 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Two-Player Performance Through Single-Player Knowledge Transfer: An Empirical Study on Atari 2600 Games
Oct 22, 2024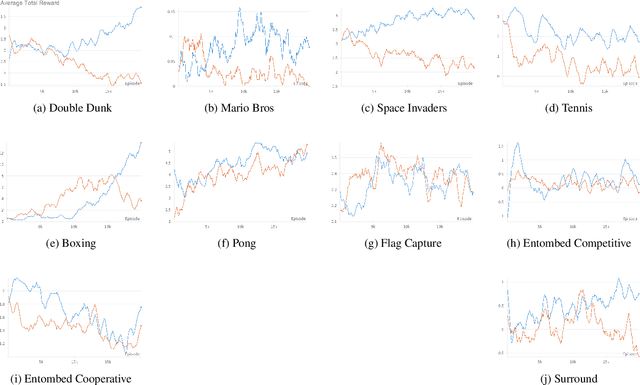



Playing two-player games using reinforcement learning and self-play can be challenging due to the complexity of two-player environments and the possible instability in the training process. We propose that a reinforcement learning algorithm can train more efficiently and achieve improved performance in a two-player game if it leverages the knowledge from the single-player version of the same game. This study examines the proposed idea in ten different Atari 2600 environments using the Atari 2600 RAM as the input state. We discuss the advantages of using transfer learning from a single-player training process over training in a two-player setting from scratch, and demonstrate our results in a few measures such as training time and average total reward. We also discuss a method of calculating RAM complexity and its relationship to performance.
Procedural Content Generation in Games: A Survey with Insights on Emerging LLM Integration
Oct 21, 2024Procedural Content Generation (PCG) is defined as the automatic creation of game content using algorithms. PCG has a long history in both the game industry and the academic world. It can increase player engagement and ease the work of game designers. While recent advances in deep learning approaches in PCG have enabled researchers and practitioners to create more sophisticated content, it is the arrival of Large Language Models (LLMs) that truly disrupted the trajectory of PCG advancement. This survey explores the differences between various algorithms used for PCG, including search-based methods, machine learning-based methods, other frequently used methods (e.g., noise functions), and the newcomer, LLMs. We also provide a detailed discussion on combined methods. Furthermore, we compare these methods based on the type of content they generate and the publication dates of their respective papers. Finally, we identify gaps in the existing academic work and suggest possible directions for future research.
Let the Poem Hit the Rhythm: Using a Byte-Based Transformer for Beat-Aligned Poetry Generation
Jun 14, 2024The intersection between poetry and music provides an interesting case for computational creativity, yet remains relatively unexplored. This paper explores the integration of poetry and music through the lens of beat patterns, investigating whether a byte-based language model can generate words that fit specific beat patterns within the context of poetry. Drawing on earlier studies, we developed a method to train a byte-based transformer model, ByT5, to align poems with beat patterns. The results demonstrate a high level of beat alignment while maintaining semantic coherence. Future work will aim to improve the model's ability to create complete beat-aligned poems.
Autonomous Robot for Disaster Mapping and Victim Localization
Apr 21, 2024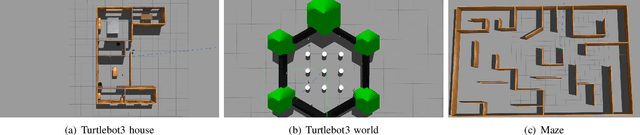
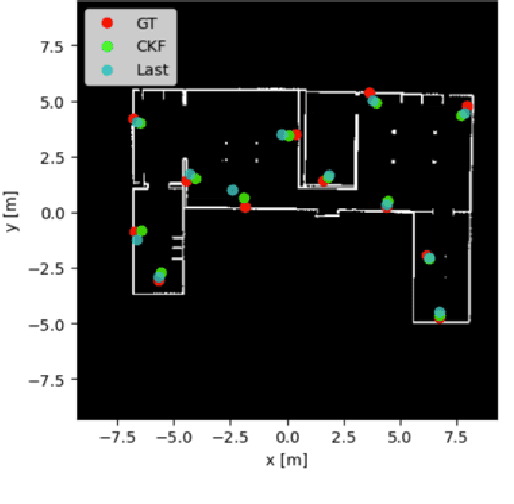
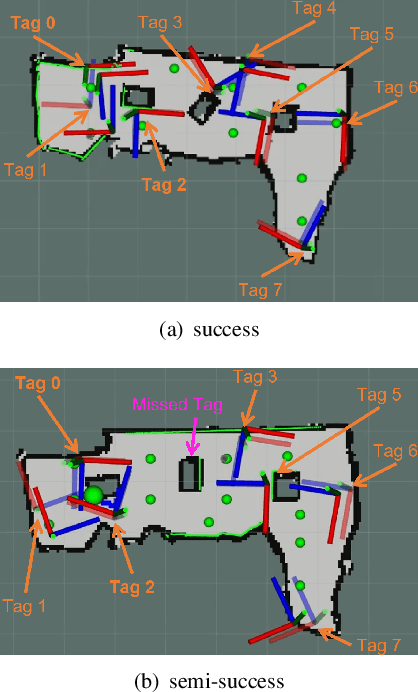

