 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted-BEHRT: Deep learning for observational causal inference on longitudinal electronic health records
Feb 07, 2022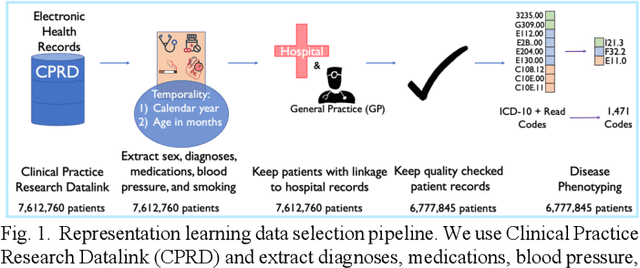
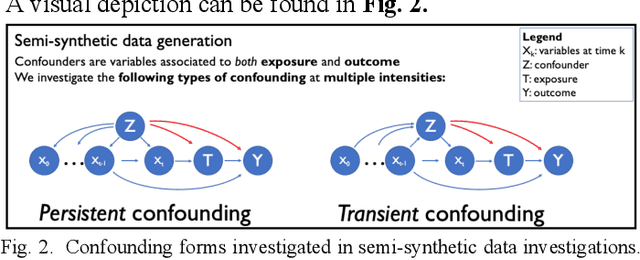
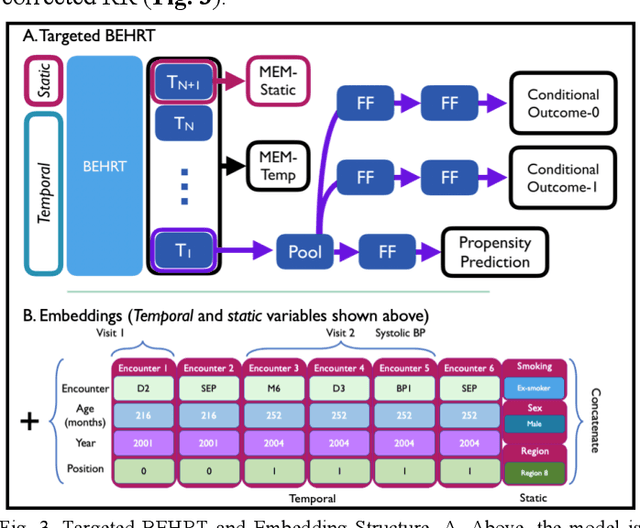
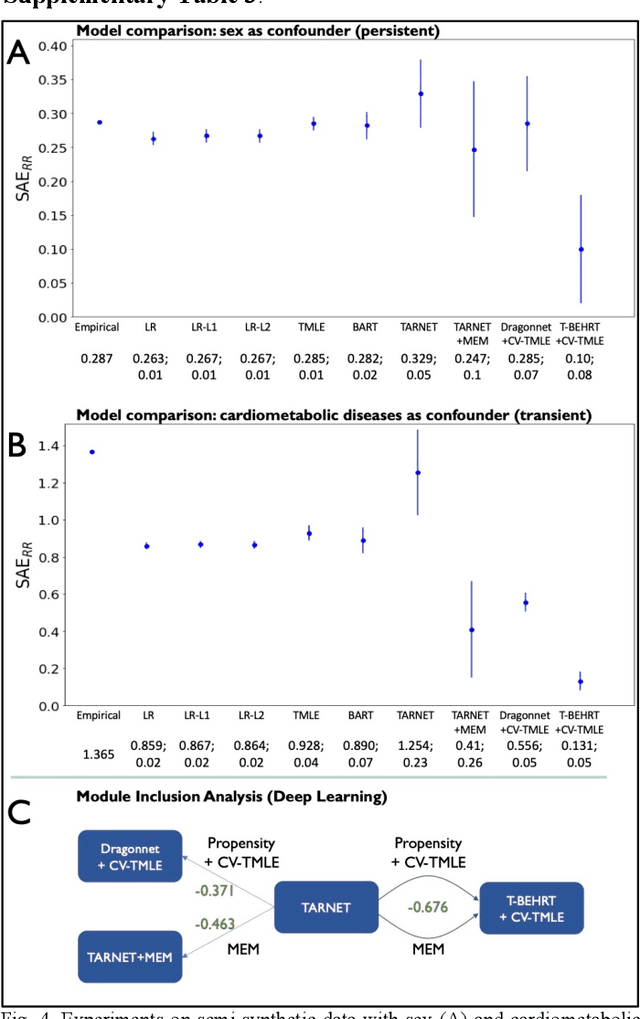
Observational causal inference is useful for decision making in medicine when randomized clinical trials (RCT) are infeasible or non generalizable. However, traditional approaches fail to deliver unconfounded causal conclusions in practice. The rise of "doubly robust" non-parametric tools coupled with the growth of deep learning for capturing rich representations of multimodal data, offers a unique opportunity to develop and test such models for causal inference on comprehensive electronic health records (EHR). In this paper, we investigate causal modelling of an RCT-established null causal association: the effect of antihypertensive use on incident cancer risk. We develop a dataset for our observational study and a Transformer-based model, Targeted BEHRT coupled with doubly robust estimation, we estimate average risk ratio (RR). We compare our model to benchmark statistical and deep learning models for causal inference in multiple experiments on semi-synthetic derivations of our dataset with various types and intensities of confounding. In order to further test the reliability of our approach, we test our model on situations of limited data. We find that our model provides more accurate estimates of RR (least sum absolute error from ground truth) compared to benchmarks for risk ratio estimation on high-dimensional EHR across experiments. Finally, we apply our model to investigate the original case study: antihypertensives' effect on cancer and demonstrate that our model generally captures the validated null association.
