 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnimodal Distributions for Ordinal Regression
Mar 08, 2023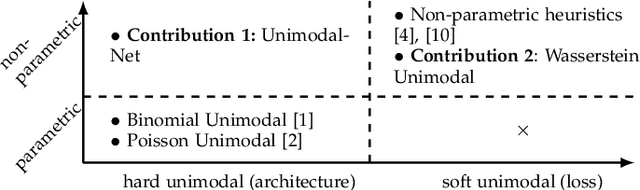



In many real-world prediction tasks, class labels contain information about the relative order between labels that are not captured by commonly used loss functions such as multicategory cross-entropy. Recently, the preference for unimodal distributions in the output space has been incorporated into models and loss functions to account for such ordering information. However, current approaches rely on heuristics that lack a theoretical foundation. Here, we propose two new approaches to incorporate the preference for unimodal distributions into the predictive model. We analyse the set of unimodal distributions in the probability simplex and establish fundamental properties. We then propose a new architecture that imposes unimodal distributions and a new loss term that relies on the notion of projection in a set to promote unimodality. Experiments show the new architecture achieves top-2 performance, while the proposed new loss term is very competitive while maintaining high unimodality.
Entropic Associative Memory for Manuscript Symbols
Feb 17, 2022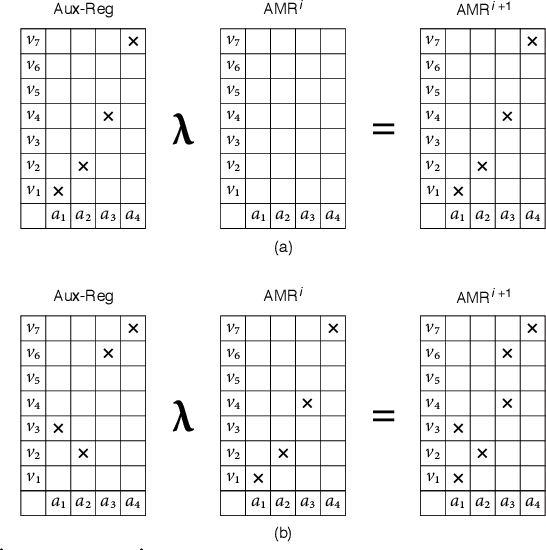
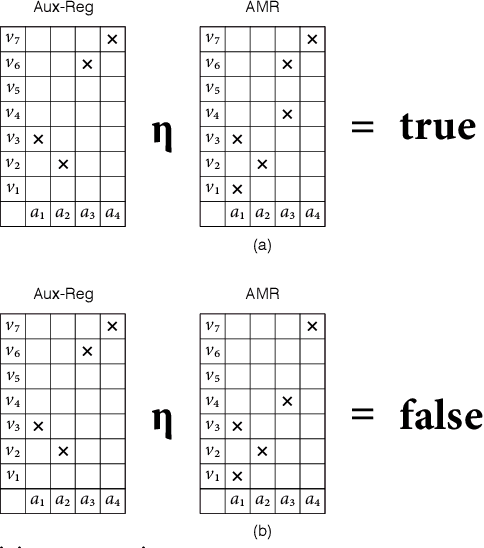
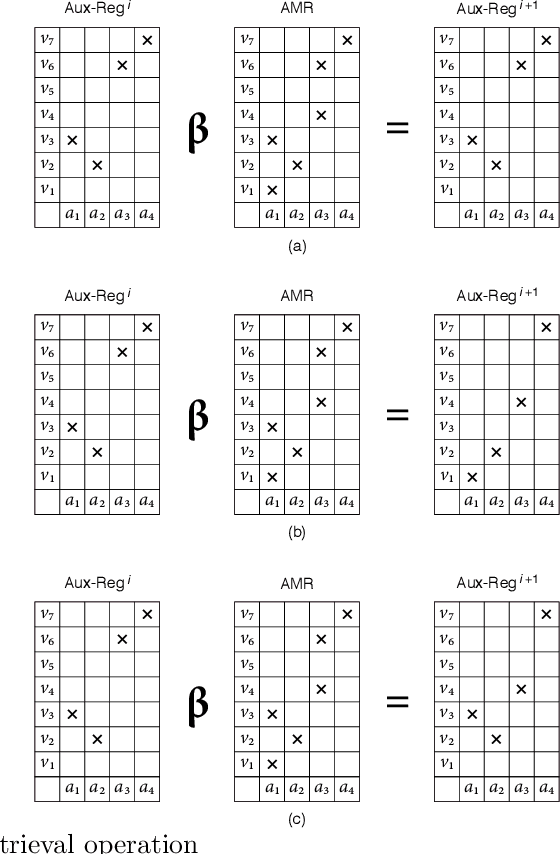
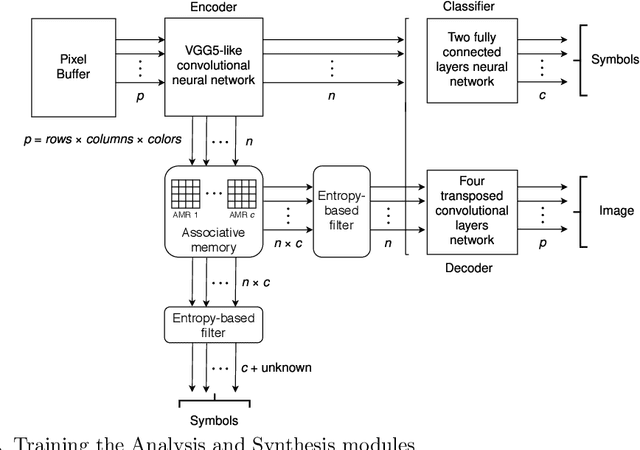
