 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGANsfer Learning: Combining labelled and unlabelled data for GAN based data augmentation
Nov 26, 2018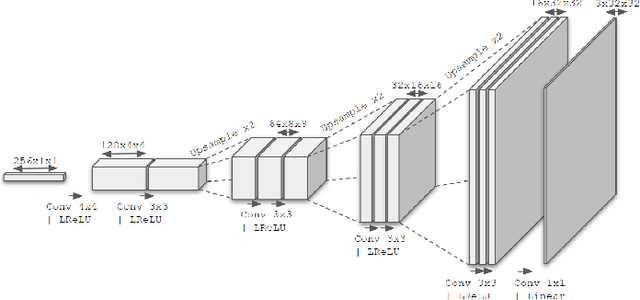
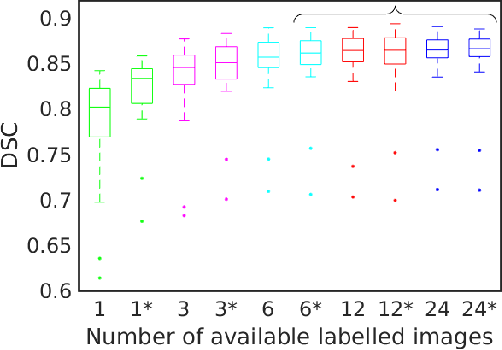
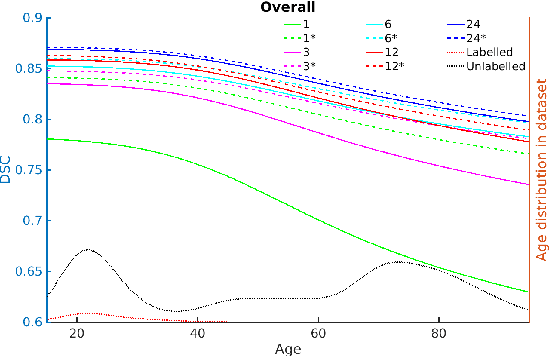
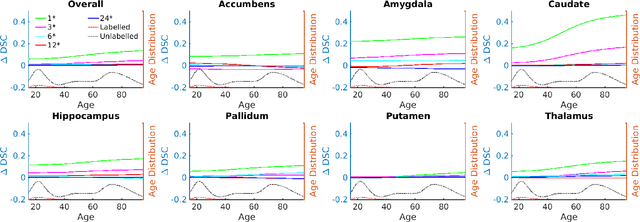
Medical imaging is a domain which suffers from a paucity of manually annotated data for the training of learning algorithms. Manually delineating pathological regions at a pixel level is a time consuming process, especially in 3D images, and often requires the time of a trained expert. As a result, supervised machine learning solutions must make do with small amounts of labelled data, despite there often being additional unlabelled data available. Whilst of less value than labelled images, these unlabelled images can contain potentially useful information. In this paper we propose combining both labelled and unlabelled data within a GAN framework, before using the resulting network to produce images for use when training a segmentation network. We explore the task of deep grey matter multi-class segmentation in an AD dataset and show that the proposed method leads to a significant improvement in segmentation results, particularly in cases where the amount of labelled data is restricted. We show that this improvement is largely driven by a greater ability to segment the structures known to be the most affected by AD, thereby demonstrating the benefits of exposing the system to more examples of pathological anatomical variation. We also show how a shift in domain of the training data from young and healthy towards older and more pathological examples leads to better segmentations of the latter cases, and that this leads to a significant improvement in the ability for the computed segmentations to stratify cases of AD.
GAN Augmentation: Augmenting Training Data using Generative Adversarial Networks
Oct 25, 2018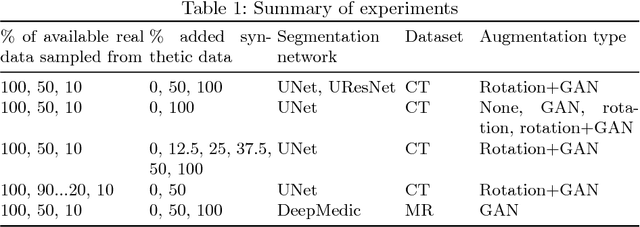
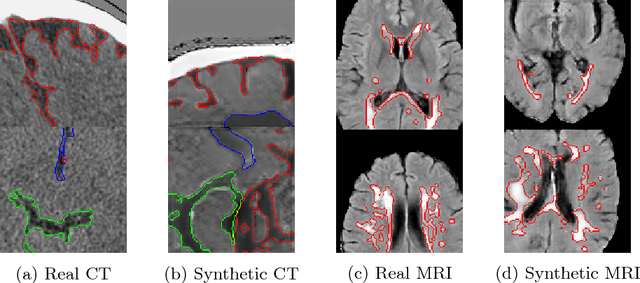
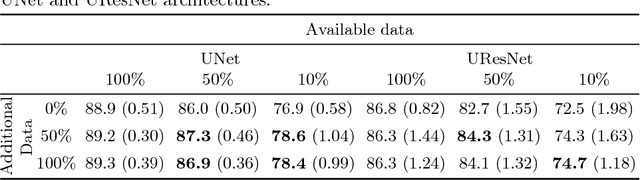
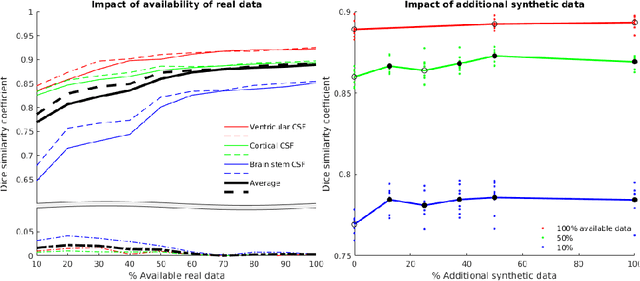
One of the biggest issues facing the use of machine learning in medical imaging is the lack of availability of large, labelled datasets. The annotation of medical images is not only expensive and time consuming but also highly dependent on the availability of expert observers. The limited amount of training data can inhibit the performance of supervised machine learning algorithms which often need very large quantities of data on which to train to avoid overfitting. So far, much effort has been directed at extracting as much information as possible from what data is available. Generative Adversarial Networks (GANs) offer a novel way to unlock additional information from a dataset by generating synthetic samples with the appearance of real images. This paper demonstrates the feasibility of introducing GAN derived synthetic data to the training datasets in two brain segmentation tasks, leading to improvements in Dice Similarity Coefficient (DSC) of between 1 and 5 percentage points under different conditions, with the strongest effects seen fewer than ten training image stacks are available.