An explainable Transformer-based deep learning model for the prediction of incident heart failure
Jan 27, 2021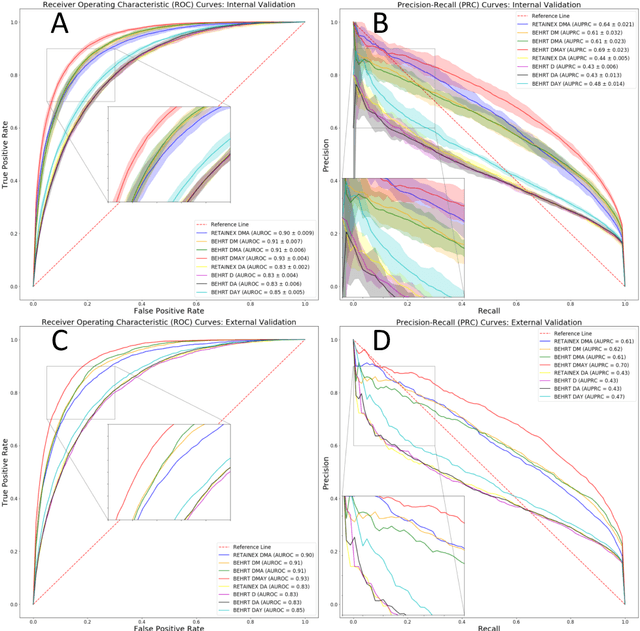
Predicting the incidence of complex chronic conditions such as heart failure is challenging. Deep learning models applied to rich electronic health records may improve prediction but remain unexplainable hampering their wider use in medical practice. We developed a novel Transformer deep-learning model for more accurate and yet explainable prediction of incident heart failure involving 100,071 patients from longitudinal linked electronic health records across the UK. On internal 5-fold cross validation and held-out external validation, our model achieved 0.93 and 0.93 area under the receiver operator curve and 0.69 and 0.70 area under the precision-recall curve, respectively and outperformed existing deep learning models. Predictor groups included all community and hospital diagnoses and medications contextualised within the age and calendar year for each patient's clinical encounter. The importance of contextualised medical information was revealed in a number of sensitivity analyses, and our perturbation method provided a way of identifying factors contributing to risk. Many of the identified risk factors were consistent with existing knowledge from clinical and epidemiological research but several new associations were revealed which had not been considered in expert-driven risk prediction models.
Deep Bayesian Gaussian Processes for Uncertainty Estimation in Electronic Health Records
Mar 23, 2020
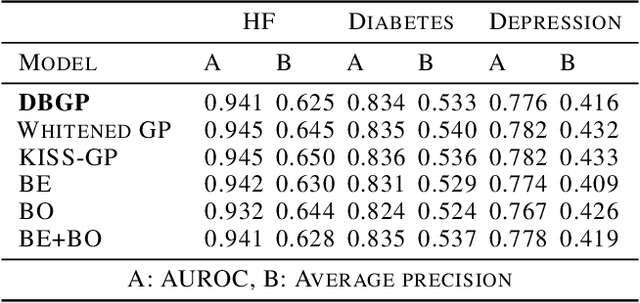

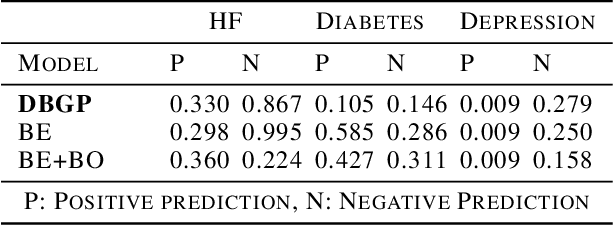
One major impediment to the wider use of deep learning for clinical decision making is the difficulty of assigning a level of confidence to model predictions. Currently, deep Bayesian neural networks and sparse Gaussian processes are the main two scalable uncertainty estimation methods. However, deep Bayesian neural network suffers from lack of expressiveness, and more expressive models such as deep kernel learning, which is an extension of sparse Gaussian process, captures only the uncertainty from the higher level latent space. Therefore, the deep learning model under it lacks interpretability and ignores uncertainty from the raw data. In this paper, we merge features of the deep Bayesian learning framework with deep kernel learning to leverage the strengths of both methods for more comprehensive uncertainty estimation. Through a series of experiments on predicting the first incidence of heart failure, diabetes and depression applied to large-scale electronic medical records, we demonstrate that our method is better at capturing uncertainty than both Gaussian processes and deep Bayesian neural networks in terms of indicating data insufficiency and distinguishing true positive and false positive predictions, with a comparable generalisation performance. Furthermore, by assessing the accuracy and area under the receiver operating characteristic curve over the predictive probability, we show that our method is less susceptible to making overconfident predictions, especially for the minority class in imbalanced datasets. Finally, we demonstrate how uncertainty information derived by the model can inform risk factor analysis towards model interpretability.