 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREF-XAI: Preference-Based Personalized Rule Explanations of Black-Box Machine Learning Models
Apr 21, 2026Explainable artificial intelligence (XAI) has predominantly focused on generating model-centric explanations that approximate the behavior of black-box models. However, such explanations often overlook a fundamental aspect of interpretability: different users require different explanations depending on their goals, preferences, and cognitive constraints. Although recent work has explored user-centric and personalized explanations, most existing approaches rely on heuristic adaptations or implicit user modeling, lacking a principled framework for representing and learning individual preferences. In this paper, we consider Preference-Based Explainable Artificial Intelligence (PREF-XAI), a novel perspective that reframes explanation as a preference-driven decision problem. Within PREF-XAI, explanations are not treated as fixed outputs, but as alternatives to be evaluated and selected according to user-specific criteria. In the PREF-XAI perspective, here we propose a methodology that combines rule-based explanations with formal preference learning. User preferences are elicited through a ranking of a small set of candidate explanations and modeled via an additive utility function inferred using robust ordinal regression. Experimental results on real-world datasets show that PREF-XAI can accurately reconstruct user preferences from limited feedback, identify highly relevant explanations, and discover novel explanatory rules not initially considered by the user. Beyond the proposed methodology, this work establishes a connection between XAI and preference learning, opening new directions for interactive and adaptive explanation systems.
An Explainable and Interpretable Composite Indicator Based on Decision Rules
Jun 16, 2025Composite indicators are widely used to score or classify units evaluated on multiple criteria. Their construction involves aggregating criteria evaluations, a common practice in Multiple Criteria Decision Aiding (MCDA). In MCDA, various methods have been proposed to address key aspects of multiple criteria evaluations, such as the measurement scales of the criteria, the degree of acceptable compensation between them, and their potential interactions. However, beyond producing a final score or classification, it is essential to ensure the explainability and interpretability of results as well as the procedure's transparency. This paper proposes a method for constructing explainable and interpretable composite indicators using "if..., then..." decision rules. We consider the explainability and interpretability of composite indicators in four scenarios: (i) decision rules explain numerical scores obtained from an aggregation of numerical codes corresponding to ordinal qualifiers; (ii) an obscure numerical composite indicator classifies units into quantiles; (iii) given preference information provided by a Decision Maker in the form of classifications of some reference units, a composite indicator is constructed using decision rules; (iv) the classification of a set of units results from the application of an MCDA method and is explained by decision rules. To induce the rules from scored or classified units, we apply the Dominance-based Rough Set Approach. The resulting decision rules relate the class assignment or unit's score to threshold conditions on values of selected indicators in an intelligible way, clarifying the underlying rationale. Moreover, they serve to recommend composite indicator assessment for new units of interest.
Representation of preferences for multiple criteria decision aiding in a new seven-valued logic
May 31, 2024The seven-valued logic considered in this paper naturally arises within the rough set framework, allowing to distinguish vagueness due to imprecision from ambiguity due to coarseness. Recently, we discussed its utility for reasoning about data describing multi-attribute classification of objects. We also showed that this logic contains, as a particular case, the celebrated Belnap four-valued logic. Here, we present how the seven-valued logic, as well as the other logics that derive from it, can be used to represent preferences in the domain of Multiple Criteria Decision Aiding (MCDA). In particular, we propose new forms of outranking and value function preference models that aggregate multiple criteria taking into account imperfect preference information. We demonstrate that our approach effectively addresses common challenges in preference modeling for MCDA, such as uncertainty, imprecision, and ill-determination of performances and preferences. To this end, we present a specific procedure to construct a seven-valued preference relation and use it to define recommendations that consider robustness concerns by utilizing multiple outranking or value functions representing the decision maker s preferences. Moreover, we discuss the main properties of the proposed seven-valued preference structure and compare it with current approaches in MCDA, such as ordinal regression, robust ordinal regression, stochastic multiattribute acceptability analysis, stochastic ordinal regression, and so on. We illustrate and discuss the application of our approach using a didactic example. Finally, we propose directions for future research and potential applications of the proposed methodology.
