 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Statistical Significance and Discriminative Power in Pattern Discovery
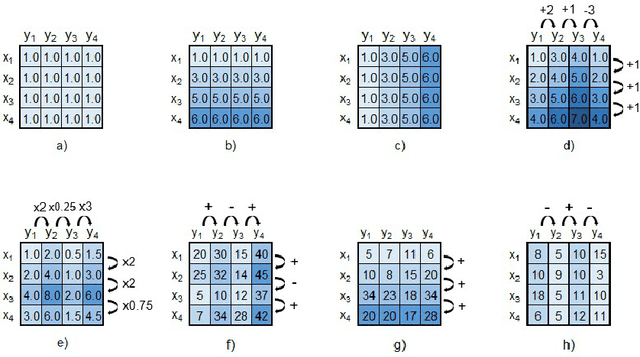
Jan 22, 2024Pattern discovery plays a central role in both descriptive and predictive tasks across multiple domains. Actionable patterns must meet rigorous statistical significance criteria and, in the presence of target variables, further uphold discriminative power. Our work addresses the underexplored area of guiding pattern discovery by integrating statistical significance and discriminative power criteria into state-of-the-art algorithms while preserving pattern quality. We also address how pattern quality thresholds, imposed by some algorithms, can be rectified to accommodate these additional criteria. To test the proposed methodology, we select the triclustering task as the guiding pattern discovery case and extend well-known greedy and multi-objective optimization triclustering algorithms, $\delta$-Trimax and TriGen, that use various pattern quality criteria, such as Mean Squared Residual (MSR), Least Squared Lines (LSL), and Multi Slope Measure (MSL). Results from three case studies show the role of the proposed methodology in discovering patterns with pronounced improvements of discriminative power and statistical significance without quality deterioration, highlighting its importance in supervisedly guiding the search. Although the proposed methodology is motivated over multivariate time series data, it can be straightforwardly extended to pattern discovery tasks involving multivariate, N-way (N>3), transactional, and sequential data structures. Availability: The code is freely available at https://github.com/JupitersMight/MOF_Triclustering under the MIT license.
TriSig: Assessing the statistical significance of triclusters
Jun 12, 2023
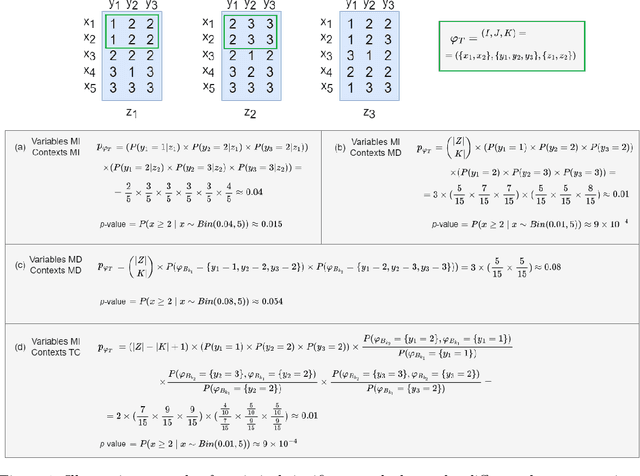

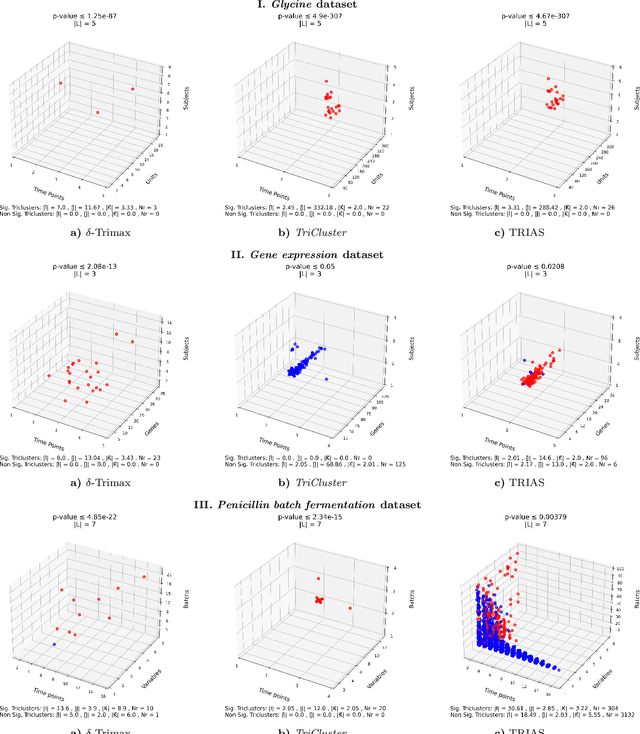
Tensor data analysis allows researchers to uncover novel patterns and relationships that cannot be obtained from matrix data alone. The information inferred from the patterns provides valuable insights into disease progression, bioproduction processes, weather fluctuations, and group dynamics. However, spurious and redundant patterns hamper this process. This work aims at proposing a statistical frame to assess the probability of patterns in tensor data to deviate from null expectations, extending well-established principles for assessing the statistical significance of patterns in matrix data. A comprehensive discussion on binomial testing for false positive discoveries is entailed at the light of: variable dependencies, temporal dependencies and misalignments, and \textit{p}-value corrections under the Benjamini-Hochberg procedure. Results gathered from the application of state-of-the-art triclustering algorithms over distinct real-world case studies in biochemical and biotechnological domains confer validity to the proposed statistical frame while revealing vulnerabilities of some triclustering searches. The proposed assessment can be incorporated into existing triclustering algorithms to mitigate false positive/spurious discoveries and further prune the search space, reducing their computational complexity. Availability: The code is freely available at https://github.com/JupitersMight/TriSig under the MIT license.
