 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStroke outcome and evolution prediction from CT brain using a spatiotemporal diffusion autoencoder
Feb 28, 2026Stroke is a major cause of death and disability worldwide. Accurate outcome and evolution prediction has the potential to revolutionize stroke care by individualizing clinical decision-making leading to better outcomes. However, despite a plethora of attempts and the rich data provided by neuroimaging, modelling the ultimate fate of brain tissue remains a challenging task. In this work, we apply recent ideas in the field of diffusion probabilistic models to generate a self-supervised semantically meaningful stroke representation from Computed Tomography (CT) images. We then improve this representation by extending the method to accommodate longitudinal images and the time from stroke onset. The effectiveness of our approach is evaluated on a dataset consisting of 5,824 CT images from 3,573 patients across two medical centers with minimal labels. Comparative experiments show that our method achieves the best performance for predicting next-day severity and functional outcome at discharge.
Concurrent ischemic lesion age estimation and segmentation of CT brain using a Transformer-based network
Jun 21, 2023



The cornerstone of stroke care is expedient management that varies depending on the time since stroke onset. Consequently, clinical decision making is centered on accurate knowledge of timing and often requires a radiologist to interpret Computed Tomography (CT) of the brain to confirm the occurrence and age of an event. These tasks are particularly challenging due to the subtle expression of acute ischemic lesions and the dynamic nature of their appearance. Automation efforts have not yet applied deep learning to estimate lesion age and treated these two tasks independently, so, have overlooked their inherent complementary relationship. To leverage this, we propose a novel end-to-end multi-task transformer-based network optimized for concurrent segmentation and age estimation of cerebral ischemic lesions. By utilizing gated positional self-attention and CT-specific data augmentation, the proposed method can capture long-range spatial dependencies while maintaining its ability to be trained from scratch under low-data regimes commonly found in medical imaging. Furthermore, to better combine multiple predictions, we incorporate uncertainty by utilizing quantile loss to facilitate estimating a probability density function of lesion age. The effectiveness of our model is then extensively evaluated on a clinical dataset consisting of 776 CT images from two medical centers. Experimental results demonstrate that our method obtains promising performance, with an area under the curve (AUC) of 0.933 for classifying lesion ages <=4.5 hours compared to 0.858 using a conventional approach, and outperforms task-specific state-of-the-art algorithms.
Intelligent image synthesis to attack a segmentation CNN using adversarial learning
