 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Approach to Drifting Games, Based on Asymptotically Optimal Potentials
Jul 23, 2022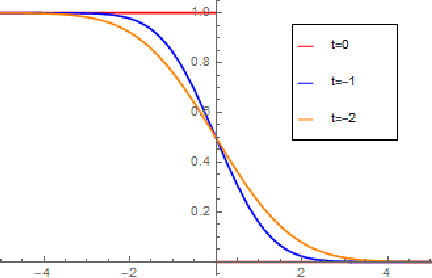
We develop a new approach to drifting games, a class of two-person games with many applications to boosting and online learning settings, including Prediction with Expert Advice and the Hedge game. Our approach involves (a) guessing an asymptotically optimal potential by solving an associated partial differential equation (PDE); then (b) justifying the guess, by proving upper and lower bounds on the final-time loss whose difference scales like a negative power of the number of time steps. The proofs of our potential-based upper bounds are elementary, using little more than Taylor expansion. The proofs of our potential-based lower bounds are also rather elementary, combining Taylor expansion with probabilistic or combinatorial arguments. Most previous work on asymptotically optimal strategies has used potentials obtained by solving a discrete dynamic programming principle; the arguments are complicated by their discrete nature. Our approach is facilitated by the fact that the potentials we use are explicit solutions of PDEs; the arguments are based on basic calculus. Not only is our approach more elementary, but we give new potentials and derive corresponding upper and lower bounds that match each other in the asymptotic regime.
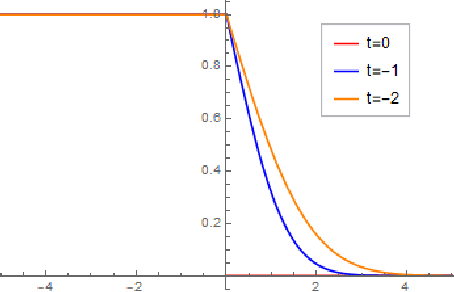
A PDE-Based Analysis of the Symmetric Two-Armed Bernoulli Bandit
Feb 11, 2022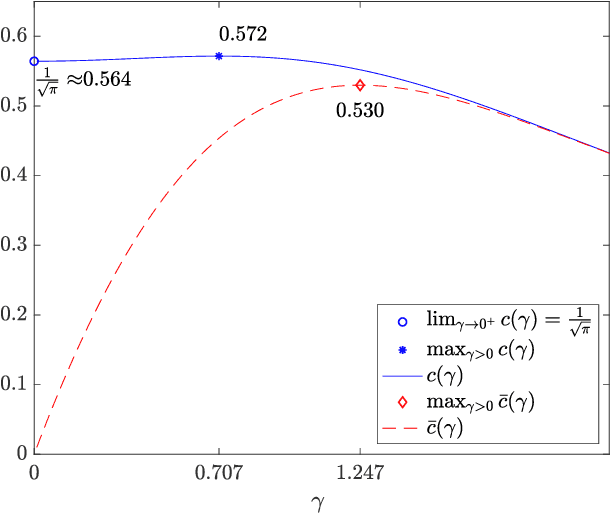
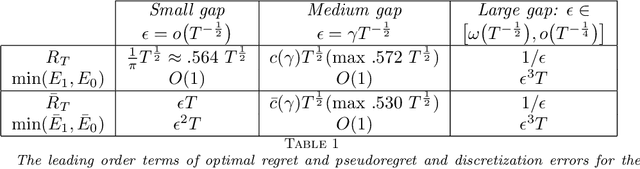
This work addresses a version of the two-armed Bernoulli bandit problem where the sum of the means of the arms is one (the symmetric two-armed Bernoulli bandit). In a regime where the gap between these means goes to zero and the number of prediction periods approaches infinity, we obtain the leading order terms of the expected regret and pseudoregret for this problem by associating each of them with a solution of a linear parabolic partial differential equation. Our results improve upon the previously known results; specifically we explicitly compute the leading order term of the optimal regret and pseudoregret in three different scaling regimes for the gap. Additionally, we obtain new non-asymptotic bounds for any given time horizon.
