 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeast Squares Temporal Difference Actor-Critic Methods with Applications to Robot Motion Control
Aug 30, 2011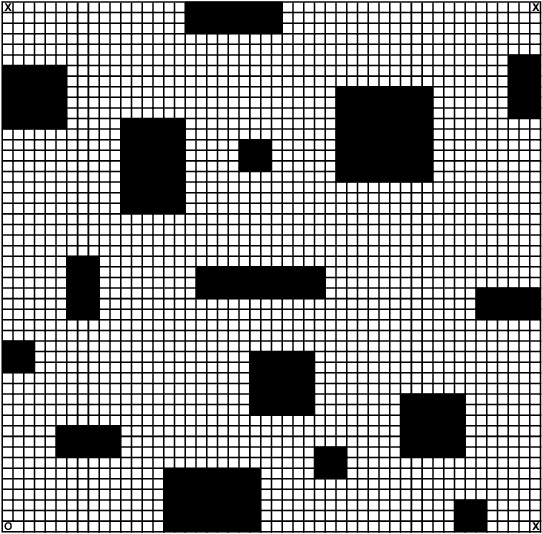
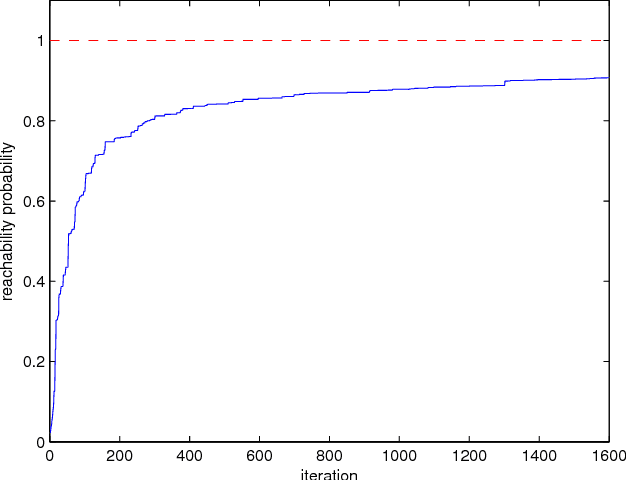
We consider the problem of finding a control policy for a Markov Decision Process (MDP) to maximize the probability of reaching some states while avoiding some other states. This problem is motivated by applications in robotics, where such problems naturally arise when probabilistic models of robot motion are required to satisfy temporal logic task specifications. We transform this problem into a Stochastic Shortest Path (SSP) problem and develop a new approximate dynamic programming algorithm to solve it. This algorithm is of the actor-critic type and uses a least-square temporal difference learning method. It operates on sample paths of the system and optimizes the policy within a pre-specified class parameterized by a parsimonious set of parameters. We show its convergence to a policy corresponding to a stationary point in the parameters' space. Simulation results confirm the effectiveness of the proposed solution.