User-Specific Bicluster-based Collaborative Filtering: Handling Preference Locality, Sparsity and Subjectivity
Nov 15, 2022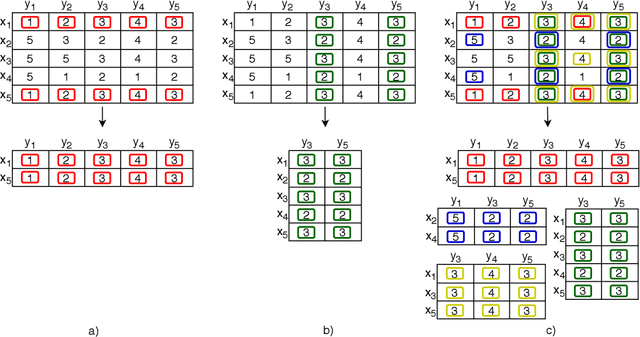
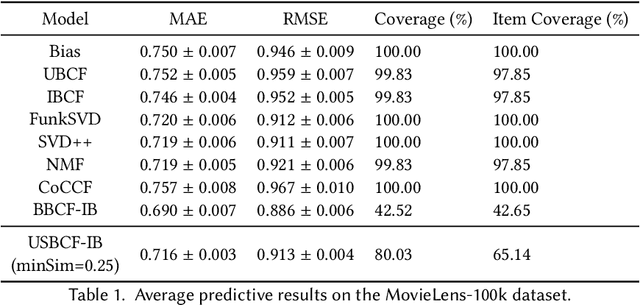

Collaborative Filtering (CF), the most common approach to build Recommender Systems, became pervasive in our daily lives as consumers of products and services. However, challenges limit the effectiveness of Collaborative Filtering approaches when dealing with recommendation data, mainly due to the diversity and locality of user preferences, structural sparsity of user-item ratings, subjectivity of rating scales, and increasingly high item dimensionality and user bases. To answer some of these challenges, some authors proposed successful approaches combining CF with Biclustering techniques. This work assesses the effectiveness of Biclustering approaches for CF, comparing the impact of algorithmic choices, and identifies principles for superior Biclustering-based CF. As a result, we propose USBFC, a Biclustering-based CF approach that creates user-specific models from strongly coherent and statistically significant rating patterns, corresponding to subspaces of shared preferences across users. Evaluation on real-world data reveals that USBCF achieves competitive predictive accuracy against state-of-the-art CF methods. Moreover, USBFC successfully suppresses the main shortcomings of the previously proposed state-of-the-art biclustering-based CF by increasing coverage, and coclustering-based CF by strengthening subspace homogeneity.
