 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereo Camera Visual SLAM with Hierarchical Masking and Motion-state Classification at Outdoor Construction Sites Containing Large Dynamic Objects
Jan 17, 2021
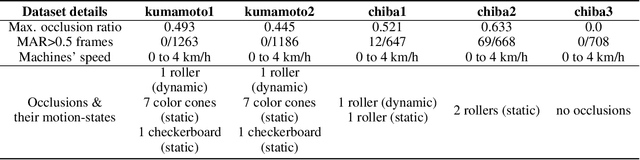


At modern construction sites, utilizing GNSS (Global Navigation Satellite System) to measure the real-time location and orientation (i.e. pose) of construction machines and navigate them is very common. However, GNSS is not always available. Replacing GNSS with on-board cameras and visual simultaneous localization and mapping (visual SLAM) to navigate the machines is a cost-effective solution. Nevertheless, at construction sites, multiple construction machines will usually work together and side-by-side, causing large dynamic occlusions in the cameras' view. Standard visual SLAM cannot handle large dynamic occlusions well. In this work, we propose a motion segmentation method to efficiently extract static parts from crowded dynamic scenes to enable robust tracking of camera ego-motion. Our method utilizes semantic information combined with object-level geometric constraints to quickly detect the static parts of the scene. Then, we perform a two-step coarse-to-fine ego-motion tracking with reference to the static parts. This leads to a novel dynamic visual SLAM formation. We test our proposals through a real implementation based on ORB-SLAM2, and datasets we collected from real construction sites. The results show that when standard visual SLAM fails, our method can still retain accurate camera ego-motion tracking in real-time. Comparing to state-of-the-art dynamic visual SLAM methods, ours shows outstanding efficiency and competitive result trajectory accuracy.
* This is an Accepted Manuscript of an article published by Taylor & Francis in Advanced Robotics on Jan. 11th, 2021, available online: https://www.tandfonline.com/doi/full/10.1080/01691864.2020.1869586 [Article DOI:10.1080/01691864.2020.1869586]
360$^\circ$ Depth Estimation from Multiple Fisheye Images with Origami Crown Representation of Icosahedron
Jul 14, 2020
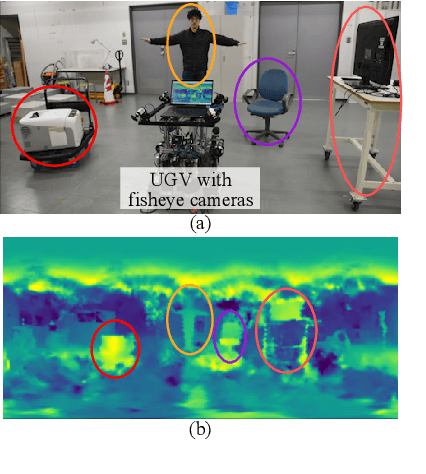
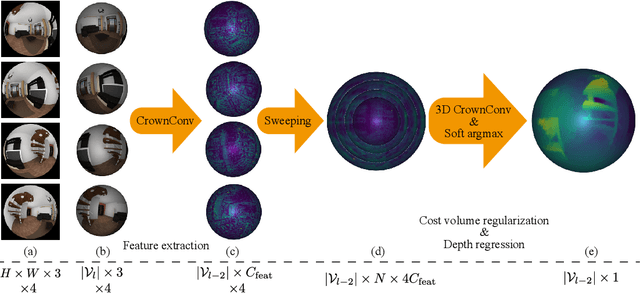
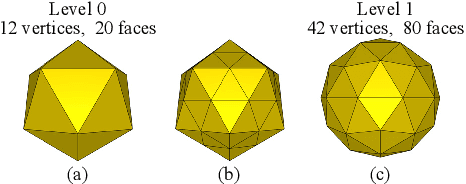
In this study, we present a method for all-around depth estimation from multiple omnidirectional images for indoor environments. In particular, we focus on plane-sweeping stereo as the method for depth estimation from the images. We propose a new icosahedron-based representation and ConvNets for omnidirectional images, which we name "CrownConv" because the representation resembles a crown made of origami. CrownConv can be applied to both fisheye images and equirectangular images to extract features. Furthermore, we propose icosahedron-based spherical sweeping for generating the cost volume on an icosahedron from the extracted features. The cost volume is regularized using the three-dimensional CrownConv, and the final depth is obtained by depth regression from the cost volume. Our proposed method is robust to camera alignments by using the extrinsic camera parameters; therefore, it can achieve precise depth estimation even when the camera alignment differs from that in the training dataset. We evaluate the proposed model on synthetic datasets and demonstrate its effectiveness. As our proposed method is computationally efficient, the depth is estimated from four fisheye images in less than a second using a laptop with a GPU. Therefore, it is suitable for real-world robotics applications. Our source code is available at https://github.com/matsuren/crownconv360depth.