 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentional Control of Type I Error over Unconscious Data Distortion: a Neyman-Pearson Approach to Text Classification
Paper and Code
Jun 03, 2018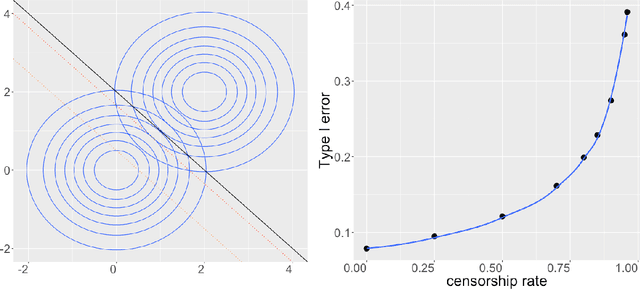

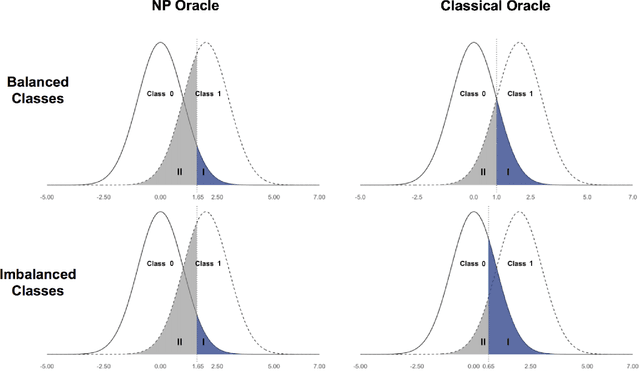

Digital texts have become an increasingly important source of data for social studies. However, textual data from open platforms are vulnerable to manipulation (e.g., censorship and information inflation), often leading to bias in subsequent empirical analysis. This paper investigates the problem of data distortion in text classification when controlling type I error (a relevant textual message is classified as irrelevant) is the priority. The default classical classification paradigm that minimizes the overall classification error can yield an undesirably large type I error, and data distortion exacerbates this situation. As a solution, we propose the Neyman-Pearson (NP) classification paradigm which minimizes type II error under a user-specified type I error constraint. Theoretically, we show that while the classical oracle (i.e., optimal classifier) cannot be recovered under unknown data distortion even if one has the entire post-distortion population, the NP oracle is unaffected by data distortion and can be recovered under the same condition. Empirically, we illustrate the advantage of NP classification methods in a case study that classifies posts about strikes and corruption published on a leading Chinese blogging platform.