Manuscript symbols can be stored, recognized and retrieved from an entropic digital memory that is associative and distributed but yet declarative; memory retrieval is a constructive operation, memory cues to objects not contained in the memory are rejected directly without search, and memory operations can be performed through parallel computations. Manuscript symbols, both letters and numerals, are represented in Associative Memory Registers that have an associated entropy. The memory recognition operation obeys an entropy trade-off between precision and recall, and the entropy level impacts on the quality of the objects recovered through the memory retrieval operation. The present proposal is contrasted in several dimensions with neural networks models of associative memory. We discuss the operational characteristics of the entropic associative memory for retrieving objects with both complete and incomplete information, such as severe occlusions. The experiments reported in this paper add evidence on the potential of this framework for developing practical applications and computational models of natural memory.
Deliberative and Conceptual Inference in Service Robots
Dec 13, 2020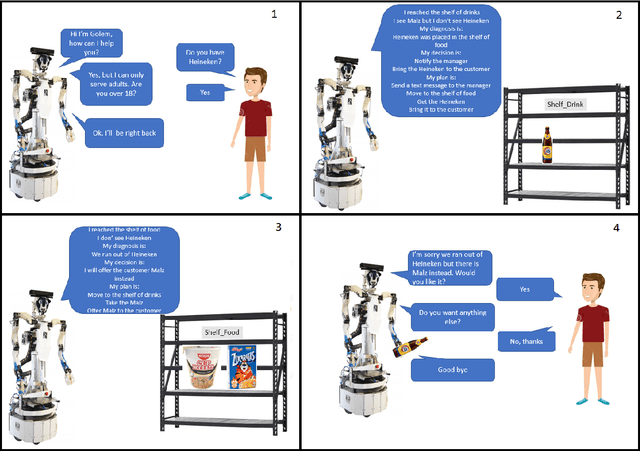
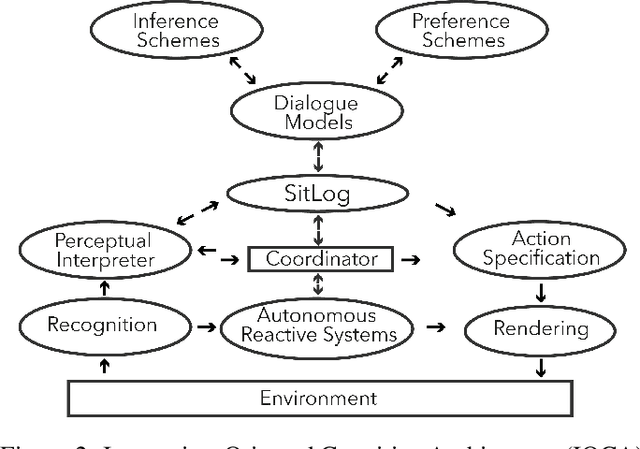
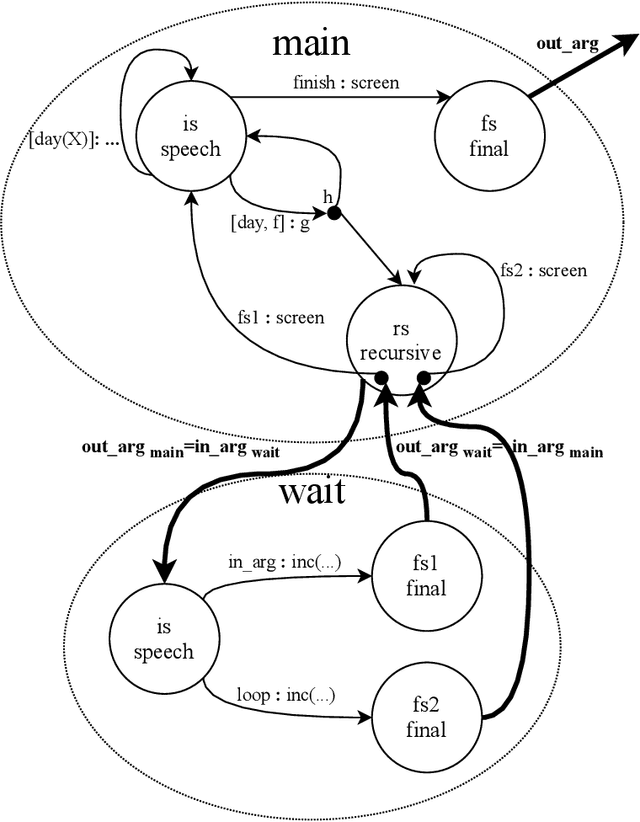
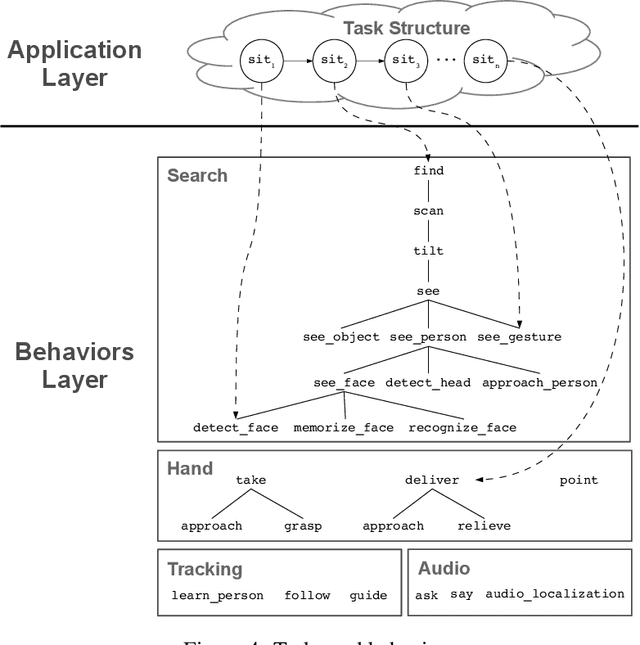
Service robots need to reason to support people in daily life situations. Reasoning is an expensive resource that should be used on demand whenever the expectations of the robot do not match the situation of the world and the execution of the task is broken down; in such scenarios the robot must perform the common sense daily life inference cycle consisting on diagnosing what happened, deciding what to do about it, and inducing and executing a plan, recurring in such behavior until the service task can be resumed. Here we examine two strategies to implement this cycle: (1) a pipe-line strategy involving abduction, decision-making and planning, which we call deliberative inference and (2) the use of the knowledge and preferences stored in the robot's knowledge-base, which we call conceptual inference. The former involves an explicit definition of a problem space that is explored through heuristic search, and the latter is based on conceptual knowledge including the human user preferences, and its representation requires a non-monotonic knowledge-based system. We compare the strengths and limitations of both approaches. We also describe a service robot conceptual model and architecture capable of supporting the daily life inference cycle during the execution of a robotics service task. The model is centered in the declarative specification and interpretation of robot's communication and task structure. We also show the implementation of this framework in the fully autonomous robot Golem-III. The framework is illustrated with two demonstration scenarios.