 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe "Small World of Words" German Free-Association Norms
Apr 21, 2026Free-association norms provide essential empirical data for investigating linguistic, semantic, and cultural phenomena in the cognitive sciences. Although large-scale norms exist for languages such as English, Dutch, Spanish, and Mandarin Chinese, no comparable resource has been available for German. To address this gap, we present free-association norms for 5,877 German cue words as part of the German version of the multilingual Small World of Words (SWOW) project. We describe the data collection procedures, participant characteristics, and our comprehensive preprocessing pipeline before introducing the resulting SWOW-DE data set. Using data from three established psycholinguistic paradigms, we show that SWOW-DE norms robustly predict performance in lexical decision tasks, relatedness judgments, and psycholinguistic word ratings. Furthermore, we demonstrate that SWOW-DE responses compare favorably with existing German resources and provide a preliminary cross-linguistic comparison revealing both shared and language-specific association patterns, highlighting promising directions for future research. Overall, SWOW-DE represents the largest collection of German free associations to date and offers a unique resource for linguistic, psychological, and cross-cultural research.
Probing the contents of semantic representations from text, behavior, and brain data using the psychNorms metabase
Dec 06, 2024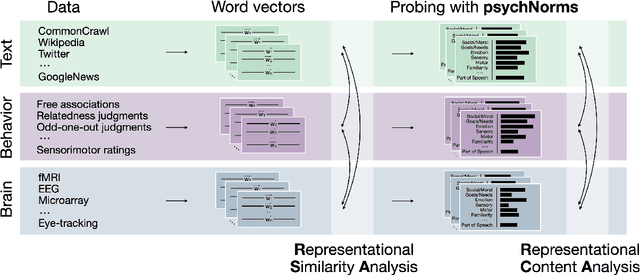
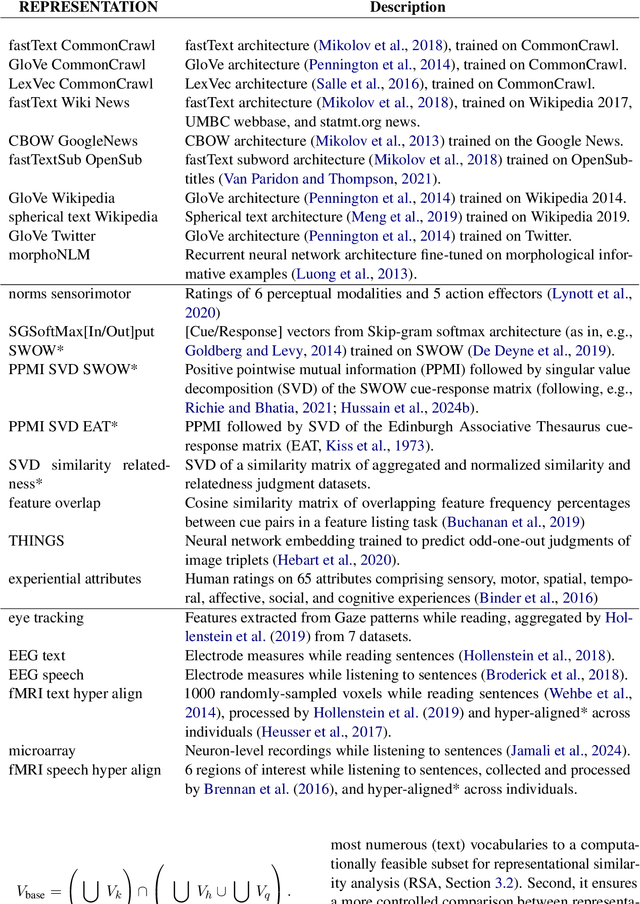
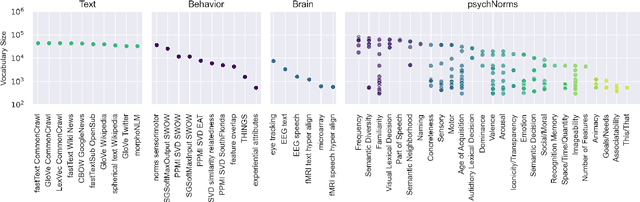
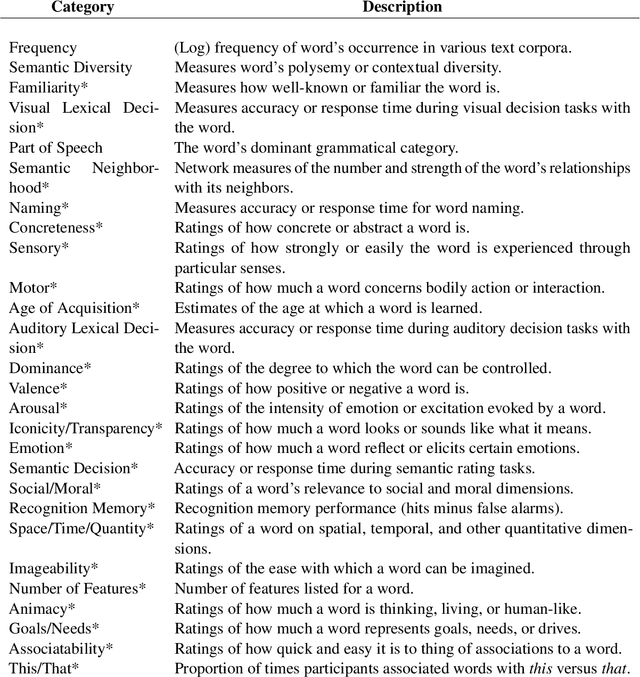
Semantic representations are integral to natural language processing, psycholinguistics, and artificial intelligence. Although often derived from internet text, recent years have seen a rise in the popularity of behavior-based (e.g., free associations) and brain-based (e.g., fMRI) representations, which promise improvements in our ability to measure and model human representations. We carry out the first systematic evaluation of the similarities and differences between semantic representations derived from text, behavior, and brain data. Using representational similarity analysis, we show that word vectors derived from behavior and brain data encode information that differs from their text-derived cousins. Furthermore, drawing on our psychNorms metabase, alongside an interpretability method that we call representational content analysis, we find that, in particular, behavior representations capture unique variance on certain affective, agentic, and socio-moral dimensions. We thus establish behavior as an important complement to text for capturing human representations and behavior. These results are broadly relevant to research aimed at learning human-aligned semantic representations, including work on evaluating and aligning large language models.
