 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Risk Bounds for Neural Networks through Sparsity based Compression
Jun 03, 2019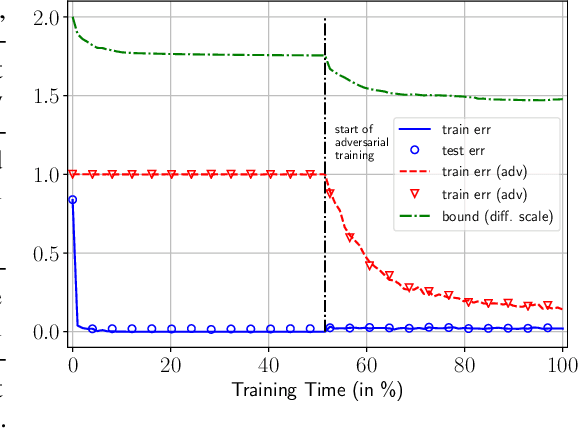
Neural networks have been shown to be vulnerable against minor adversarial perturbations of their inputs, especially for high dimensional data under $\ell_\infty$ attacks. To combat this problem, techniques like adversarial training have been employed to obtain models which are robust on the training set. However, the robustness of such models against adversarial perturbations may not generalize to unseen data. To study how robustness generalizes, recent works assume that the inputs have bounded $\ell_2$-norm in order to bound the adversarial risk for $\ell_\infty$ attacks with no explicit dimension dependence. In this work we focus on $\ell_\infty$ attacks on $\ell_\infty$ bounded inputs and prove margin-based bounds. Specifically, we use a compression based approach that relies on efficiently compressing the set of tunable parameters without distorting the adversarial risk. To achieve this, we apply the concept of effective sparsity and effective joint sparsity on the weight matrices of neural networks. This leads to bounds with no explicit dependence on the input dimension, neither on the number of classes. Our results show that neural networks with approximately sparse weight matrices not only enjoy enhanced robustness, but also better generalization.
On the Effect of Low-Rank Weights on Adversarial Robustness of Neural Networks
Jan 29, 2019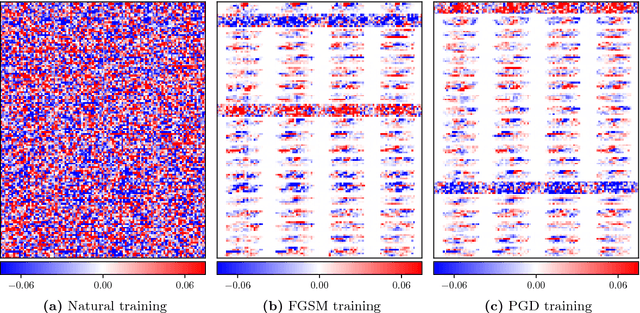
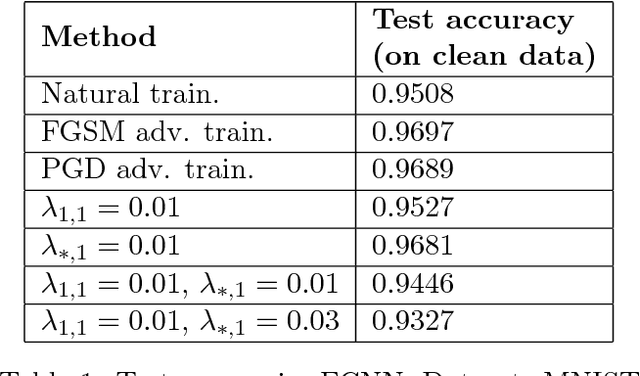
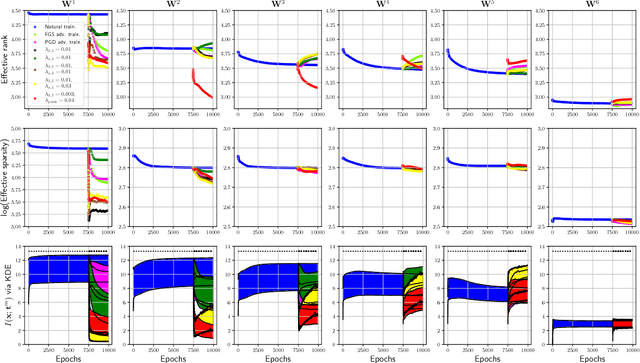
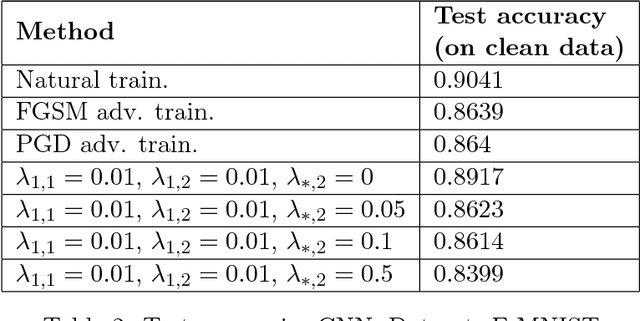
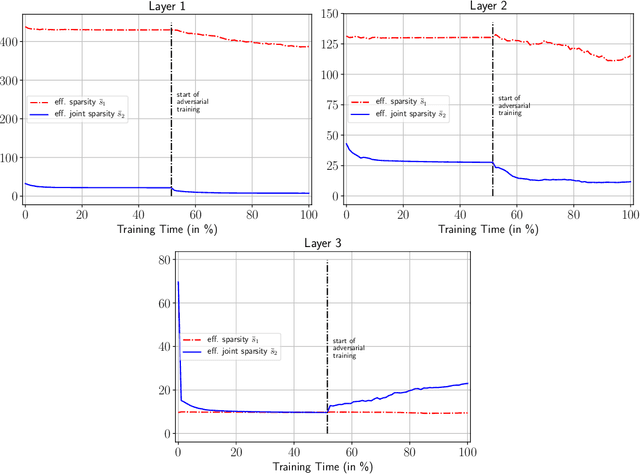
Recently, there has been an abundance of works on designing Deep Neural Networks (DNNs) that are robust to adversarial examples. In particular, a central question is which features of DNNs influence adversarial robustness and, therefore, can be to used to design robust DNNs. In this work, this problem is studied through the lens of compression