is approximately factorized and has identical and known marginal densities. The simplicity of the latent distribution under the model allows us to feasibly explore it, and the invertibility of the map to characterize contraction of measure across it. This enables us to compute normalized densities for out-of-sample data. This combination of tractability and flexibility allows us to tackle a variety of probabilistic tasks on high-dimensional datasets, including: rapid computation of normalized densities at test-time without evaluating a partition function; generation of samples without MCMC; and characterization of the joint entropy of the data.
Fast Exact Inference for Recursive Cardinality Models
Oct 16, 2012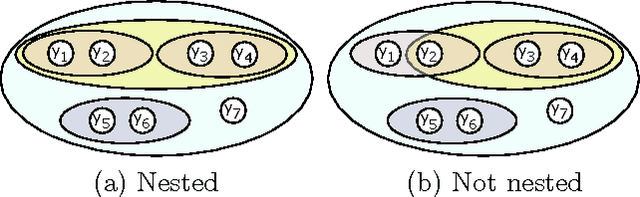
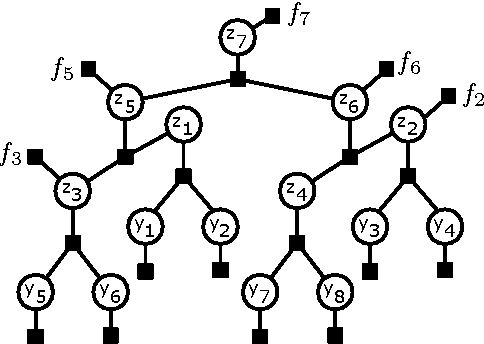
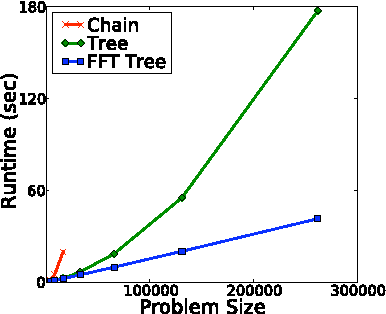
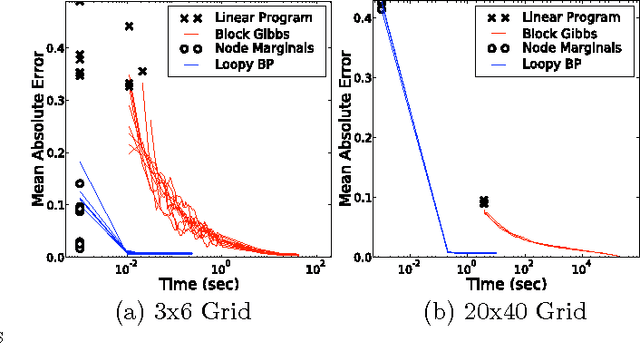
Cardinality potentials are a generally useful class of high order potential that affect probabilities based on how many of D binary variables are active. Maximum a posteriori (MAP) inference for cardinality potential models is well-understood, with efficient computations taking O(DlogD) time. Yet efficient marginalization and sampling have not been addressed as thoroughly in the machine learning community. We show that there exists a simple algorithm for computing marginal probabilities and drawing exact joint samples that runs in O(Dlog2 D) time, and we show how to frame the algorithm as efficient belief propagation in a low order tree-structured model that includes additional auxiliary variables. We then develop a new, more general class of models, termed Recursive Cardinality models, which take advantage of this efficiency. Finally, we show how to do efficient exact inference in models composed of a tree structure and a cardinality potential. We explore the expressive power of Recursive Cardinality models and empirically demonstrate their utility.
