 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbation Analysis of Learning Algorithms: A Unifying Perspective on Generation of Adversarial Examples
Paper and Code
Dec 15, 2018
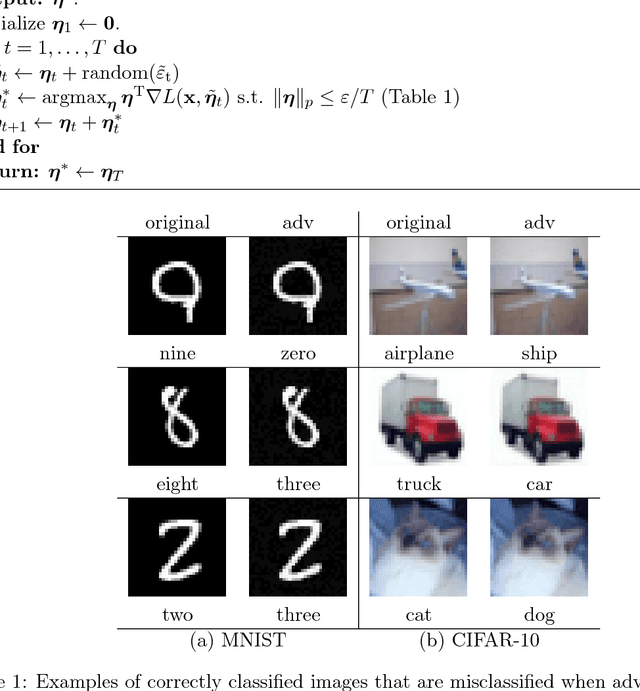


Despite the tremendous success of deep neural networks in various learning problems, it has been observed that adding an intentionally designed adversarial perturbation to inputs of these architectures leads to erroneous classification with high confidence in the prediction. In this work, we propose a general framework based on the perturbation analysis of learning algorithms which consists of convex programming and is able to recover many current adversarial attacks as special cases. The framework can be used to propose novel attacks against learning algorithms for classification and regression tasks under various new constraints with closed form solutions in many instances. In particular we derive new attacks against classification algorithms which are shown to achieve comparable performances to notable existing attacks. The framework is then used to generate adversarial perturbations for regression tasks which include single pixel and single subset attacks. By applying this method to autoencoding and image colorization tasks, it is shown that adversarial perturbations can effectively perturb the output of regression tasks as well.