which is captured by the low-rank structure of weight matrices. It is first shown that adversarial training tends to promote simultaneously low-rank and sparse structure in the weight matrices of neural networks. This is measured through the notions of effective rank and effective sparsity. In the reverse direction, when the low rank structure is promoted by nuclear norm regularization and combined with sparsity inducing regularizations, neural networks show significantly improved adversarial robustness. The effect of nuclear norm regularization on adversarial robustness is paramount when it is applied to convolutional neural networks. Although still not competing with adversarial training, this result contributes to understanding the key properties of robust classifiers.
Perturbation Analysis of Learning Algorithms: A Unifying Perspective on Generation of Adversarial Examples
Dec 15, 2018
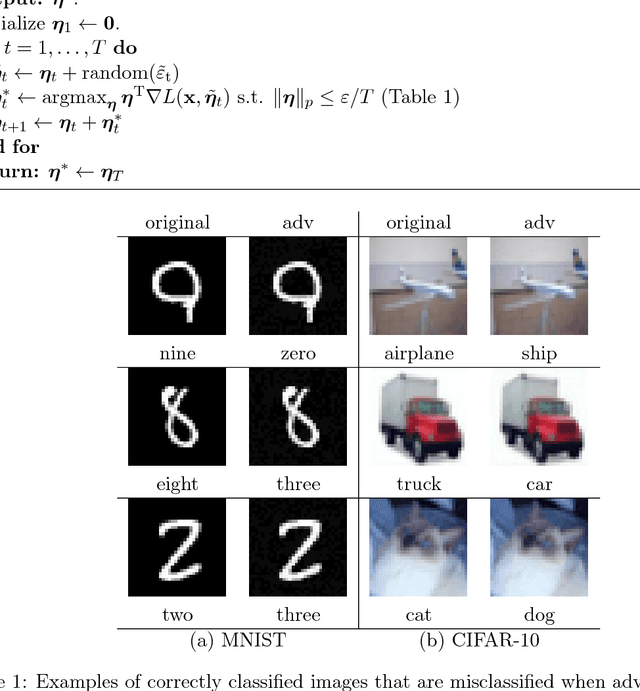


Despite the tremendous success of deep neural networks in various learning problems, it has been observed that adding an intentionally designed adversarial perturbation to inputs of these architectures leads to erroneous classification with high confidence in the prediction. In this work, we propose a general framework based on the perturbation analysis of learning algorithms which consists of convex programming and is able to recover many current adversarial attacks as special cases. The framework can be used to propose novel attacks against learning algorithms for classification and regression tasks under various new constraints with closed form solutions in many instances. In particular we derive new attacks against classification algorithms which are shown to achieve comparable performances to notable existing attacks. The framework is then used to generate adversarial perturbations for regression tasks which include single pixel and single subset attacks. By applying this method to autoencoding and image colorization tasks, it is shown that adversarial perturbations can effectively perturb the output of regression tasks as well.
