 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Structured Dropout
Paper and Code
Oct 05, 2022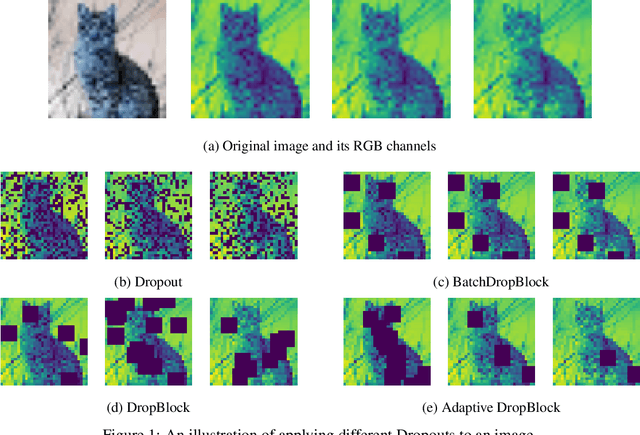


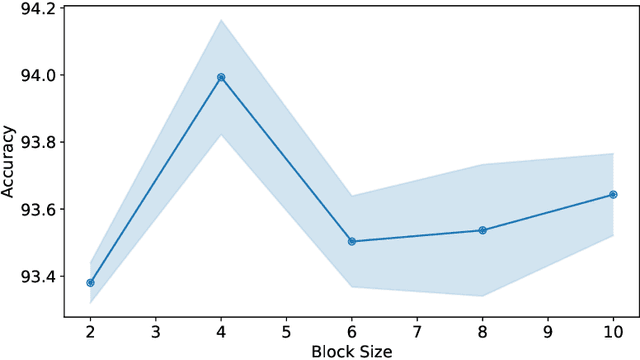
Large neural networks are often overparameterised and prone to overfitting, Dropout is a widely used regularization technique to combat overfitting and improve model generalization. However, unstructured Dropout is not always effective for specific network architectures and this has led to the formation of multiple structured Dropout approaches to improve model performance and, sometimes, reduce the computational resources required for inference. In this work, we revisit structured Dropout comparing different Dropout approaches to natural language processing and computer vision tasks for multiple state-of-the-art networks. Additionally, we devise an approach to structured Dropout we call \textbf{\emph{ProbDropBlock}} which drops contiguous blocks from feature maps with a probability given by the normalized feature salience values. We find that with a simple scheduling strategy the proposed approach to structured Dropout consistently improved model performance compared to baselines and other Dropout approaches on a diverse range of tasks and models. In particular, we show \textbf{\emph{ProbDropBlock}} improves RoBERTa finetuning on MNLI by $0.22\%$, and training of ResNet50 on ImageNet by $0.28\%$.