On Nonparametric Guidance for Learning Autoencoder Representations
Oct 26, 2011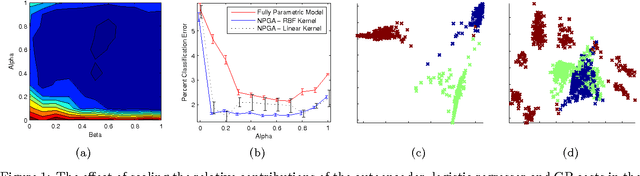

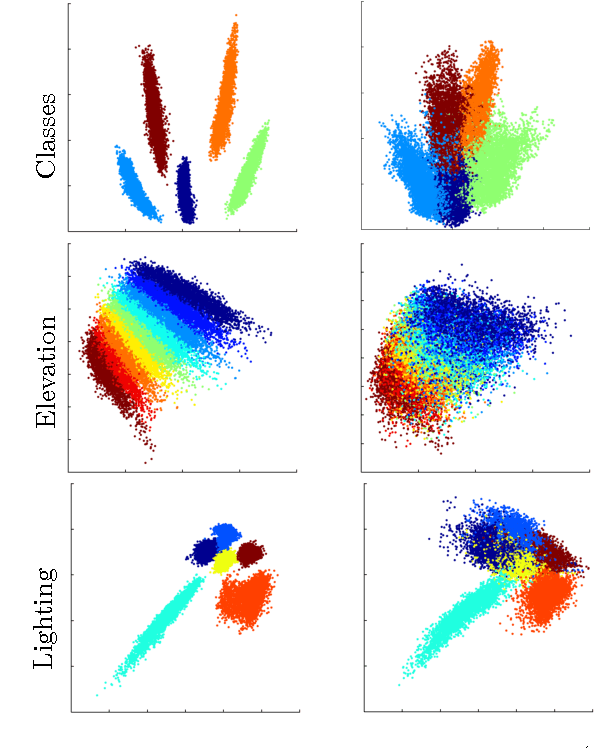
Unsupervised discovery of latent representations, in addition to being useful for density modeling, visualisation and exploratory data analysis, is also increasingly important for learning features relevant to discriminative tasks. Autoencoders, in particular, have proven to be an effective way to learn latent codes that reflect meaningful variations in data. A continuing challenge, however, is guiding an autoencoder toward representations that are useful for particular tasks. A complementary challenge is to find codes that are invariant to irrelevant transformations of the data. The most common way of introducing such problem-specific guidance in autoencoders has been through the incorporation of a parametric component that ties the latent representation to the label information. In this work, we argue that a preferable approach relies instead on a nonparametric guidance mechanism. Conceptually, it ensures that there exists a function that can predict the label information, without explicitly instantiating that function. The superiority of this guidance mechanism is confirmed on two datasets. In particular, this approach is able to incorporate invariance information (lighting, elevation, etc.) from the small NORB object recognition dataset and yields state-of-the-art performance for a single layer, non-convolutional network.
Ranking via Sinkhorn Propagation
Jun 14, 2011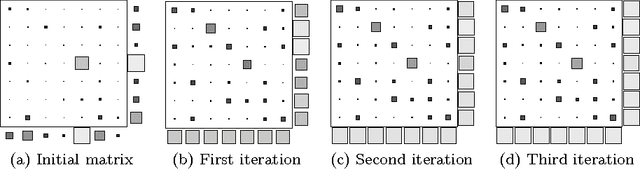
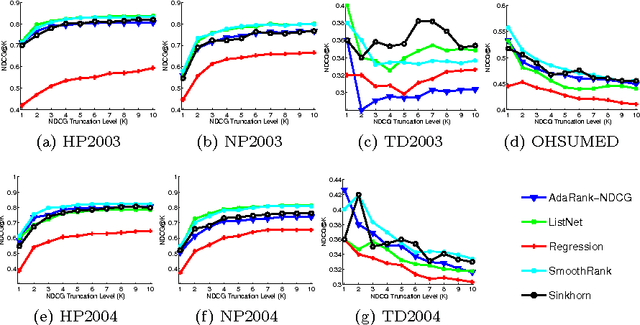
It is of increasing importance to develop learning methods for ranking. In contrast to many learning objectives, however, the ranking problem presents difficulties due to the fact that the space of permutations is not smooth. In this paper, we examine the class of rank-linear objective functions, which includes popular metrics such as precision and discounted cumulative gain. In particular, we observe that expectations of these gains are completely characterized by the marginals of the corresponding distribution over permutation matrices. Thus, the expectations of rank-linear objectives can always be described through locations in the Birkhoff polytope, i.e., doubly-stochastic matrices (DSMs). We propose a technique for learning DSM-based ranking functions using an iterative projection operator known as Sinkhorn normalization. Gradients of this operator can be computed via backpropagation, resulting in an algorithm we call Sinkhorn propagation, or SinkProp. This approach can be combined with a wide range of gradient-based approaches to rank learning. We demonstrate the utility of SinkProp on several information retrieval data sets.