FRRI: a novel algorithm for fuzzy-rough rule induction
Mar 07, 2024Interpretability is the next frontier in machine learning research. In the search for white box models - as opposed to black box models, like random forests or neural networks - rule induction algorithms are a logical and promising option, since the rules can easily be understood by humans. Fuzzy and rough set theory have been successfully applied to this archetype, almost always separately. As both approaches to rule induction involve granular computing based on the concept of equivalence classes, it is natural to combine them. The QuickRules\cite{JensenCornelis2009} algorithm was a first attempt at using fuzzy rough set theory for rule induction. It is based on QuickReduct, a greedy algorithm for building decision reducts. QuickRules already showed an improvement over other rule induction methods. However, to evaluate the full potential of a fuzzy rough rule induction algorithm, one needs to start from the foundations. In this paper, we introduce a novel rule induction algorithm called Fuzzy Rough Rule Induction (FRRI). We provide background and explain the workings of our algorithm. Furthermore, we perform a computational experiment to evaluate the performance of our algorithm and compare it to other state-of-the-art rule induction approaches. We find that our algorithm is more accurate while creating small rulesets consisting of relatively short rules. We end the paper by outlining some directions for future work.
Fuzzy granular approximation classifier
Jun 02, 2022
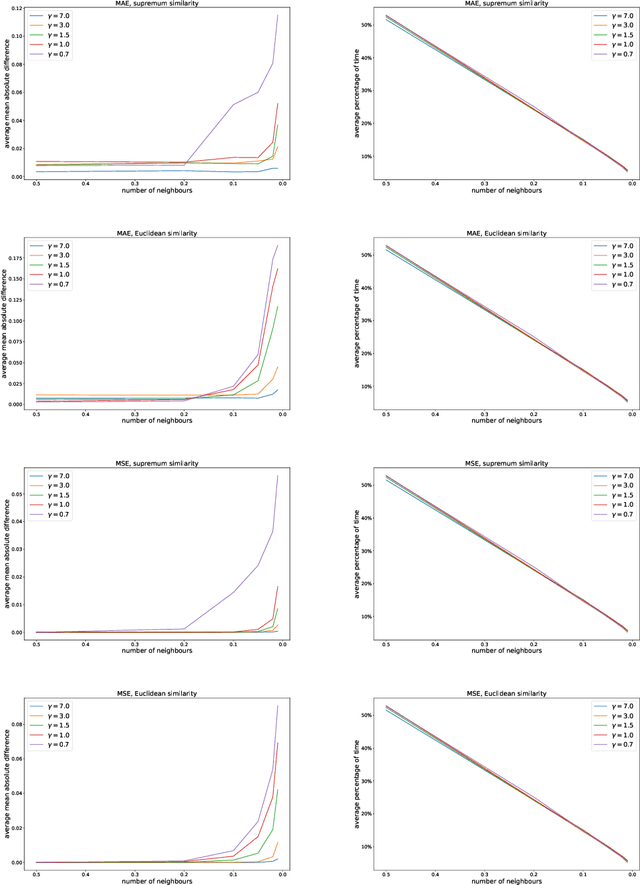
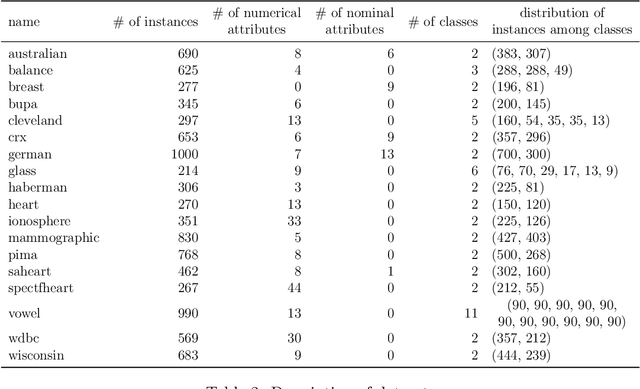
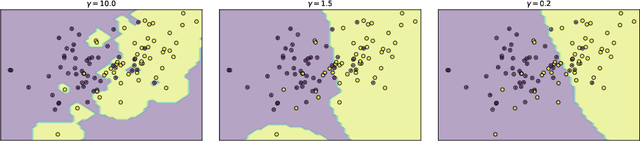
In this article, a new Fuzzy Granular Approximation Classifier (FGAC) is introduced. The classifier is based on the previously introduced concept of the granular approximation and its multi-class classification case. The classifier is instance-based and its biggest advantage is its local transparency i.e., the ability to explain every individual prediction it makes. We first develop the FGAC for the binary classification case and the multi-class classification case and we discuss its variation that includes the Ordered Weighted Average (OWA) operators. Those variations of the FGAC are then empirically compared with other locally transparent ML methods. At the end, we discuss the transparency of the FGAC and its advantage over other locally transparent methods. We conclude that while the FGAC has similar predictive performance to other locally transparent ML models, its transparency can be superior in certain cases.
