 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Two-Player Performance Through Single-Player Knowledge Transfer: An Empirical Study on Atari 2600 Games
Paper and Code
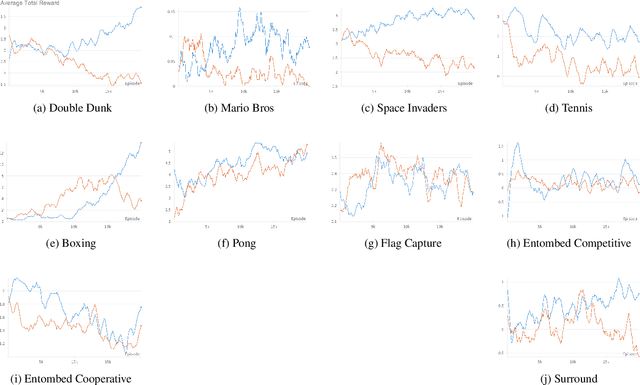



Playing two-player games using reinforcement learning and self-play can be challenging due to the complexity of two-player environments and the possible instability in the training process. We propose that a reinforcement learning algorithm can train more efficiently and achieve improved performance in a two-player game if it leverages the knowledge from the single-player version of the same game. This study examines the proposed idea in ten different Atari 2600 environments using the Atari 2600 RAM as the input state. We discuss the advantages of using transfer learning from a single-player training process over training in a two-player setting from scratch, and demonstrate our results in a few measures such as training time and average total reward. We also discuss a method of calculating RAM complexity and its relationship to performance.