Slice sampling covariance hyperparameters of latent Gaussian models
Oct 28, 2010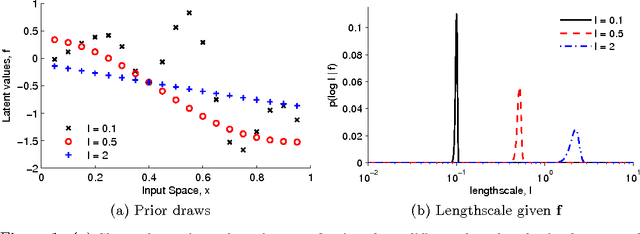
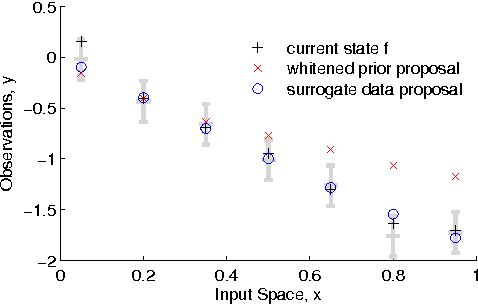
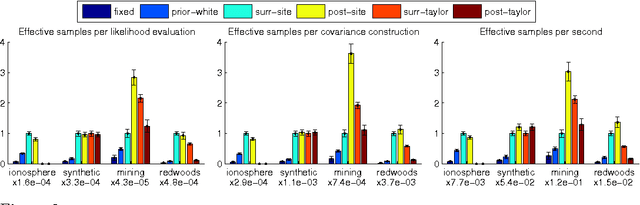
The Gaussian process (GP) is a popular way to specify dependencies between random variables in a probabilistic model. In the Bayesian framework the covariance structure can be specified using unknown hyperparameters. Integrating over these hyperparameters considers different possible explanations for the data when making predictions. This integration is often performed using Markov chain Monte Carlo (MCMC) sampling. However, with non-Gaussian observations standard hyperparameter sampling approaches require careful tuning and may converge slowly. In this paper we present a slice sampling approach that requires little tuning while mixing well in both strong- and weak-data regimes.
Learning the Structure of Deep Sparse Graphical Models
Aug 19, 2010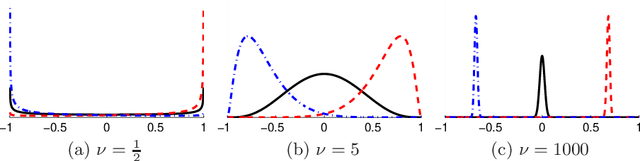


Deep belief networks are a powerful way to model complex probability distributions. However, learning the structure of a belief network, particularly one with hidden units, is difficult. The Indian buffet process has been used as a nonparametric Bayesian prior on the directed structure of a belief network with a single infinitely wide hidden layer. In this paper, we introduce the cascading Indian buffet process (CIBP), which provides a nonparametric prior on the structure of a layered, directed belief network that is unbounded in both depth and width, yet allows tractable inference. We use the CIBP prior with the nonlinear Gaussian belief network so each unit can additionally vary its behavior between discrete and continuous representations. We provide Markov chain Monte Carlo algorithms for inference in these belief networks and explore the structures learned on several image data sets.