Measuring individual semantic networks: A simulation study
Oct 23, 2024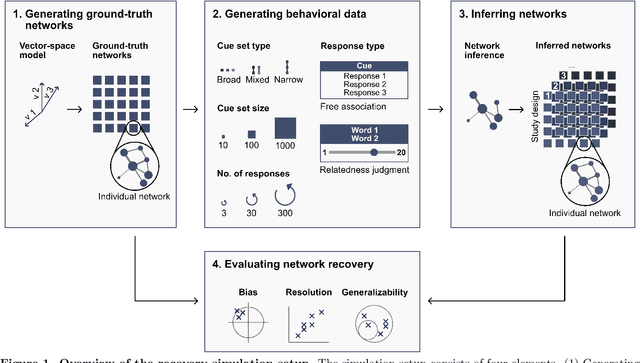
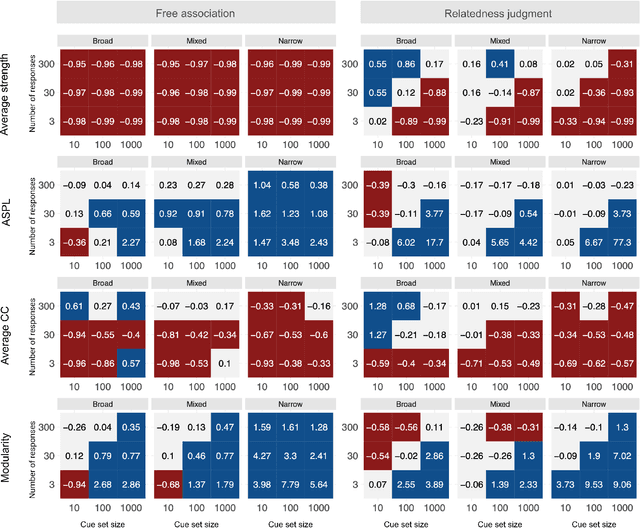
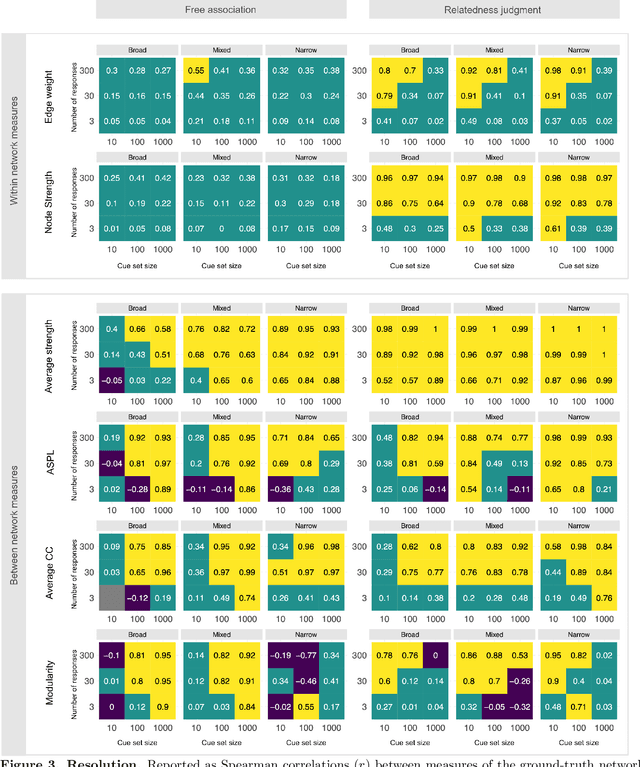
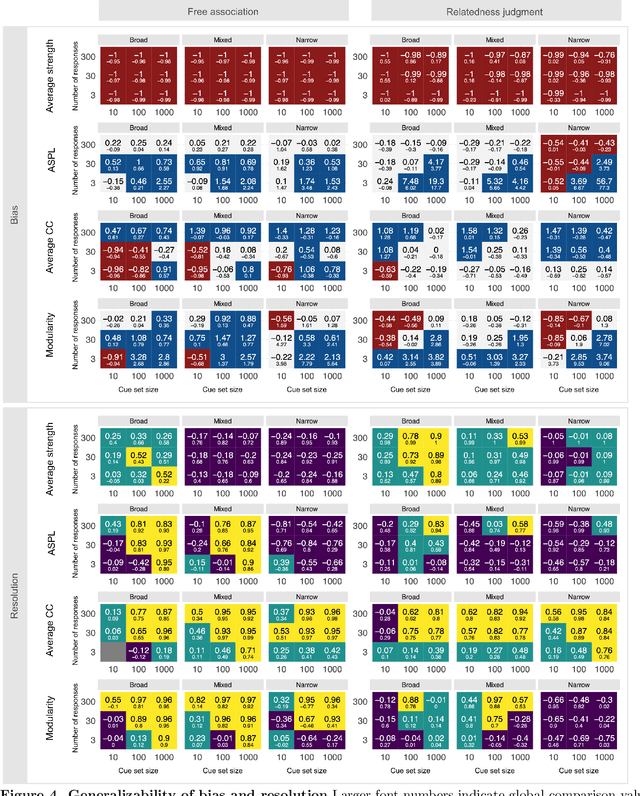
Accurately capturing individual differences in semantic networks is fundamental to advancing our mechanistic understanding of semantic memory. Past empirical attempts to construct individual-level semantic networks from behavioral paradigms may be limited by data constraints. To assess these limitations and propose improved designs for the measurement of individual semantic networks, we conducted a recovery simulation investigating the psychometric properties underlying estimates of individual semantic networks obtained from two different behavioral paradigms: free associations and relatedness judgment tasks. Our results show that successful inference of semantic networks is achievable, but they also highlight critical challenges. Estimates of absolute network characteristics are severely biased, such that comparisons between behavioral paradigms and different design configurations are often not meaningful. However, comparisons within a given paradigm and design configuration can be accurate and generalizable when based on designs with moderate numbers of cues, moderate numbers of responses, and cue sets including diverse words. Ultimately, our results provide insights that help evaluate past findings on the structure of semantic networks and design new studies capable of more reliably revealing individual differences in semantic networks.
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Using novel data and ensemble models to improve automated labeling of Sustainable Development Goals
