 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Momentum Contrastive Clustering
Jun 10, 2022
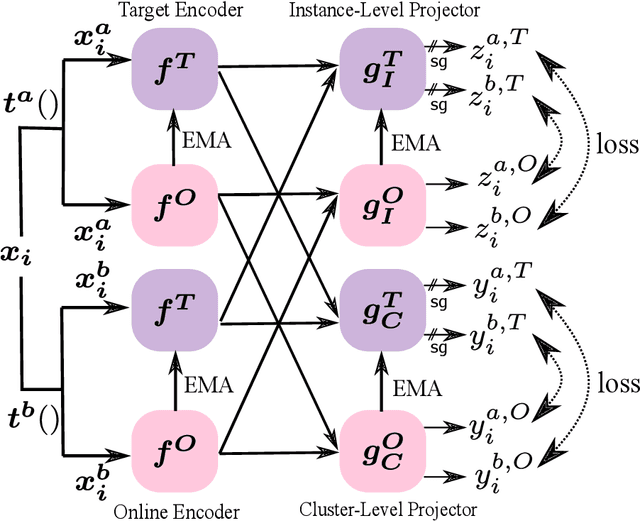
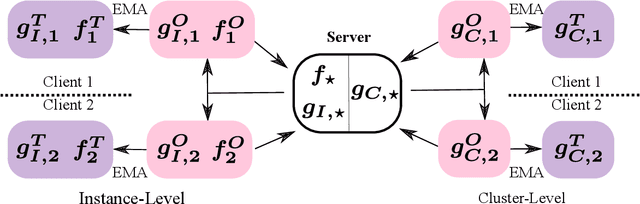

We present federated momentum contrastive clustering (FedMCC), a learning framework that can not only extract discriminative representations over distributed local data but also perform data clustering. In FedMCC, a transformed data pair passes through both the online and target networks, resulting in four representations over which the losses are determined. The resulting high-quality representations generated by FedMCC can outperform several existing self-supervised learning methods for linear evaluation and semi-supervised learning tasks. FedMCC can easily be adapted to ordinary centralized clustering through what we call momentum contrastive clustering (MCC). We show that MCC achieves state-of-the-art clustering accuracy results in certain datasets such as STL-10 and ImageNet-10. We also present a method to reduce the memory footprint of our clustering schemes.
Multiplication-Avoiding Variant of Power Iteration with Applications
Oct 22, 2021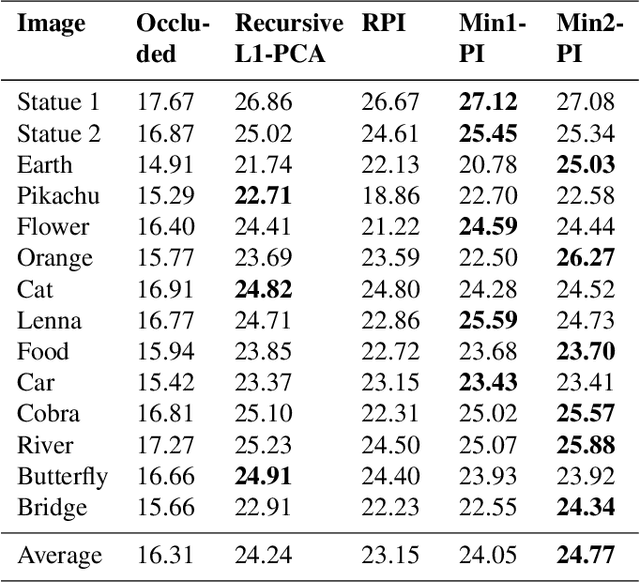

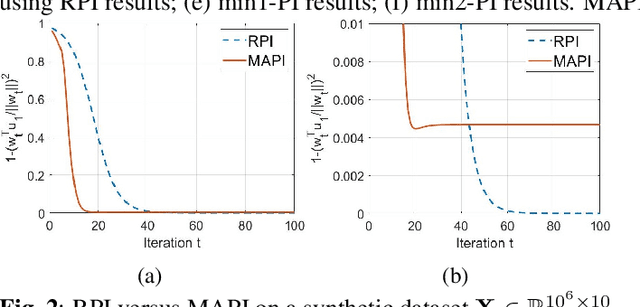
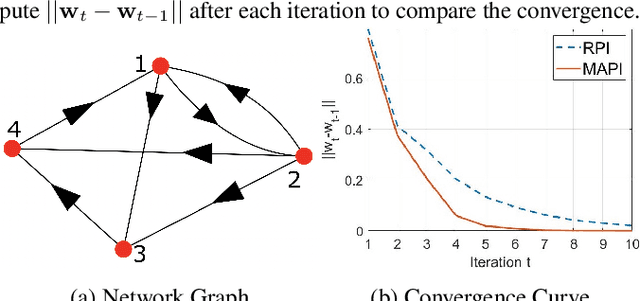
Power iteration is a fundamental algorithm in data analysis. It extracts the eigenvector corresponding to the largest eigenvalue of a given matrix. Applications include ranking algorithms, recommendation systems, principal component analysis (PCA), among many others. In this paper, We introduce multiplication-avoiding power iteration (MAPI), which replaces the standard $\ell_2$-inner products that appear at the regular power iteration (RPI) with multiplication-free vector products which are Mercer-type kernel operations related with the $\ell_1$ norm. Precisely, for an $n\times n$ matrix, MAPI requires $n$ multiplications, while RPI needs $n^2$ multiplications per iteration. Therefore, MAPI provides a significant reduction of the number of multiplication operations, which are known to be costly in terms of energy consumption. We provide applications of MAPI to PCA-based image reconstruction as well as to graph-based ranking algorithms. When compared to RPI, MAPI not only typically converges much faster, but also provides superior performance.