 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Dexterous Manipulation with Concept Networks
Sep 20, 2017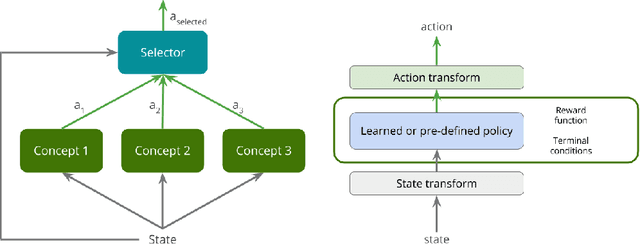
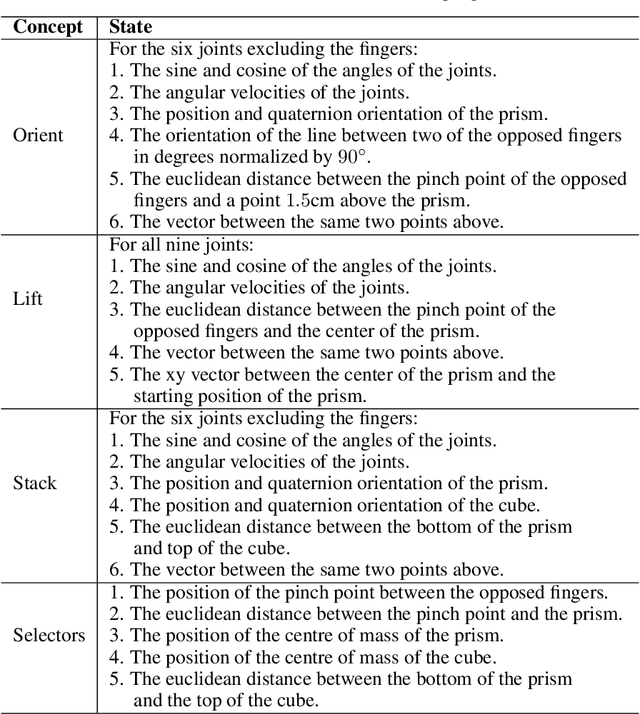
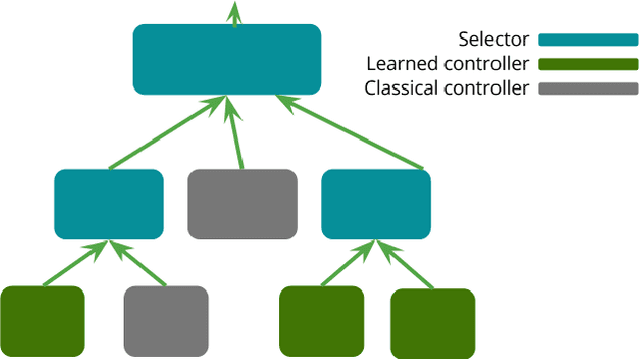

Deep reinforcement learning yields great results for a large array of problems, but models are generally retrained anew for each new problem to be solved. Prior learning and knowledge are difficult to incorporate when training new models, requiring increasingly longer training as problems become more complex. This is especially problematic for problems with sparse rewards. We provide a solution to these problems by introducing Concept Network Reinforcement Learning (CNRL), a framework which allows us to decompose problems using a multi-level hierarchy. Concepts in a concept network are reusable, and flexible enough to encapsulate feature extractors, skills, or other concept networks. With this hierarchical learning approach, deep reinforcement learning can be used to solve complex tasks in a modular way, through problem decomposition. We demonstrate the strength of CNRL by training a model to grasp a rectangular prism and precisely stack it on top of a cube using a gripper on a Kinova JACO arm, simulated in MuJoCo. Our experiments show that our use of hierarchy results in a 45x reduction in environment interactions compared to the state-of-the-art on this task.