On Generation of Adversarial Examples using Convex Programming
Jul 10, 2018
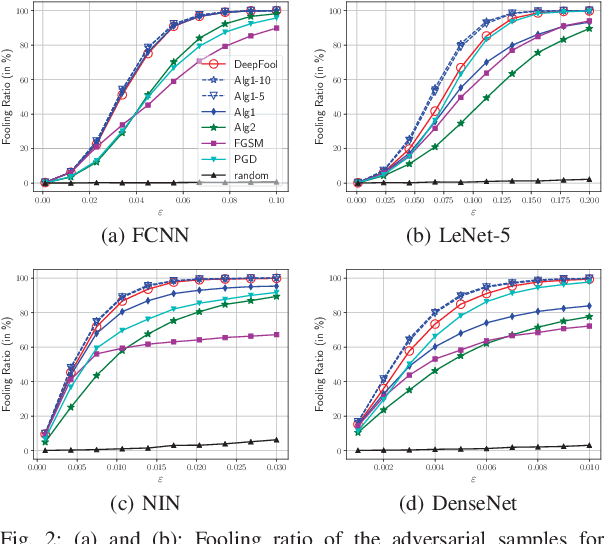
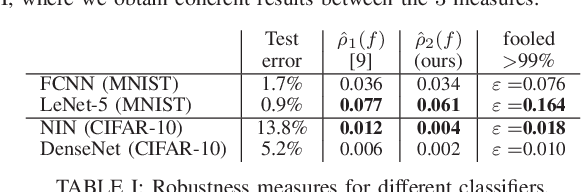
It has been observed that deep learning architectures tend to make erroneous decisions with high reliability for particularly designed adversarial instances. In this work, we show that the perturbation analysis of these architectures provides a framework for generating adversarial instances by convex programming which, for classification tasks, is able to recover variants of existing non-adaptive adversarial methods. The proposed framework can be used for the design of adversarial noise under various desirable constraints and different types of networks. Moreover, this framework is capable of explaining various existing adversarial methods and can be used to derive new algorithms as well. Furthermore, we make use of these results to obtain novel algorithms. Experiments show the competitive performance of the obtained solutions, in terms of fooling ratio, when benchmarked with well-known adversarial methods.
* Accepted in ASILOMAR 2018
Learning the Localization Function: Machine Learning Approach to Fingerprinting Localization
Mar 21, 2018
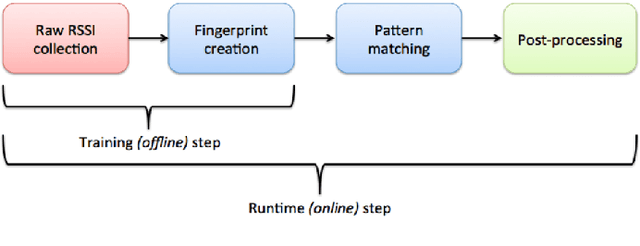
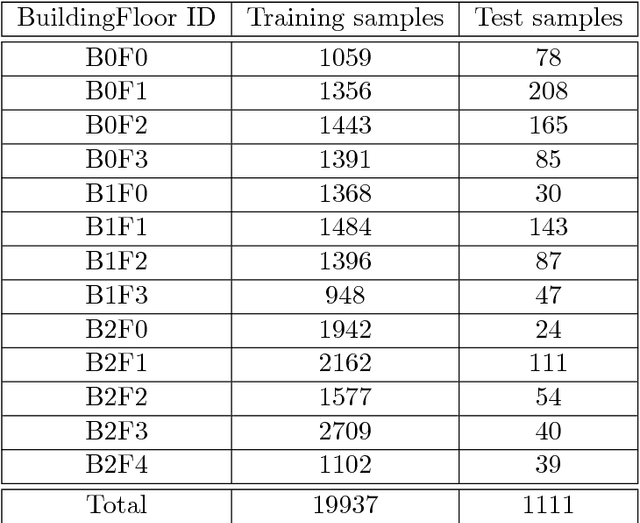
Considered as a data-driven approach, Fingerprinting Localization Solutions (FPSs) enjoy huge popularity due to their good performance and minimal environment information requirement. This papers addresses applications of artificial intelligence to solve two problems in Received Signal Strength Indicator (RSSI) based FPS, first the cumbersome training database construction and second the extrapolation of fingerprinting algorithm for similar buildings with slight environmental changes. After a concise overview of deep learning design techniques, two main techniques widely used in deep learning are exploited for the above mentioned issues namely data augmentation and transfer learning. We train a multi-layer neural network that learns the mapping from the observations to the locations. A data augmentation method is