A PDE Approach to the Prediction of a Binary Sequence with Advice from Two History-Dependent Experts
Jul 24, 2020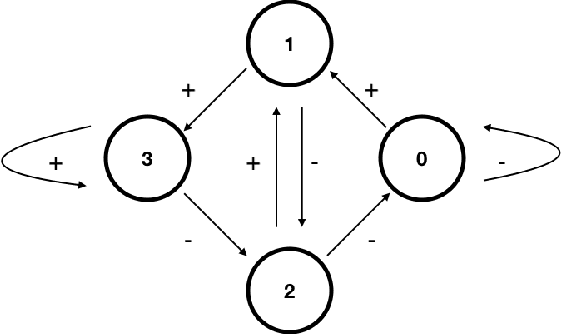

The prediction of a binary sequence is a classic example of online machine learning. We like to call it the 'stock prediction problem,' viewing the sequence as the price history of a stock that goes up or down one unit at each time step. In this problem, an investor has access to the predictions of two or more 'experts,' and strives to minimize her final-time regret with respect to the best-performing expert. Probability plays no role; rather, the market is assumed to be adversarial. We consider the case when there are two history-dependent experts, whose predictions are determined by the d most recent stock moves. Focusing on an appropriate continuum limit and using methods from optimal control, graph theory, and partial differential equations, we discuss strategies for the investor and the adversarial market, and we determine associated upper and lower bounds for the investor's final-time regret. When d is less than 4 our upper and lower bounds coalesce, so the proposed strategies are asymptotically optimal. Compared to other recent applications of partial differential equations to prediction, ours has a new element: there are two timescales, since the recent history changes at every step whereas regret accumulates more slowly.
New Potential-Based Bounds for the Geometric-Stopping Version of Prediction with Expert Advice
Dec 05, 2019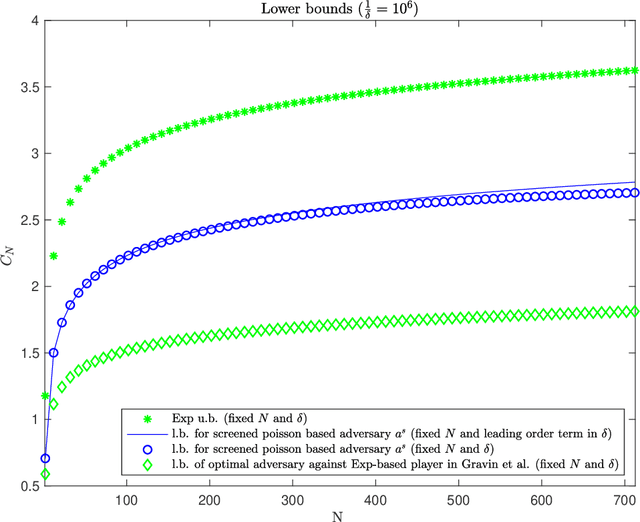
This work addresses the classic machine learning problem of online prediction with expert advice. A potential-based framework for the fixed horizon version of this problem was previously developed using verification arguments from optimal control theory (Kobzar, Kohn and Wang, New Potential-Based Bounds for Prediction with Expert Advice (2019)). This paper extends this framework to the random (geometric) stopping version. Taking advantage of these ideas, we construct potentials for the geometric version of prediction with expert advice from potentials used for the fixed horizon version. This construction leads to new explicit lower and upper bounds associated with specific adversary and player strategies for the geometric problem. We identify regimes where these bounds are state of the art.
