 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOT: A Benchmark for Evaluating Chinese Long Text Understanding and Generation
Aug 30, 2021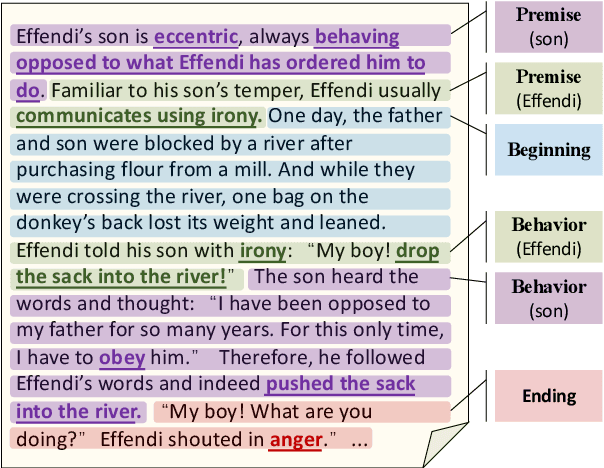

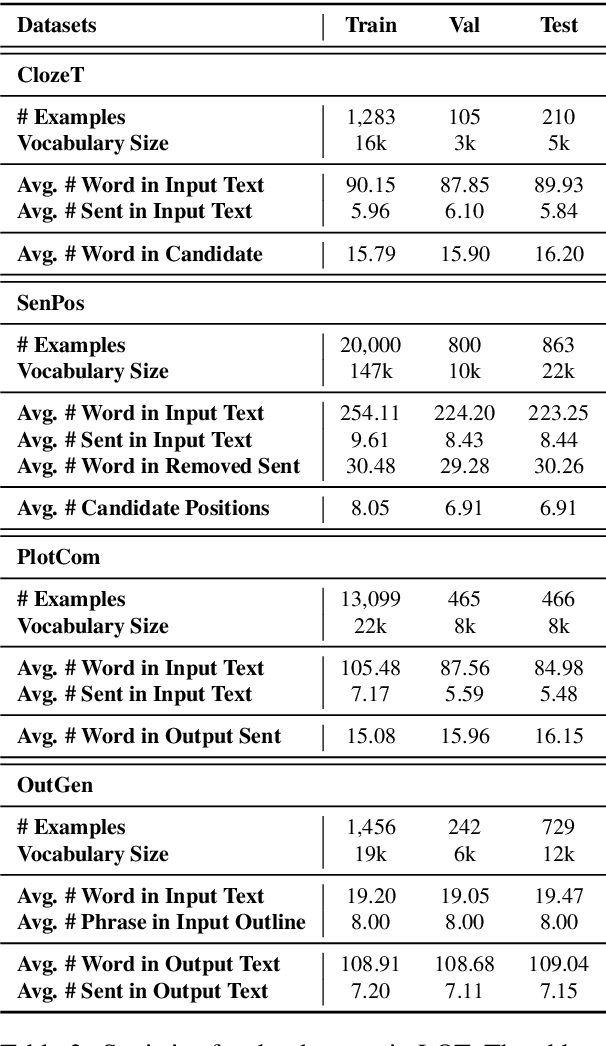

Standard multi-task benchmarks are essential for driving the progress of general pretraining models to generalize to various downstream tasks. However, existing benchmarks such as GLUE and GLGE tend to focus on short text understanding and generation tasks, without considering long text modeling, which requires many distinct capabilities such as modeling long-range commonsense and discourse relations, as well as the coherence and controllability of generation. The lack of standardized benchmarks makes it difficult to fully evaluate these capabilities of a model and fairly compare different models, especially Chinese pretraining models. Therefore, we propose LOT, a benchmark including two understanding and two generation tasks for Chinese long text modeling evaluation. We construct the datasets for the tasks based on various kinds of human-written Chinese stories. Besides, we release an encoder-decoder Chinese long text pretraining model named LongLM with up to 1 billion parameters. We pretrain LongLM on 120G Chinese novels with two generative tasks including text infilling and conditional continuation. Extensive experiments on LOT demonstrate that LongLM matches the performance of similar-sized pretraining models on the understanding tasks and outperforms strong baselines substantially on the generation tasks.