EEG to fMRI Synthesis Benefits from Attentional Graphs of Electrode Relationships
Mar 07, 2022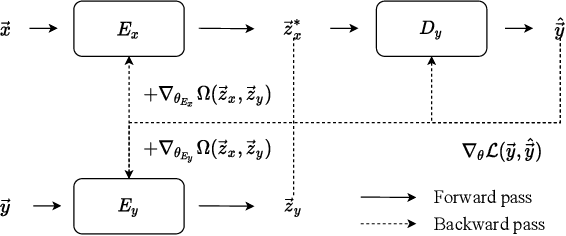

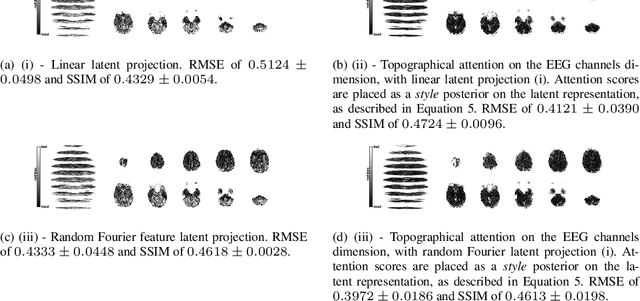
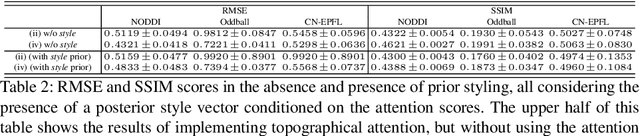
Topographical structures represent connections between entities and provide a comprehensive design of complex systems. Currently these structures are used to discover correlates of neuronal and haemodynamical activity. In this work, we incorporate them with neural processing techniques to perform regression, using electrophysiological activity to retrieve haemodynamics. To this end, we use Fourier features, attention mechanisms, shared space between modalities and incorporation of style in the latent representation. By combining these techniques, we propose several models that significantly outperform current state-of-the-art of this task in resting state and task-based recording settings. We report which EEG electrodes are the most relevant for the regression task and which relations impacted it the most. In addition, we observe that haemodynamic activity at the scalp, in contrast with sub-cortical regions, is relevant to the learned shared space. Overall, these results suggest that EEG electrode relationships are pivotal to retain information necessary for haemodynamical activity retrieval.
On the Role of Multi-Objective Optimization to the Transit Network Design Problem
Jan 27, 2022
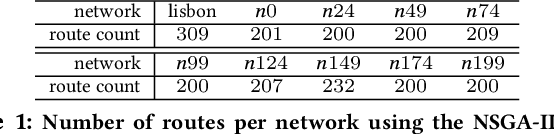


Ongoing traffic changes, including those triggered by the COVID-19 pandemic, reveal the necessity to adapt our public transport systems to the ever-changing users' needs. This work shows that single and multi objective stances can be synergistically combined to better answer the transit network design problem (TNDP). Single objective formulations are dynamically inferred from the rating of networks in the approximated (multi-objective) Pareto Front, where a regression approach is used to infer the optimal weights of transfer needs, times, distances, coverage, and costs. As a guiding case study, the solution is applied to the multimodal public transport network in the city of Lisbon, Portugal. The system takes individual trip data given by smartcard validations at CARRIS buses and METRO subway stations and uses them to estimate the origin-destination demand in the city. Then, Genetic Algorithms are used, considering both single and multi objective approaches, to redesign the bus network that better fits the observed traffic demand. The proposed TNDP optimization proved to improve results, with reductions in objective functions of up to 28.3%. The system managed to extensively reduce the number of routes, and all passenger related objectives, including travel time and transfers per trip, significantly improve. Grounded on automated fare collection data, the system can incrementally redesign the bus network to dynamically handle ongoing changes to the city traffic.