Multi-class granular approximation by means of disjoint and adjacent fuzzy granules
Feb 15, 2022
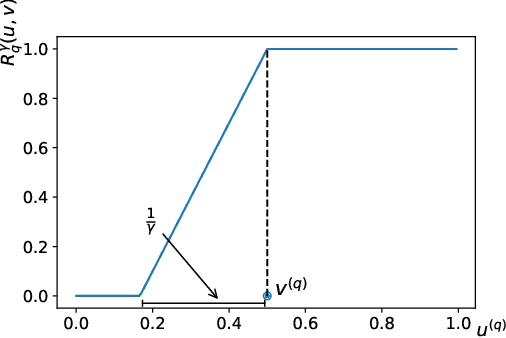
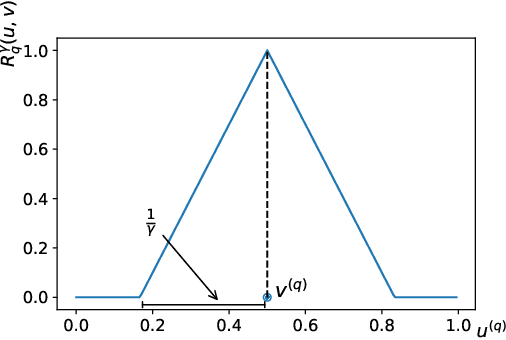
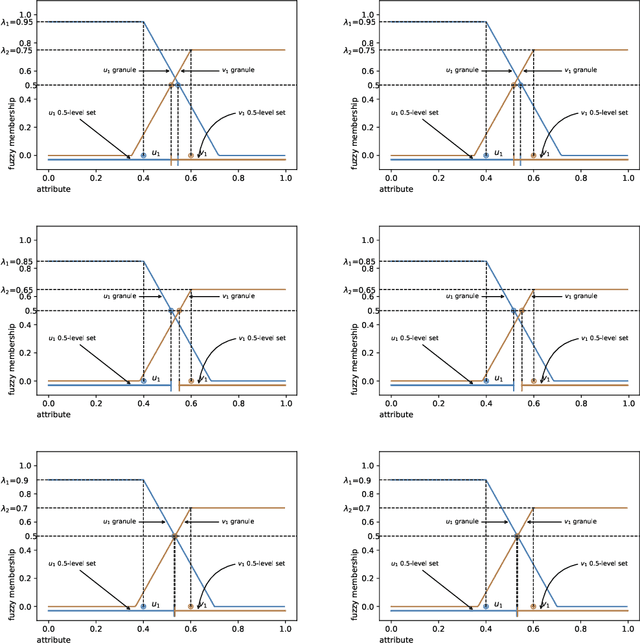
In granular computing, fuzzy sets can be approximated by granularly representable sets that are as close as possible to the original fuzzy set w.r.t. a given closeness measure. Such sets are called granular approximations. In this article, we introduce the concepts of disjoint and adjacent granules and we examine how the new definitions affect the granular approximations. First, we show that the new concepts are important for binary classification problems since they help to keep decision regions separated (disjoint granules) and at the same time to cover as much as possible of the attribute space (adjacent granules). Later, we consider granular approximations for multi-class classification problems leading to the definition of a multi-class granular approximation. Finally, we show how to efficiently calculate multi-class granular approximations for {\L}ukasiewicz fuzzy connectives. We also provide graphical illustrations for a better understanding of the introduced concepts.
A Novel Machine Learning Approach to Data Inconsistency with respect to a Fuzzy Relation
Nov 26, 2021
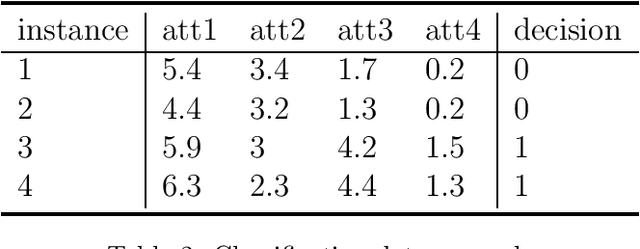
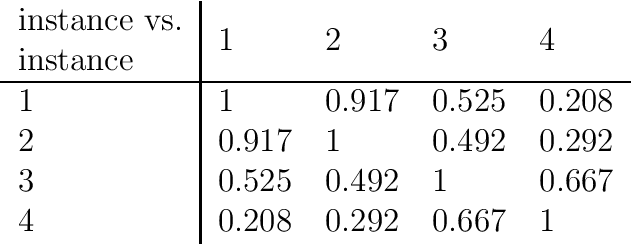

Inconsistency in prediction problems occurs when instances that relate in a certain way on condition attributes, do not follow the same relation on the decision attribute. For example, in ordinal classification with monotonicity constraints, it occurs when an instance dominating another instance on condition attributes has been assigned to a worse decision class. It typically appears as a result of perturbation in data caused by incomplete knowledge (missing attributes) or by random effects that occur during data generation (instability in the assessment of decision attribute values). Inconsistencies with respect to a crisp preorder relation (expressing either dominance or indiscernibility between instances) can be handled using symbolic approaches like rough set theory and by using statistical/machine learning approaches that involve optimization methods. Fuzzy rough sets can also be seen as a symbolic approach to inconsistency handling with respect to a fuzzy relation. In this article, we introduce a new machine learning method for inconsistency handling with respect to a fuzzy preorder relation. The novel approach is motivated by the existing machine learning approach used for crisp relations. We provide statistical foundations for it and develop optimization procedures that can be used to eliminate inconsistencies. The article also proves important properties and contains didactic examples of those procedures.