Using a Dynamic Neural Field Model to Explore a Direct Collicular Inhibition Account of Inhibition of Return
Jul 22, 2013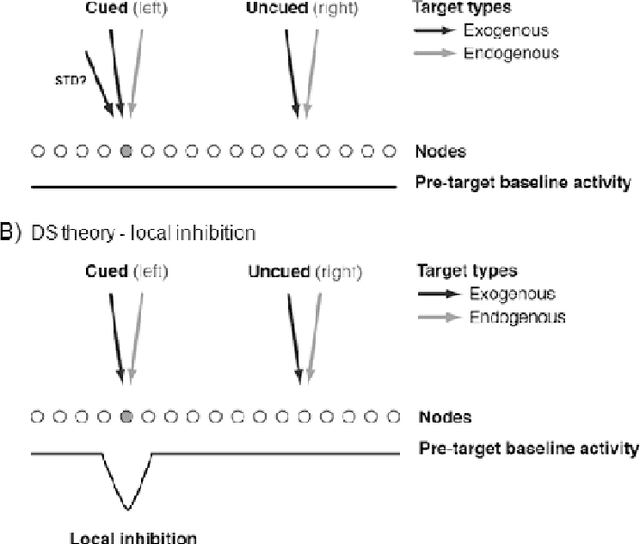
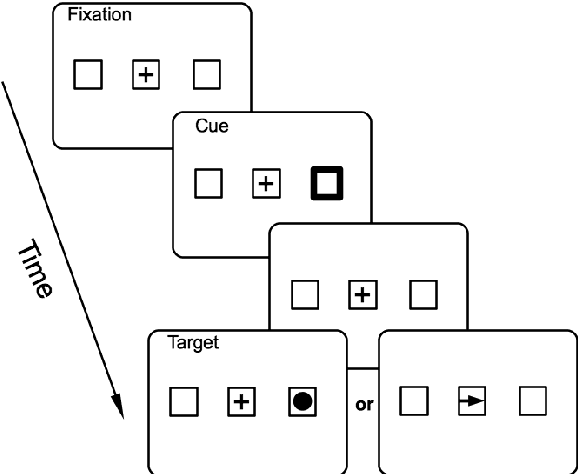
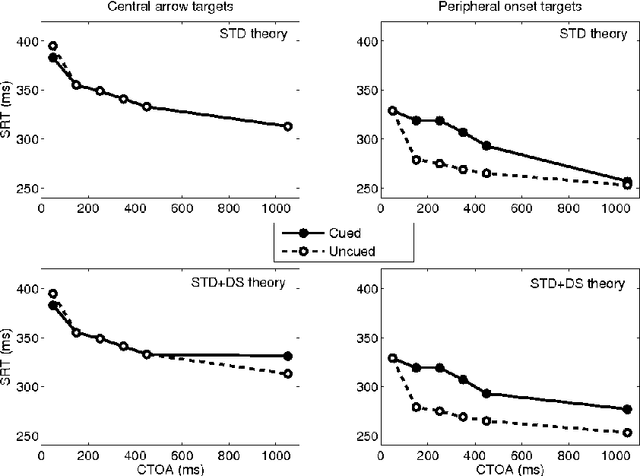
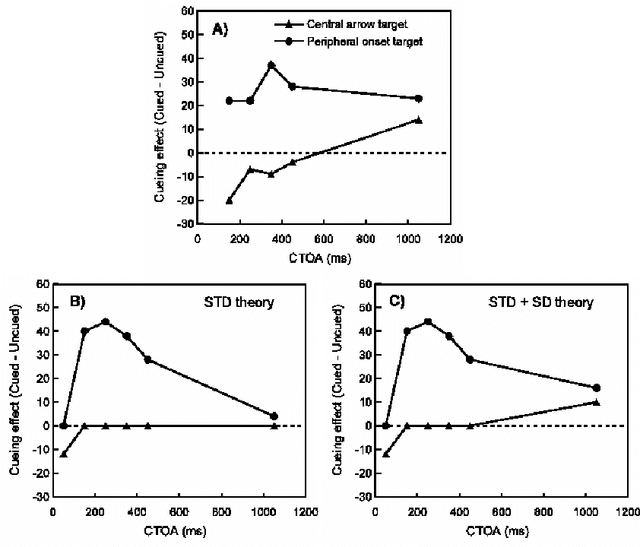
When the interval between a transient ash of light (a "cue") and a second visual response signal (a "target") exceeds at least 200ms, responding is slowest in the direction indicated by the first signal. This phenomenon is commonly referred to as inhibition of return (IOR). The dynamic neural field model (DNF) has proven to have broad explanatory power for IOR, effectively capturing many empirical results. Previous work has used a short-term depression (STD) implementation of IOR, but this approach fails to explain many behavioral phenomena observed in the literature. Here, we explore a variant model of IOR involving a combination of STD and delayed direct collicular inhibition. We demonstrate that this hybrid model can better reproduce established behavioural results. We use the results of this model to propose several experiments that would yield particularly valuable insight into the nature of the neurophysiological mechanisms underlying IOR.