Feb 01, 2023A number of labeling systems based on text have been proposed to help monitor work on the United Nations (UN) Sustainable Development Goals (SDGs). Here, we present a systematic comparison of systems using a variety of text sources and show that systems differ considerably in their specificity (i.e., true-positive rate) and sensitivity (i.e., true-negative rate), have systematic biases (e.g., are more sensitive to specific SDGs relative to others), and are susceptible to the type and amount of text analyzed. We then show that an ensemble model that pools labeling systems alleviates some of these limitations, exceeding the labeling performance of all currently available systems. We conclude that researchers and policymakers should care about the choice of labeling system and that ensemble methods should be favored when drawing conclusions about the absolute and relative prevalence of work on the SDGs based on automated methods.
text2sdg: An open-source solution to monitoring sustainable development goals from text
Oct 20, 2021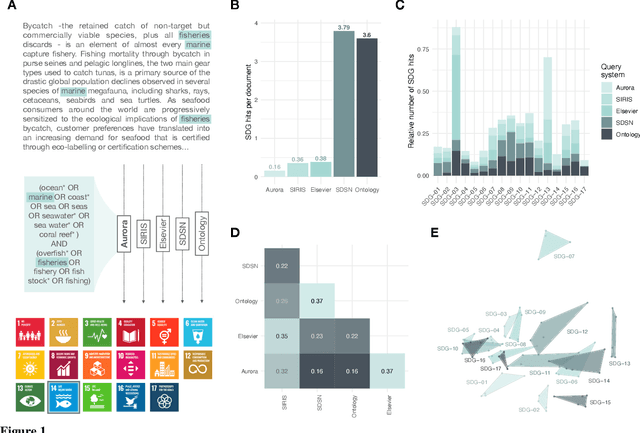
Monitoring progress on the United Nations Sustainable Development Goals (SDGs) is important for both academic and non-academic organizations. Existing approaches to monitoring SDGs have focused on specific data types, namely, publications listed in proprietary research databases. We present the text2sdg R package, a user-friendly, open-source package that detects SDGs in any kind of text data using several different query systems from any text source. The text2sdg package thereby facilitates the monitoring of SDGs for a wide array of text sources and provides a much-needed basis for validating and improving extant methods to detect SDGs from text.