In response to the critical need for effective reconnaissance in disaster scenarios, this research article presents the design and implementation of a complete autonomous robot system using the Turtlebot3 with Robotic Operating System (ROS) Noetic. Upon deployment in closed, initially unknown environments, the system aims to generate a comprehensive map and identify any present 'victims' using AprilTags as stand-ins. We discuss our solution for search and rescue missions, while additionally exploring more advanced algorithms to improve search and rescue functionalities. We introduce a Cubature Kalman Filter to help reduce the mean squared error [m] for AprilTag localization and an information-theoretic exploration algorithm to expedite exploration in unknown environments. Just like turtles, our system takes it slow and steady, but when it's time to save the day, it moves at ninja-like speed! Despite Donatello's shell, he's no slowpoke - he zips through obstacles with the agility of a teenage mutant ninja turtle. So, hang on tight to your shells and get ready for a whirlwind of reconnaissance! Full pipeline code https://github.com/rzhao5659/MRProject/tree/main Exploration code https://github.com/rzhao5659/MRProject/tree/main
ContrastWSD: Enhancing Metaphor Detection with Word Sense Disambiguation Following the Metaphor Identification Procedure
Sep 06, 2023This paper presents ContrastWSD, a RoBERTa-based metaphor detection model that integrates the Metaphor Identification Procedure (MIP) and Word Sense Disambiguation (WSD) to extract and contrast the contextual meaning with the basic meaning of a word to determine whether it is used metaphorically in a sentence. By utilizing the word senses derived from a WSD model, our model enhances the metaphor detection process and outperforms other methods that rely solely on contextual embeddings or integrate only the basic definitions and other external knowledge. We evaluate our approach on various benchmark datasets and compare it with strong baselines, indicating the effectiveness in advancing metaphor detection.
Creative Data Generation: A Review Focusing on Text and Poetry
May 15, 2023The rapid advancement in machine learning has led to a surge in automatic data generation, making it increasingly challenging to differentiate between naturally or human-generated data and machine-generated data. Despite these advancements, the generation of creative data remains a challenge. This paper aims to investigate and comprehend the essence of creativity, both in general and within the context of natural language generation. We review various approaches to creative writing devices and tasks, with a specific focus on the generation of poetry. We aim to shed light on the challenges and opportunities in the field of creative data generation.
Exploring Adaptive MCTS with TD Learning in miniXCOM
Oct 10, 2022



In recent years, Monte Carlo tree search (MCTS) has achieved widespread adoption within the game community. Its use in conjunction with deep reinforcement learning has produced success stories in many applications. While these approaches have been implemented in various games, from simple board games to more complicated video games such as StarCraft, the use of deep neural networks requires a substantial training period. In this work, we explore on-line adaptivity in MCTS without requiring pre-training. We present MCTS-TD, an adaptive MCTS algorithm improved with temporal difference learning. We demonstrate our new approach on the game miniXCOM, a simplified version of XCOM, a popular commercial franchise consisting of several turn-based tactical games, and show how adaptivity in MCTS-TD allows for improved performances against opponents.
Intentional Control of Type I Error over Unconscious Data Distortion: a Neyman-Pearson Approach to Text Classification
Jun 03, 2018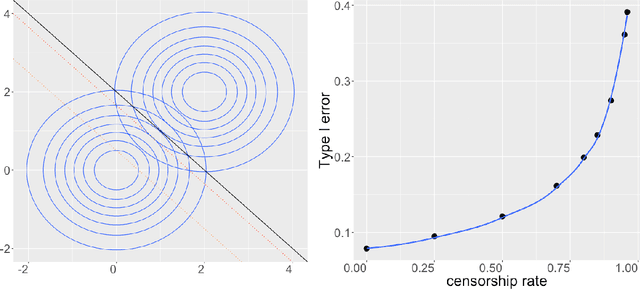

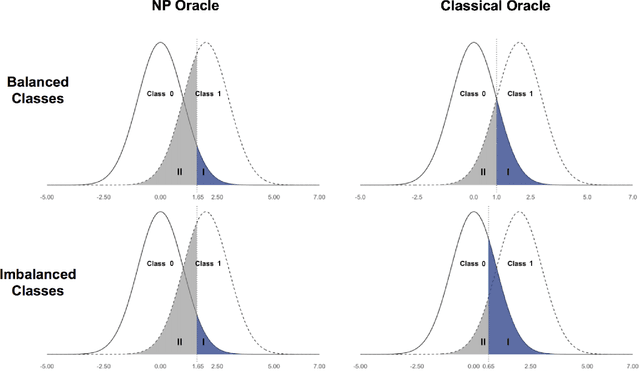

Digital texts have become an increasingly important source of data for social studies. However, textual data from open platforms are vulnerable to manipulation (e.g., censorship and information inflation), often leading to bias in subsequent empirical analysis. This paper investigates the problem of data distortion in text classification when controlling type I error (a relevant textual message is classified as irrelevant) is the priority. The default classical classification paradigm that minimizes the overall classification error can yield an undesirably large type I error, and data distortion exacerbates this situation. As a solution, we propose the Neyman-Pearson (NP) classification paradigm which minimizes type II error under a user-specified type I error constraint. Theoretically, we show that while the classical oracle (i.e., optimal classifier) cannot be recovered under unknown data distortion even if one has the entire post-distortion population, the NP oracle is unaffected by data distortion and can be recovered under the same condition. Empirically, we illustrate the advantage of NP classification methods in a case study that classifies posts about strikes and corruption published on a leading Chinese blogging platform.