Context-aware demand prediction in bike sharing systems: incorporating spatial, meteorological and calendrical context
May 03, 2021
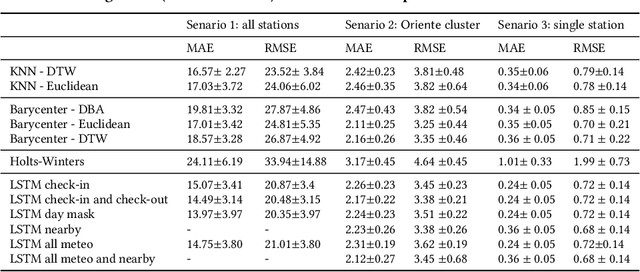
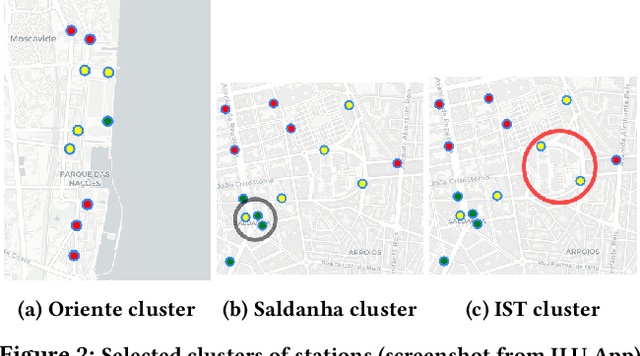

Bike sharing demand is increasing in large cities worldwide. The proper functioning of bike-sharing systems is, nevertheless, dependent on a balanced geographical distribution of bicycles throughout a day. In this context, understanding the spatiotemporal distribution of check-ins and check-outs is key for station balancing and bike relocation initiatives. Still, recent contributions from deep learning and distance-based predictors show limited success on forecasting bike sharing demand. This consistent observation is hypothesized to be driven by: i) the strong dependence between demand and the meteorological and situational context of stations; and ii) the absence of spatial awareness as most predictors are unable to model the effects of high-low station load on nearby stations. This work proposes a comprehensive set of new principles to incorporate both historical and prospective sources of spatial, meteorological, situational and calendrical context in predictive models of station demand. To this end, a new recurrent neural network layering composed by serial long-short term memory (LSTM) components is proposed with two major contributions: i) the feeding of multivariate time series masks produced from historical context data at the input layer, and ii) the time-dependent regularization of the forecasted time series using prospective context data. This work further assesses the impact of incorporating different sources of context, showing the relevance of the proposed principles for the community even though not all improvements from the context-aware predictors yield statistical significance.
EEG to fMRI Synthesis: Is Deep Learning a candidate?
Sep 29, 2020
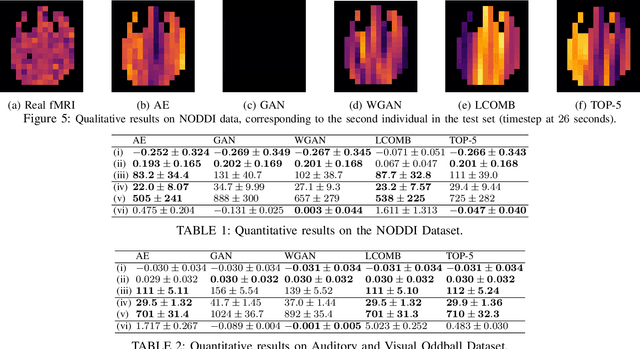

Advances on signal, image and video generation underly major breakthroughs on generative medical imaging tasks, including Brain Image Synthesis. Still, the extent to which functional Magnetic Ressonance Imaging (fMRI) can be mapped from the brain electrophysiology remains largely unexplored. This work provides the first comprehensive view on how to use state-of-the-art principles from Neural Processing to synthesize fMRI data from electroencephalographic (EEG) data. Given the distinct spatiotemporal nature of haemodynamic and electrophysiological signals, this problem is formulated as the task of learning a mapping function between multivariate time series with highly dissimilar structures. A comparison of state-of-the-art synthesis approaches, including Autoencoders, Generative Adversarial Networks and Pairwise Learning, is undertaken. Results highlight the feasibility of EEG to fMRI brain image mappings, pinpointing the role of current advances in Machine Learning and showing the relevance of upcoming contributions to further improve performance. EEG to fMRI synthesis offers a way to enhance and augment brain image data, and guarantee access to more affordable, portable and long-lasting protocols of brain activity monitoring. The code used in this manuscript is available in Github and the datasets are open source.
