Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-kernel Attention for Efficient and Robust Brain Lesion Segmentation
Aug 14, 2023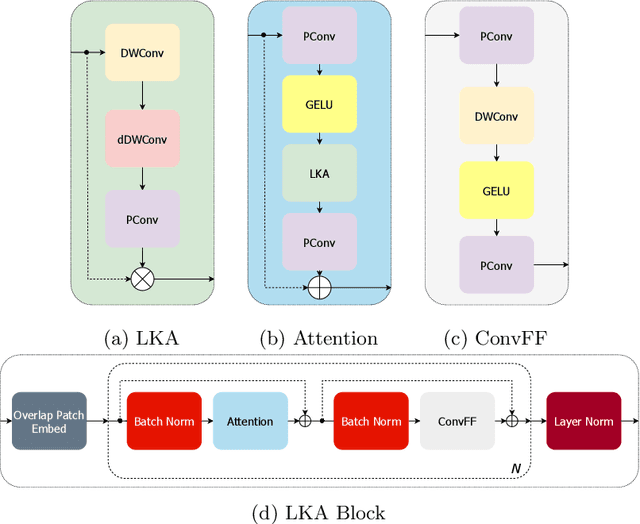

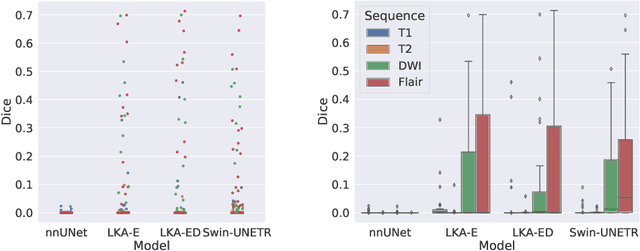
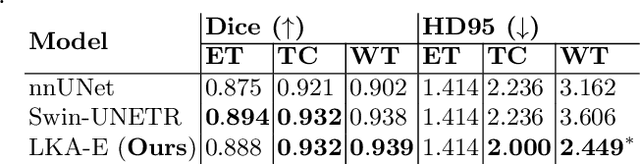
Vision transformers are effective deep learning models for vision tasks, including medical image segmentation. However, they lack efficiency and translational invariance, unlike convolutional neural networks (CNNs). To model long-range interactions in 3D brain lesion segmentation, we propose an all-convolutional transformer block variant of the U-Net architecture. We demonstrate that our model provides the greatest compromise in three factors: performance competitive with the state-of-the-art; parameter efficiency of a CNN; and the favourable inductive biases of a transformer. Our public implementation is available at https://github.com/liamchalcroft/MDUNet .
Via