Sep 24, 2019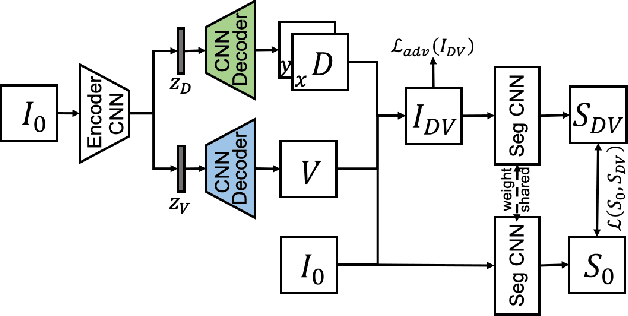
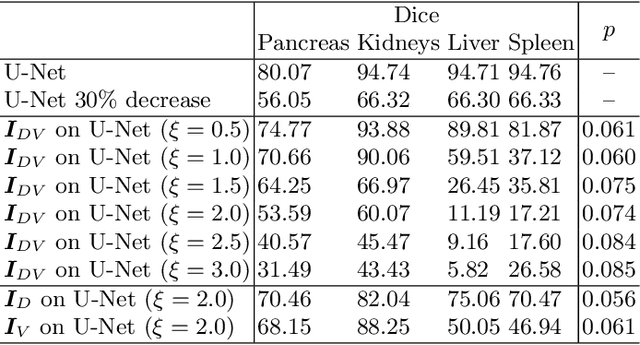
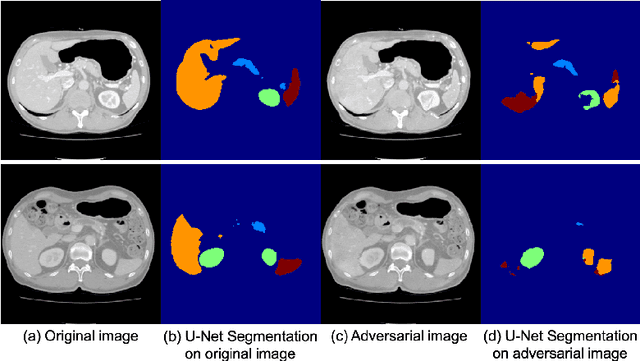
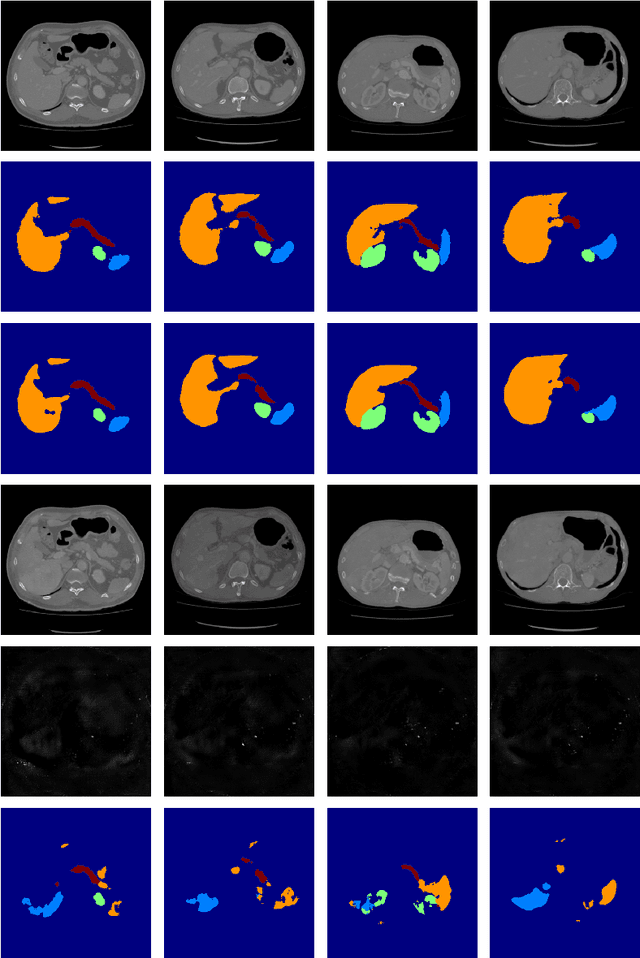
Deep learning approaches based on convolutional neural networks (CNNs) have been successful in solving a number of problems in medical imaging, including image segmentation. In recent years, it has been shown that CNNs are vulnerable to attacks in which the input image is perturbed by relatively small amounts of noise so that the CNN is no longer able to perform a segmentation of the perturbed image with sufficient accuracy. Therefore, exploring methods on how to attack CNN-based models as well as how to defend models against attacks have become a popular topic as this also provides insights into the performance and generalization abilities of CNNs. However, most of the existing work assumes unrealistic attack models, i.e. the resulting attacks were specified in advance. In this paper, we propose a novel approach for generating adversarial examples to attack CNN-based segmentation models for medical images. Our approach has three key features: 1) The generated adversarial examples exhibit anatomical variations (in form of deformations) as well as appearance perturbations; 2) The adversarial examples attack segmentation models so that the Dice scores decrease by a pre-specified amount; 3) The attack is not required to be specified beforehand. We have evaluated our approach on CNN-based approaches for the multi-organ segmentation problem in 2D CT images. We show that the proposed approach can be used to attack different CNN-based segmentation models.
GAN Augmentation: Augmenting Training Data using Generative Adversarial Networks
Oct 25, 2018
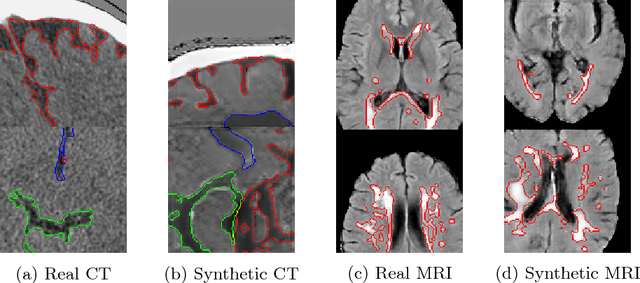
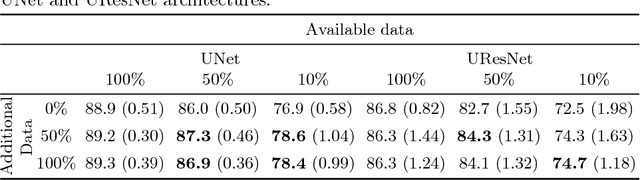
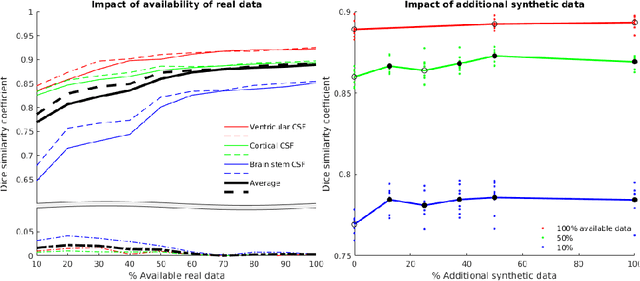
One of the biggest issues facing the use of machine learning in medical imaging is the lack of availability of large, labelled datasets. The annotation of medical images is not only expensive and time consuming but also highly dependent on the availability of expert observers. The limited amount of training data can inhibit the performance of supervised machine learning algorithms which often need very large quantities of data on which to train to avoid overfitting. So far, much effort has been directed at extracting as much information as possible from what data is available. Generative Adversarial Networks (GANs) offer a novel way to unlock additional information from a dataset by generating synthetic samples with the appearance of real images. This paper demonstrates the feasibility of introducing GAN derived synthetic data to the training datasets in two brain segmentation tasks, leading to improvements in Dice Similarity Coefficient (DSC) of between 1 and 5 percentage points under different conditions, with the strongest effects seen fewer than ten training image stacks are available.