New Potential-Based Bounds for Prediction with Expert Advice
Nov 05, 2019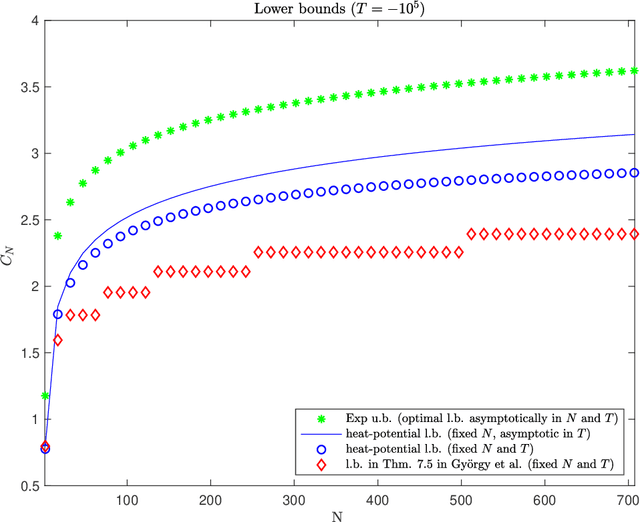
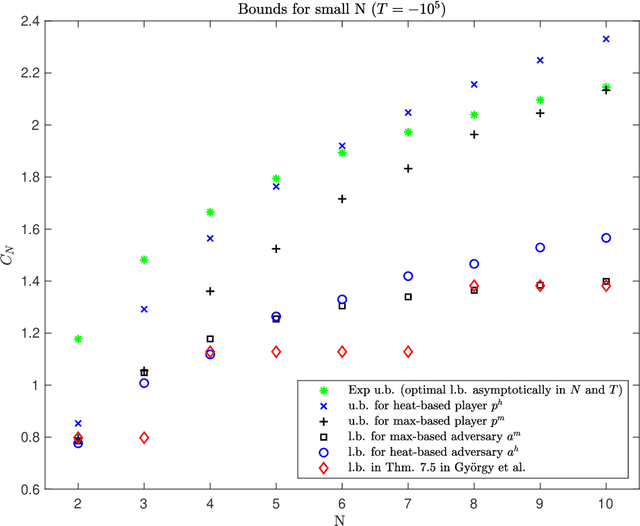
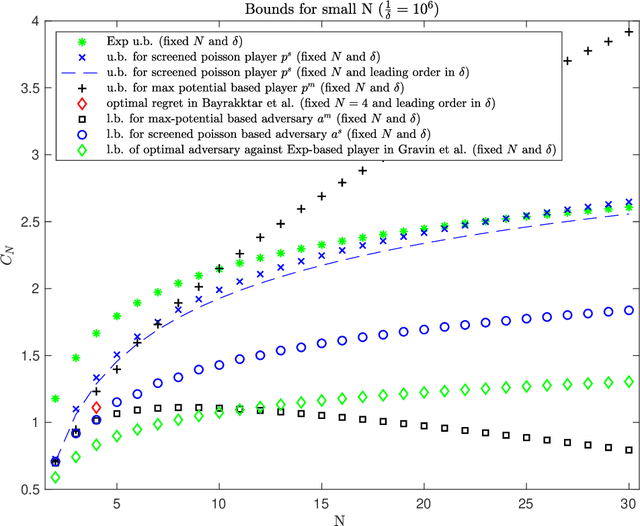
This work addresses the classic machine learning problem of online prediction with expert advice. We consider the finite-horizon version of this zero-sum, two-person game. Using verification arguments from optimal control theory, we view the task of finding better lower and upper bounds on the value of the game (regret) as the problem of finding better sub- and supersolutions of certain partial differential equations (PDEs). These sub- and supersolutions serve as the potentials for player and adversary strategies, which lead to the corresponding bounds. Our techniques extend in a nonasymptotic setting the recent work of Drenska and Kohn (J. Nonlinear Sci. 2019), which showed that the asymptotically optimal value function is the unique solution of an associated nonlinear PDE. To get explicit bounds, we use closed-form solutions of specific PDEs. Our bounds hold for any fixed number of experts and any time-horizon $T$; in certain regimes (which we identify) they improve upon the previous state-of-the-art. For up to three experts, our bounds provide the asymptotically optimal leading order term. Therefore, we provide a continuum perspective on recent work on optimal strategies for the case of $N \leq 3$ experts. We expect that our framework could be used to systematize and advance theory and applications of online learning in other settings as well.
Prediction with Expert Advice: a PDE Perspective
Apr 25, 2019This work addresses a classic problem of online prediction with expert advice. We assume an adversarial opponent, and we consider both the finite-horizon and random-stopping versions of this zero-sum, two-person game. Focusing on an appropriate continuum limit and using methods from optimal control, we characterize the value of the game as the viscosity solution of a certain nonlinear partial differential equation. The analysis also reveals the predictor's and the opponent's minimax optimal strategies. Our work provides, in particular, a continuum perspective on recent work of Gravin, Peres, and Sivan (Proc SODA 2016). Our techniques are similar to those of Kohn and Serfaty (Comm Pure Appl Math 2010), where scaling limits of some two-person games led to elliptic or parabolic PDEs.