 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Structured Dropout
Oct 05, 2022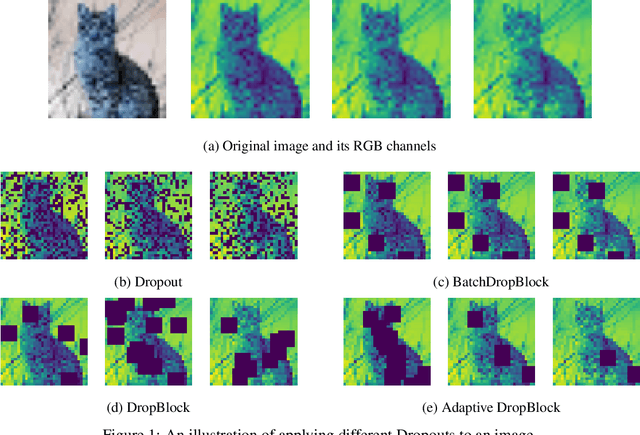


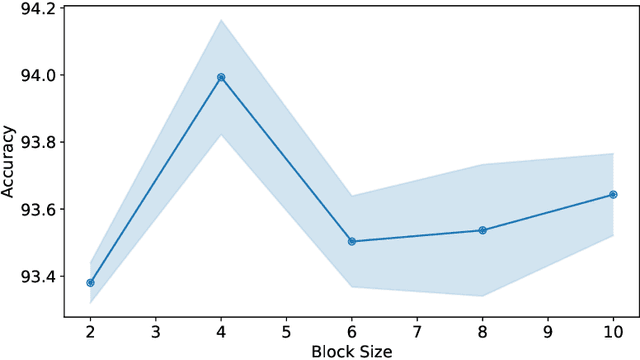
Large neural networks are often overparameterised and prone to overfitting, Dropout is a widely used regularization technique to combat overfitting and improve model generalization. However, unstructured Dropout is not always effective for specific network architectures and this has led to the formation of multiple structured Dropout approaches to improve model performance and, sometimes, reduce the computational resources required for inference. In this work, we revisit structured Dropout comparing different Dropout approaches to natural language processing and computer vision tasks for multiple state-of-the-art networks. Additionally, we devise an approach to structured Dropout we call \textbf{\emph{ProbDropBlock}} which drops contiguous blocks from feature maps with a probability given by the normalized feature salience values. We find that with a simple scheduling strategy the proposed approach to structured Dropout consistently improved model performance compared to baselines and other Dropout approaches on a diverse range of tasks and models. In particular, we show \textbf{\emph{ProbDropBlock}} improves RoBERTa finetuning on MNLI by $0.22\%$, and training of ResNet50 on ImageNet by $0.28\%$.
DARTFormer: Finding The Best Type Of Attention
Oct 02, 2022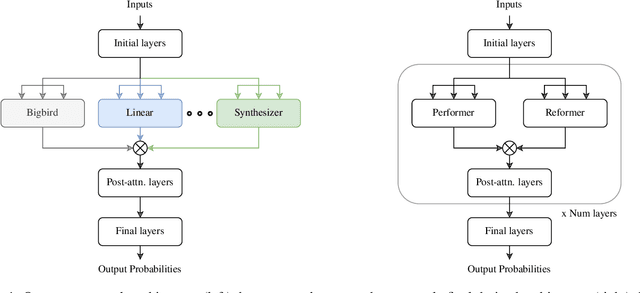