fMRI Multiple Missing Values Imputation Regularized by a Recurrent Denoiser
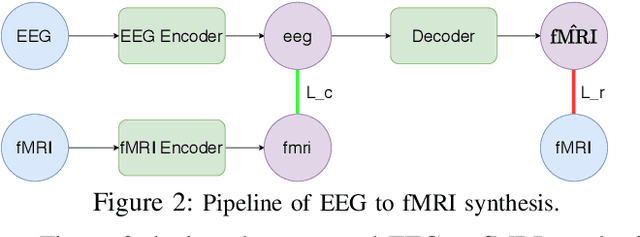
Sep 26, 2020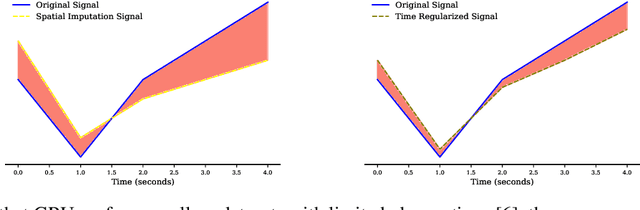
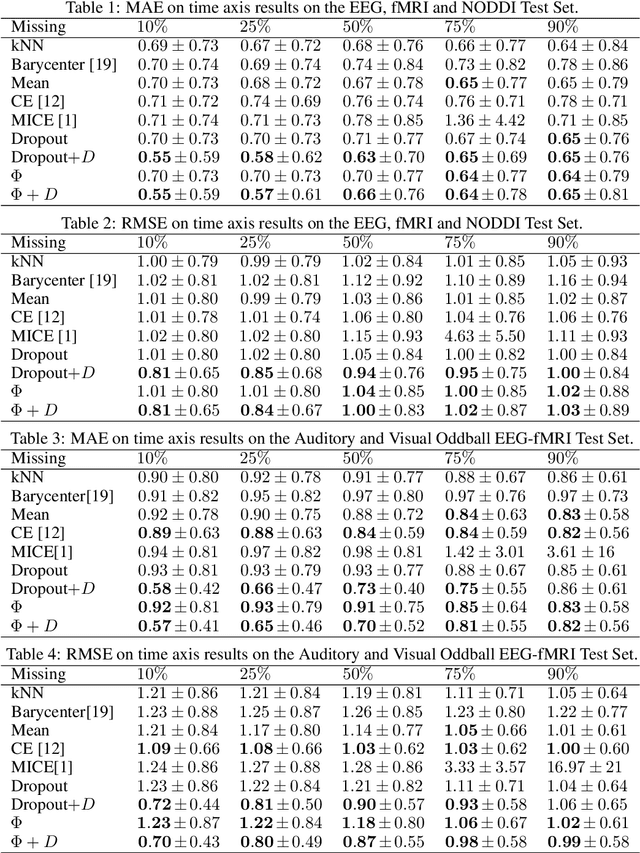
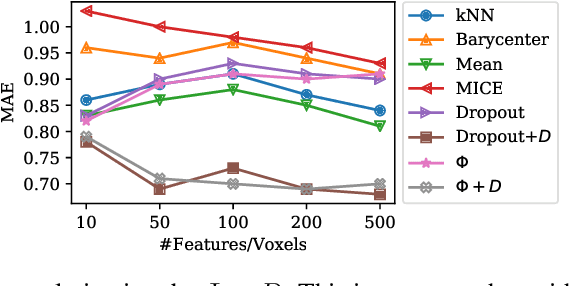
Functional Magnetic Resonance Imaging (fMRI) is a neuroimaging technique with pivotal importance due to its scientific and clinical applications. As with any widely used imaging modality, there is a need to ensure the quality of the same, with missing values being highly frequent due to the presence of artifacts or sub-optimal imaging resolutions. Our work focus on missing values imputation on multivariate signal data. To do so, a new imputation method is proposed consisting on two major steps: spatial-dependent signal imputation and time-dependent regularization of the imputed signal. A novel layer, to be used in deep learning architectures, is proposed in this work, bringing back the concept of chained equations for multiple imputation. Finally, a recurrent layer is applied to tune the signal, such that it captures its true patterns. Both operations yield an improved robustness against state-of-the-art alternatives.
On the use of Pairwise Distance Learning for Brain Signal Classification with Limited Observations
Jun 05, 2019
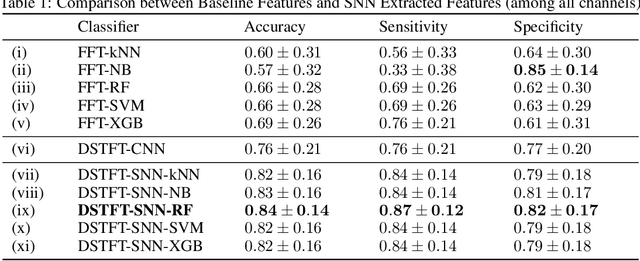
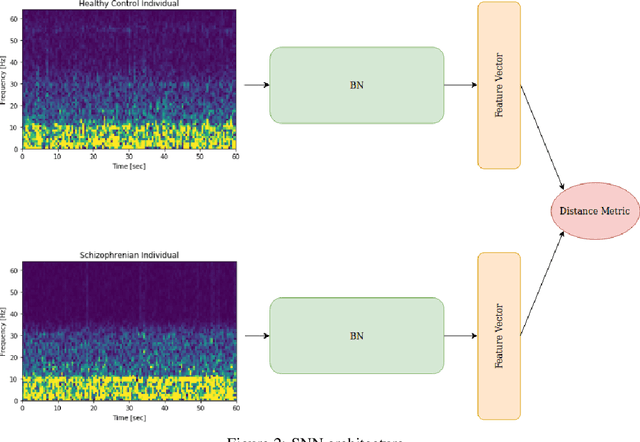

The increasing access to brain signal data using electroencephalography creates new opportunities to study electrophysiological brain activity and perform ambulatory diagnoses of neuronal diseases. This work proposes a pairwise distance learning approach for Schizophrenia classification relying on the spectral properties of the signal. Given the limited number of observations (i.e. the case and/or control individuals) in clinical trials, we propose a Siamese neural network architecture to learn a discriminative feature space from pairwise combinations of observations per channel. In this way, the multivariate order of the signal is used as a form of data augmentation, further supporting the network generalization ability. Convolutional layers with parameters learned under a cosine contrastive loss are proposed to adequately explore spectral images derived from the brain signal. Results on a case-control population show that the features extracted using the proposed neural network lead to an improved Schizophrenia diagnosis (+10pp in accuracy and sensitivity) against spectral features, thus suggesting the existence of non-trivial, discriminative electrophysiological brain patterns.