proposed to increase the training database size based on the structure of RSSI measurements and hence reducing effectively the amount of training data. Then it is shown experimentally how a model trained for a particular building can be transferred to a similar one by fine tuning with significantly smaller training numbers. The paper implicitly discusses the new guidelines to consider about deep learning designs when they are employed in a new application context.
A Discontinuous Neural Network for Non-Negative Sparse Approximation
Mar 21, 2016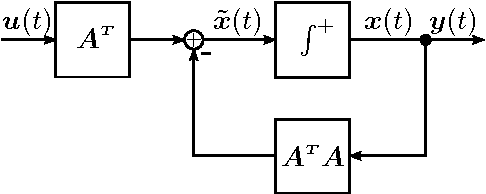
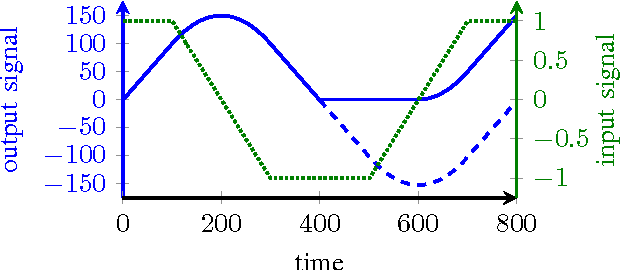

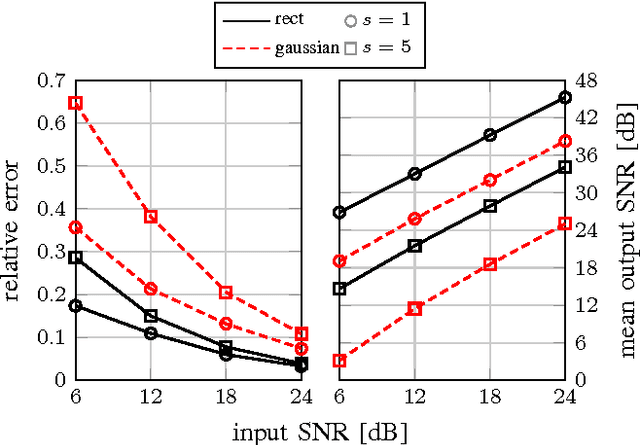
This paper investigates a discontinuous neural network which is used as a model of the mammalian olfactory system and can more generally be applied to solve non-negative sparse approximation problems. By inherently limiting the systems integrators to having non-negative outputs, the system function becomes discontinuous since the integrators switch between being inactive and being active. It is shown that the presented network converges to equilibrium points which are solutions to general non-negative least squares optimization problems. We specify a Caratheodory solution and prove that the network is stable, provided that the system matrix has full column-rank. Under a mild condition on the equilibrium point, we show that the network converges to its equilibrium within a finite number of switches. Two applications of the neural network are shown. Firstly, we apply the network as a model of the olfactory system and show that in principle it may be capable of performing complex sparse signal recovery tasks. Secondly, we generalize the application to include non-negative sparse approximation problems and compare the recovery performance to a classical non-negative basis pursuit denoising algorithm. We conclude that the recovery performance differs only marginally from the classical algorithm, while the neural network has the advantage that no performance critical regularization parameter has to be chosen prior to recovery.