Tree-Structured Stick Breaking Processes for Hierarchical Data
Jun 05, 2010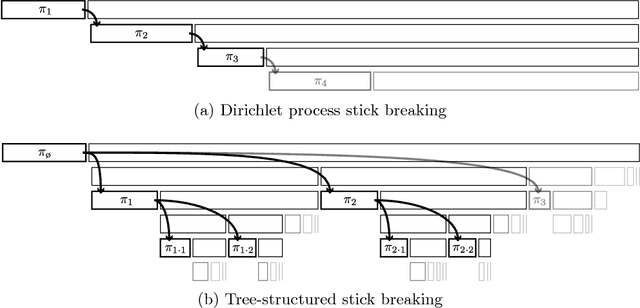
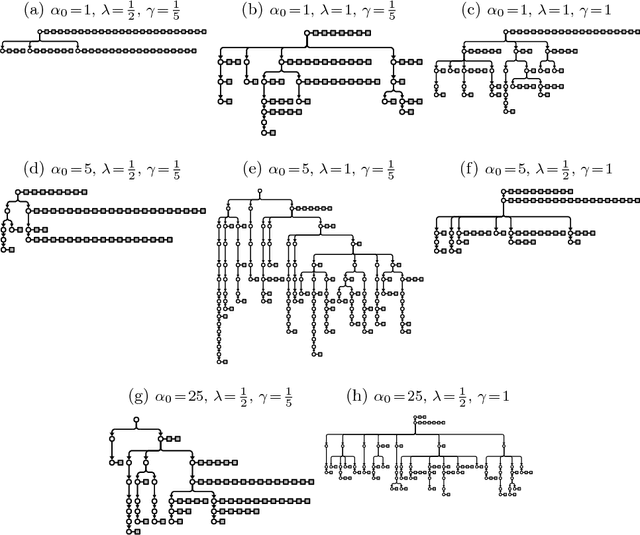
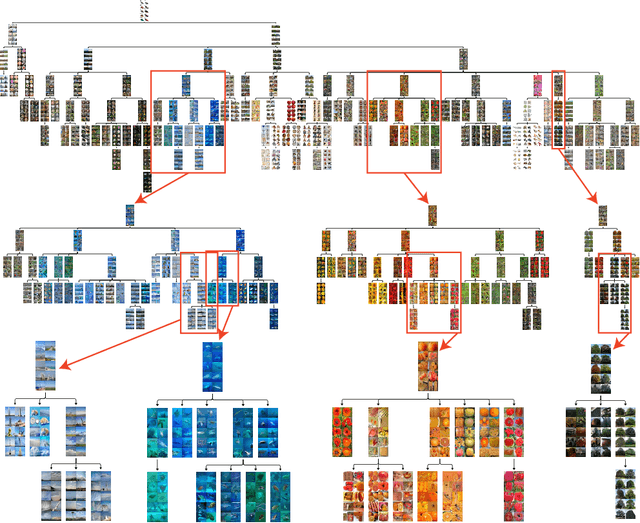
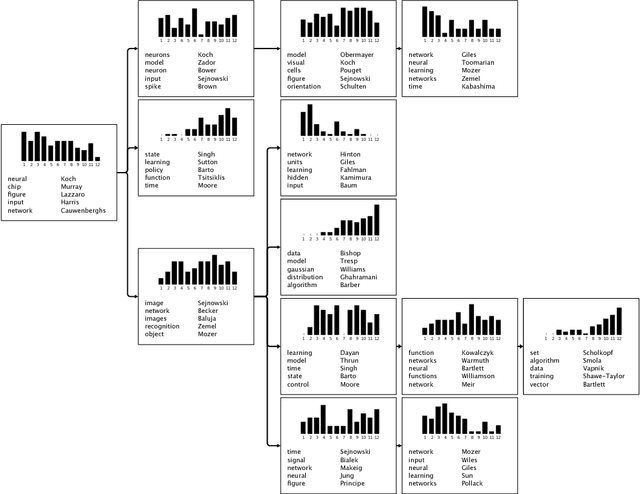
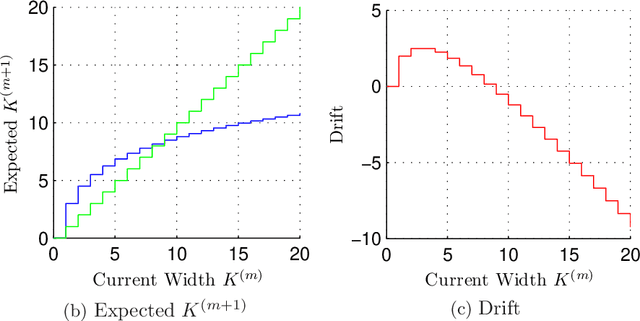
Many data are naturally modeled by an unobserved hierarchical structure. In this paper we propose a flexible nonparametric prior over unknown data hierarchies. The approach uses nested stick-breaking processes to allow for trees of unbounded width and depth, where data can live at any node and are infinitely exchangeable. One can view our model as providing infinite mixtures where the components have a dependency structure corresponding to an evolutionary diffusion down a tree. By using a stick-breaking approach, we can apply Markov chain Monte Carlo methods based on slice sampling to perform Bayesian inference and simulate from the posterior distribution on trees. We apply our method to hierarchical clustering of images and topic modeling of text data.