On When and How to use SAT to Mine Frequent Itemsets
Jul 26, 2012
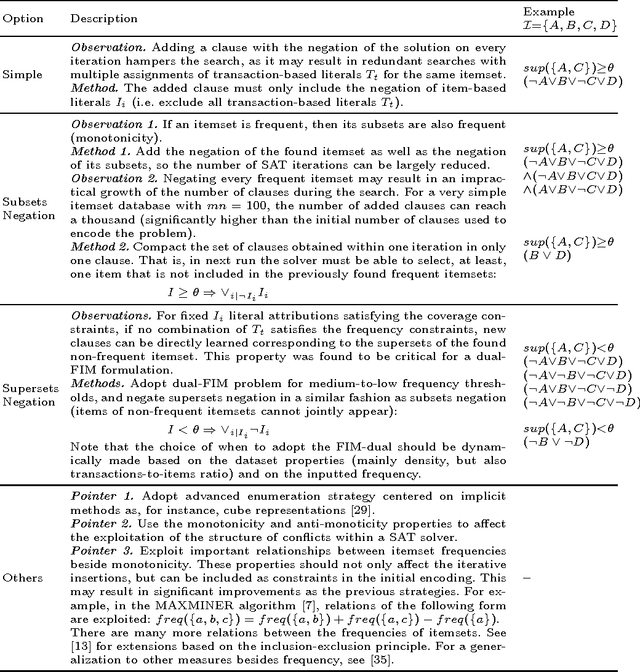
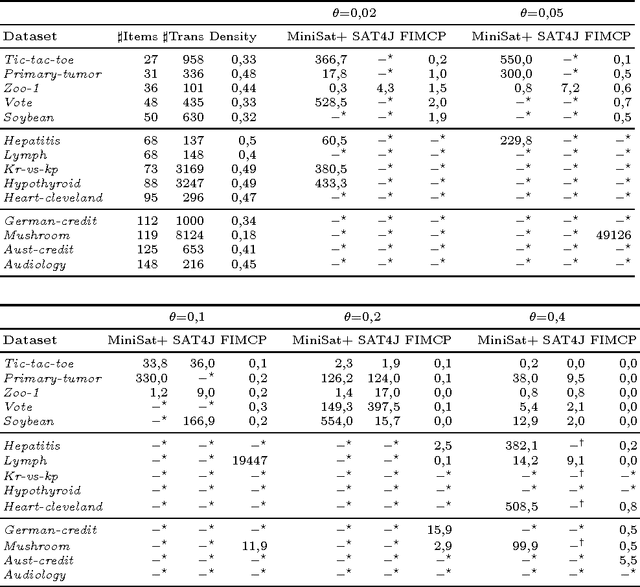

A new stream of research was born in the last decade with the goal of mining itemsets of interest using Constraint Programming (CP). This has promoted a natural way to combine complex constraints in a highly flexible manner. Although CP state-of-the-art solutions formulate the task using Boolean variables, the few attempts to adopt propositional Satisfiability (SAT) provided an unsatisfactory performance. This work deepens the study on when and how to use SAT for the frequent itemset mining (FIM) problem by defining different encodings with multiple task-driven enumeration options and search strategies. Although for the majority of the scenarios SAT-based solutions appear to be non-competitive with CP peers, results show a variety of interesting cases where SAT encodings are the best option.