 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Neural Control for Non-Affine Control Systems with Differentiable Control Barrier Functions
Sep 06, 2023



This paper addresses the problem of safety-critical control for non-affine control systems. It has been shown that optimizing quadratic costs subject to state and control constraints can be sub-optimally reduced to a sequence of quadratic programs (QPs) by using Control Barrier Functions (CBFs). Our recently proposed High Order CBFs (HOCBFs) can accommodate constraints of arbitrary relative degree. The main challenges in this approach are that it requires affine control dynamics and the solution of the CBF-based QP is sub-optimal since it is solved point-wise. To address these challenges, we incorporate higher-order CBFs into neural ordinary differential equation-based learning models as differentiable CBFs to guarantee safety for non-affine control systems. The differentiable CBFs are trainable in terms of their parameters, and thus, they can address the conservativeness of CBFs such that the system state will not stay unnecessarily far away from safe set boundaries. Moreover, the imitation learning model is capable of learning complex and optimal control policies that are usually intractable online. We illustrate the effectiveness of the proposed framework on LiDAR-based autonomous driving and compare it with existing methods.
Learned Risk Metric Maps for Kinodynamic Systems
Feb 28, 2023



We present Learned Risk Metric Maps (LRMM) for real-time estimation of coherent risk metrics of high dimensional dynamical systems operating in unstructured, partially observed environments. LRMM models are simple to design and train -- requiring only procedural generation of obstacle sets, state and control sampling, and supervised training of a function approximator -- which makes them broadly applicable to arbitrary system dynamics and obstacle sets. In a parallel autonomy setting, we demonstrate the model's ability to rapidly infer collision probabilities of a fast-moving car-like robot driving recklessly in an obstructed environment; allowing the LRMM agent to intervene, take control of the vehicle, and avoid collisions. In this time-critical scenario, we show that LRMMs can evaluate risk metrics 20-100x times faster than alternative safety algorithms based on control barrier functions (CBFs) and Hamilton-Jacobi reachability (HJ-reach), leading to 5-15\% fewer obstacle collisions by the LRMM agent than CBFs and HJ-reach. This performance improvement comes in spite of the fact that the LRMM model only has access to local/partial observation of obstacles, whereas the CBF and HJ-reach agents are granted privileged/global information. We also show that our model can be equally well trained on a 12-dimensional quadrotor system operating in an obstructed indoor environment. The LRMM codebase is provided at https://github.com/mit-drl/pyrmm.
Learning Emergent Discrete Message Communication for Cooperative Reinforcement Learning
Feb 24, 2021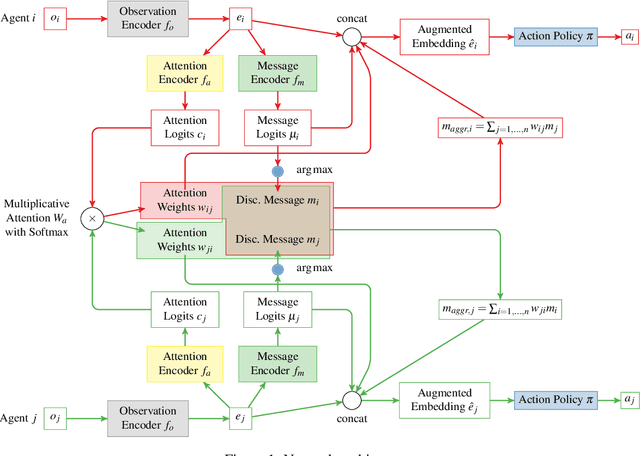
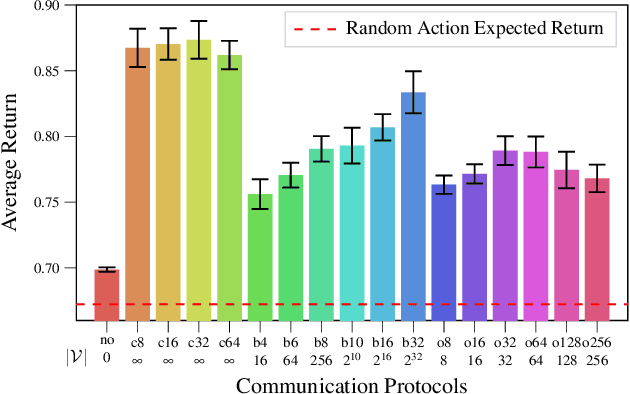

