 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Ranking under Disparate Uncertainty
Sep 04, 2023Ranking is a ubiquitous method for focusing the attention of human evaluators on a manageable subset of options. Its use ranges from surfacing potentially relevant products on an e-commerce site to prioritizing college applications for human review. While ranking can make human evaluation far more effective by focusing attention on the most promising options, we argue that it can introduce unfairness if the uncertainty of the underlying relevance model differs between groups of options. Unfortunately, such disparity in uncertainty appears widespread, since the relevance estimates for minority groups tend to have higher uncertainty due to a lack of data or appropriate features. To overcome this fairness issue, we propose Equal-Opportunity Ranking (EOR) as a new fairness criterion for ranking that provably corrects for the disparity in uncertainty between groups. Furthermore, we present a practical algorithm for computing EOR rankings in time $O(n \log(n))$ and prove its close approximation guarantee to the globally optimal solution. In a comprehensive empirical evaluation on synthetic data, a US Census dataset, and a real-world case study of Amazon search queries, we find that the algorithm reliably guarantees EOR fairness while providing effective rankings.
Semi-Parametric Deep Neural Networks in Linear Time and Memory
May 24, 2022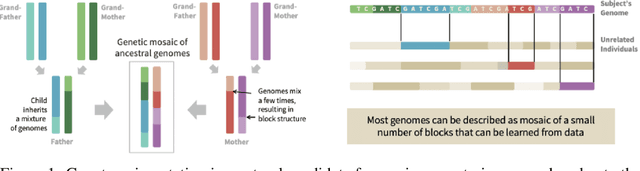
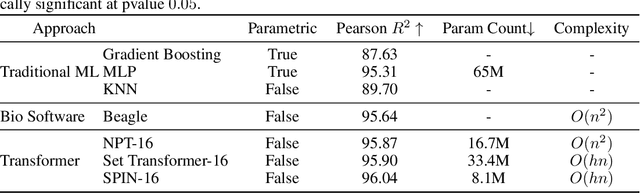
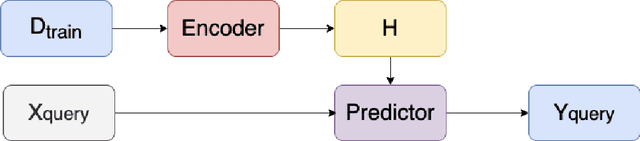

Recent advances in deep learning have been driven by large-scale parametric models, which can be computationally expensive and lack interpretability. Semi-parametric methods query the training set at inference time and can be more compact, although they typically have quadratic computational complexity. Here, we introduce SPIN, a general-purpose semi-parametric neural architecture whose computational cost is linear in the size and dimensionality of the data. Our architecture is inspired by inducing point methods and relies on a novel application of cross-attention between datapoints. At inference time, its computational cost is constant in the training set size as the data gets distilled into a fixed number of inducing points. We find that our method reduces the computational requirements of existing semi-parametric models by up to an order of magnitude across a range of datasets and improves state-of-the-art performance on an important practical problem, genotype imputation.