 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Parametric Deep Neural Networks in Linear Time and Memory
Paper and Code
May 24, 2022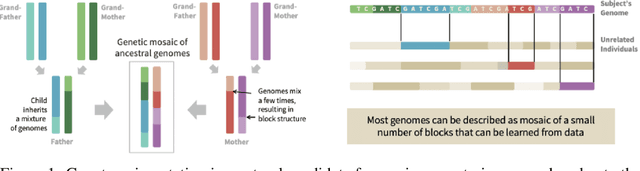
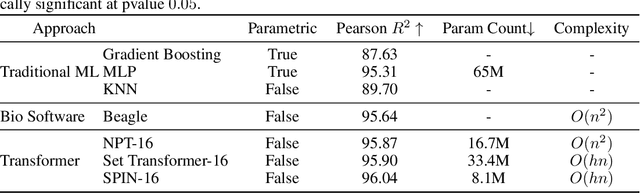
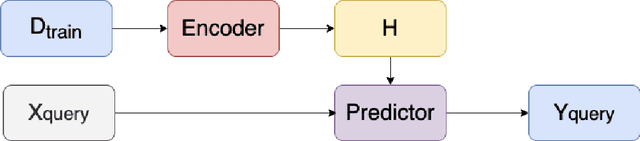

Recent advances in deep learning have been driven by large-scale parametric models, which can be computationally expensive and lack interpretability. Semi-parametric methods query the training set at inference time and can be more compact, although they typically have quadratic computational complexity. Here, we introduce SPIN, a general-purpose semi-parametric neural architecture whose computational cost is linear in the size and dimensionality of the data. Our architecture is inspired by inducing point methods and relies on a novel application of cross-attention between datapoints. At inference time, its computational cost is constant in the training set size as the data gets distilled into a fixed number of inducing points. We find that our method reduces the computational requirements of existing semi-parametric models by up to an order of magnitude across a range of datasets and improves state-of-the-art performance on an important practical problem, genotype imputation.