Recommending Multiple Criteria Decision Analysis Methods with A New Taxonomy-based Decision Support System
Jun 08, 2021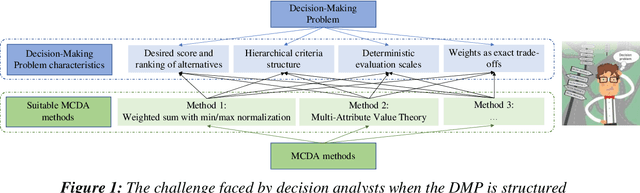
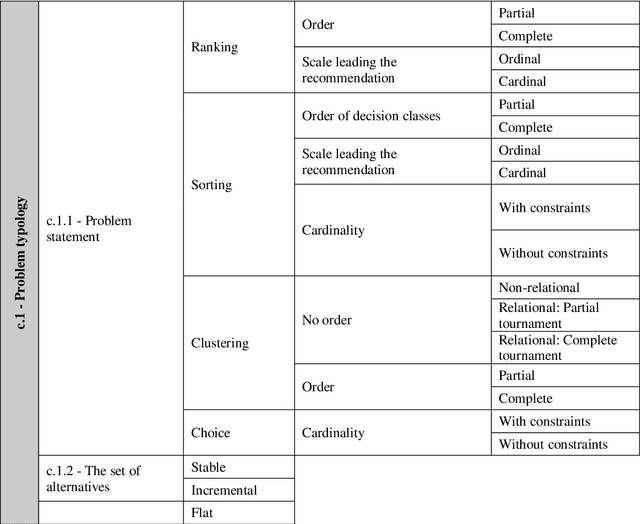

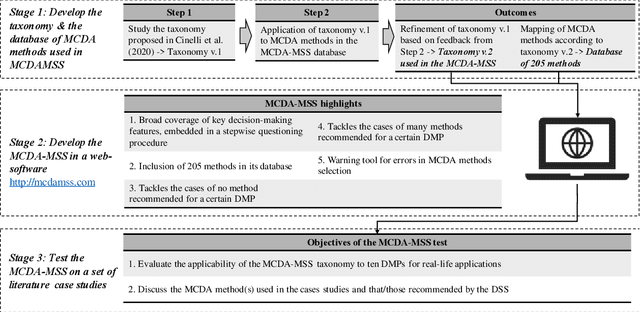
We present the Multiple Criteria Decision Analysis Methods Selection Software (MCDA-MSS). This decision support system helps analysts answering a recurring question in decision science: Which is the most suitable Multiple Criteria Decision Analysis method (or a subset of MCDA methods) that should be used for a given Decision-Making Problem (DMP)?. The MCDA-MSS includes guidance to lead decision-making processes and choose among an extensive collection (over 200) of MCDA methods. These are assessed according to an original comprehensive set of problem characteristics. The accounted features concern problem formulation, preference elicitation and types of preference information, desired features of a preference model, and construction of the decision recommendation. The applicability of the MCDA-MSS has been tested on several case studies. The MCDA-MSS includes the capabilities of (i) covering from very simple to very complex DMPs, (ii) offering recommendations for DMPs that do not match any method from the collection, (iii) helping analysts prioritize efforts for reducing gaps in the description of the DMPs, and (iv) unveiling methodological mistakes that occur in the selection of the methods. A community-wide initiative involving experts in MCDA methodology, analysts using these methods, and decision-makers receiving decision recommendations will contribute to expansion of the MCDA-MSS.