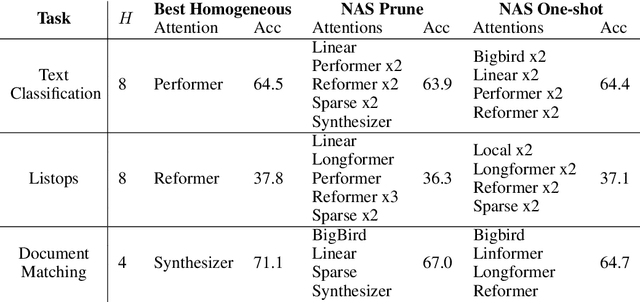
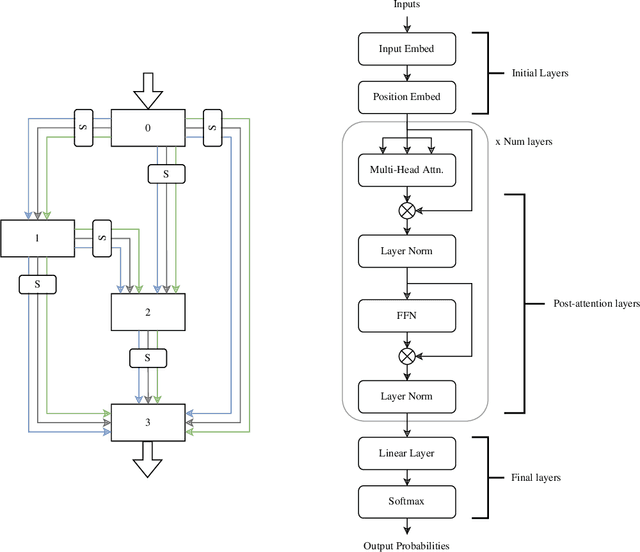
Given the wide and ever growing range of different efficient Transformer attention mechanisms, it is important to identify which attention is most effective when given a task. In this work, we are also interested in combining different attention types to build heterogeneous Transformers. We first propose a DARTS-like Neural Architecture Search (NAS) method to find the best attention for a given task, in this setup, all heads use the same attention (homogeneous models). Our results suggest that NAS is highly effective on this task, and it identifies the best attention mechanisms for IMDb byte level text classification and Listops. We then extend our framework to search for and build Transformers with multiple different attention types, and call them heterogeneous Transformers. We show that whilst these heterogeneous Transformers are better than the average homogeneous models, they cannot outperform the best. We explore the reasons why heterogeneous attention makes sense, and why it ultimately fails.
Wide Attention Is The Way Forward For Transformers
Oct 02, 2022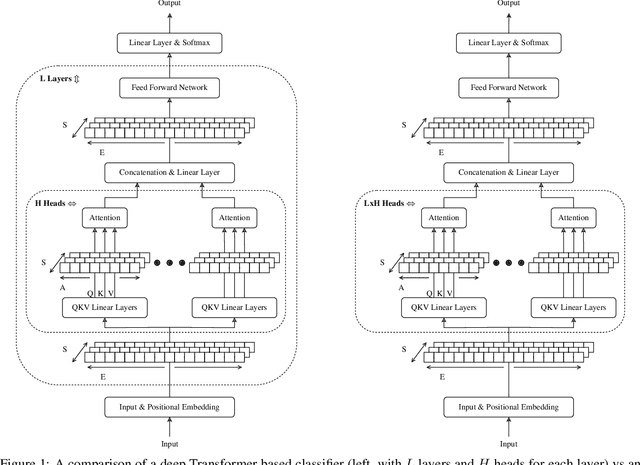

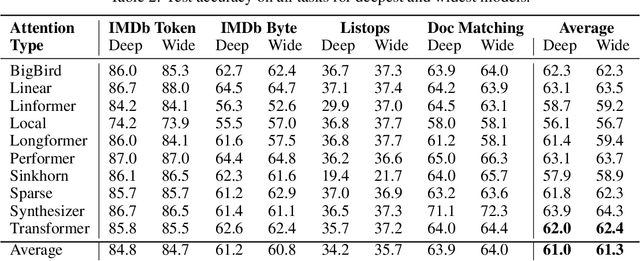
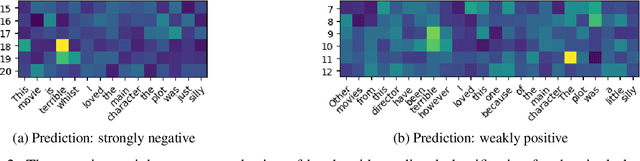
The Transformer is an extremely powerful and prominent deep learning architecture. In this work, we challenge the commonly held belief in deep learning that going deeper is better, and show an alternative design approach that is building wider attention Transformers. We demonstrate that wide single layer Transformer models can compete with or outperform deeper ones in a variety of Natural Language Processing (NLP) tasks when both are trained from scratch. The impact of changing the model aspect ratio on Transformers is then studied systematically. This ratio balances the number of layers and the number of attention heads per layer while keeping the total number of attention heads and all other hyperparameters constant. On average, across 4 NLP tasks and 10 attention types, single layer wide models perform 0.3% better than their deep counterparts. We show an in-depth evaluation and demonstrate how wide models require a far smaller memory footprint and can run faster on commodity hardware, in addition, these wider models are also more interpretable. For example, a single layer Transformer on the IMDb byte level text classification has 3.1x faster inference latency on a CPU than its equally accurate deeper counterpart, and is half the size. Our results suggest that the critical direction for building better Transformers for NLP is their width, and that their depth is less relevant.