Communication is a important factor that enables agents work cooperatively in multi-agent reinforcement learning (MARL). Most previous work uses continuous message communication whose high representational capacity comes at the expense of interpretability. Allowing agents to learn their own discrete message communication protocol emerged from a variety of domains can increase the interpretability for human designers and other agents.This paper proposes a method to generate discrete messages analogous to human languages, and achieve communication by a broadcast-and-listen mechanism based on self-attention. We show that discrete message communication has performance comparable to continuous message communication but with much a much smaller vocabulary size.Furthermore, we propose an approach that allows humans to interactively send discrete messages to agents.
Deep Implicit Coordination Graphs for Multi-agent Reinforcement Learning
Jun 19, 2020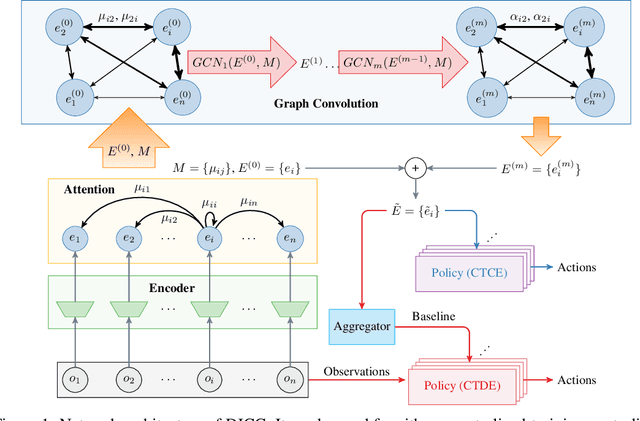
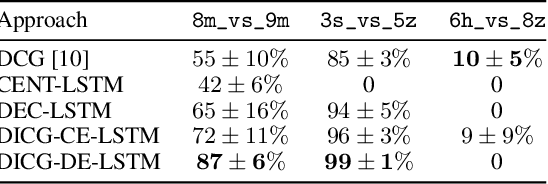
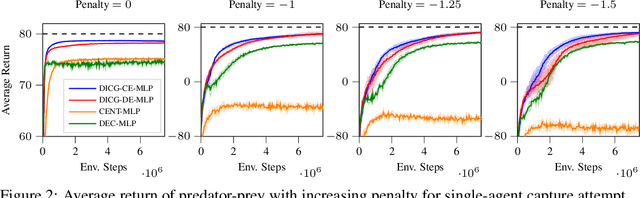
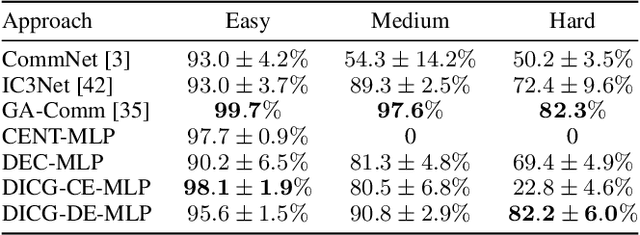
Multi-agent reinforcement learning (MARL) requires coordination to efficiently solve certain tasks. Fully centralized control is often infeasible in such domains due to the size of joint action spaces. Coordination graph based formalization allows reasoning about the joint action based on the structure of interactions. However, they often require domain expertise in their design. This paper introduces the deep implicit coordination graph (DICG) architecture for such scenarios. DICG consists of a module for inferring the dynamic coordination graph structure which is then used by a graph neural network based module to learn to implicitly reason about the joint actions or values. DICG allows learning the tradeoff between full centralization and decentralization via standard actor-critic methods to significantly improve coordination for domains with large number of agents. We apply DICG to both centralized-training-centralized-execution and centralized-training-decentralized-execution regimes. We demonstrate that DICG solves the relative overgeneralization pathology in predatory-prey tasks as well as outperforms various MARL baselines on the challenging StarCraft II Multi-agent Challenge (SMAC) and traffic junction environments.