 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalProofBench: Can Models Write Graduate Level Math Proofs That Are Formally Verified?
Mar 27, 2026We present FormalProofBench, a private benchmark designed to evaluate whether AI models can produce formally verified mathematical proofs at the graduate level. Each task pairs a natural-language problem with a Lean~4 formal statement, and a model must output a Lean proof accepted by the Lean 4 checker. FormalProofBench targets advanced undergraduate and graduate mathematics, with problems drawn from qualifying exams and standard textbooks across topics including analysis, algebra, probability, and logic. We evaluate a range of frontier models with an agentic harness, and find that the best-performing foundation model achieves 33.5% accuracy, with performance dropping rapidly after that. In addition to the accuracy numbers, we also provide empirical analysis of tool-use, failure modes, cost and latency, thereby providing a thorough evaluation of the formal-theorem proving abilities of frontier models.
Vibe Code Bench: Evaluating AI Models on End-to-End Web Application Development
Mar 04, 2026Code generation has emerged as one of AI's highest-impact use cases, yet existing benchmarks measure isolated tasks rather than the complete "zero-to-one" process of building a working application from scratch. We introduce Vibe Code Bench, a benchmark of 100 web application specifications (50 public validation, 50 held-out test) with 964 browser-based workflows comprising 10,131 substeps, evaluated against deployed applications by an autonomous browser agent. Across 16 frontier models, the best achieves only 58.0% accuracy on the test split, revealing that reliable end-to-end application development remains a frontier challenge. We identify self-testing during generation as a strong performance predictor (Pearson r=0.72), and show through a completed human alignment study that evaluator selection materially affects outcomes (31.8-93.6% pairwise step-level agreement). Our contributions include (1) a novel benchmark dataset and browser-based evaluation pipeline for end-to-end web application development, (2) a comprehensive evaluation of 16 frontier models with cost, latency, and error analysis, and (3) an evaluator alignment protocol with both cross-model and human annotation results.
CheXbreak: Misclassification Identification for Deep Learning Models Interpreting Chest X-rays
Mar 24, 2021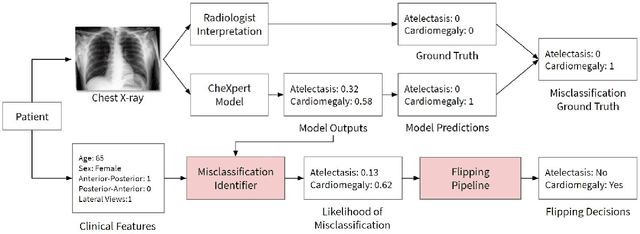
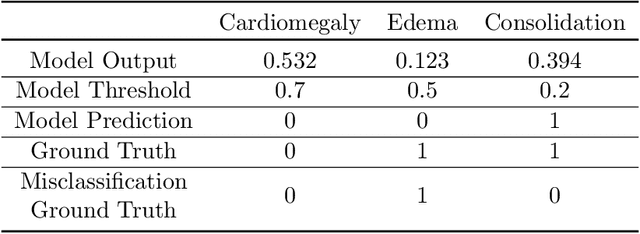
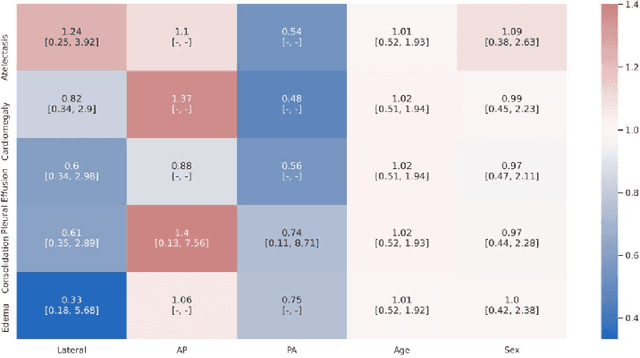
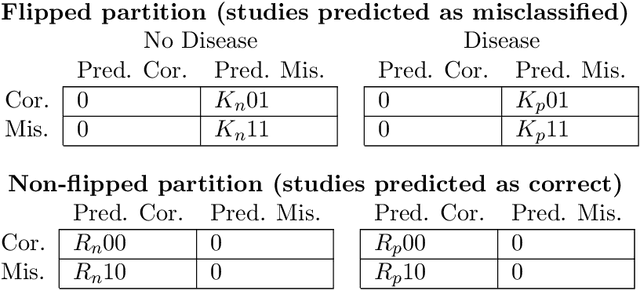
A major obstacle to the integration of deep learning models for chest x-ray interpretation into clinical settings is the lack of understanding of their failure modes. In this work, we first investigate whether there are patient subgroups that chest x-ray models are likely to misclassify. We find that patient age and the radiographic finding of lung lesion, pneumothorax or support devices are statistically relevant features for predicting misclassification for some chest x-ray models. Second, we develop misclassification predictors on chest x-ray models using their outputs and clinical features. We find that our best performing misclassification identifier achieves an AUROC close to 0.9 for most diseases. Third, employing our misclassification identifiers, we develop a corrective algorithm to selectively flip model predictions that have high likelihood of misclassification at inference time. We observe F1 improvement on the prediction of Consolidation (0.008 [95\% CI 0.005, 0.010]) and Edema (0.003, [95\% CI 0.001, 0.006]). By carrying out our investigation on ten distinct and high-performing chest x-ray models, we are able to derive insights across model architectures and offer a generalizable framework applicable to other medical imaging tasks.
Using LSTM and SARIMA Models to Forecast Cluster CPU Usage
Jul 16, 2020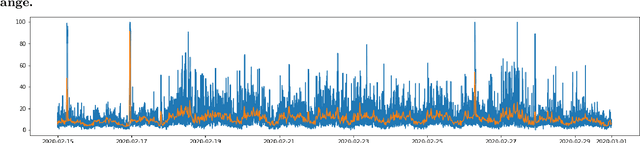

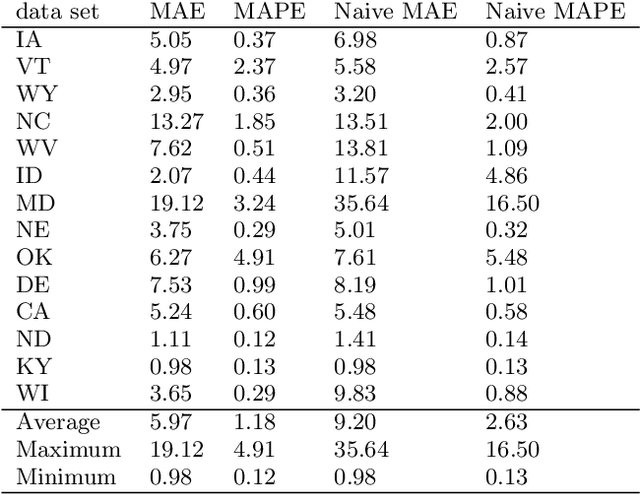
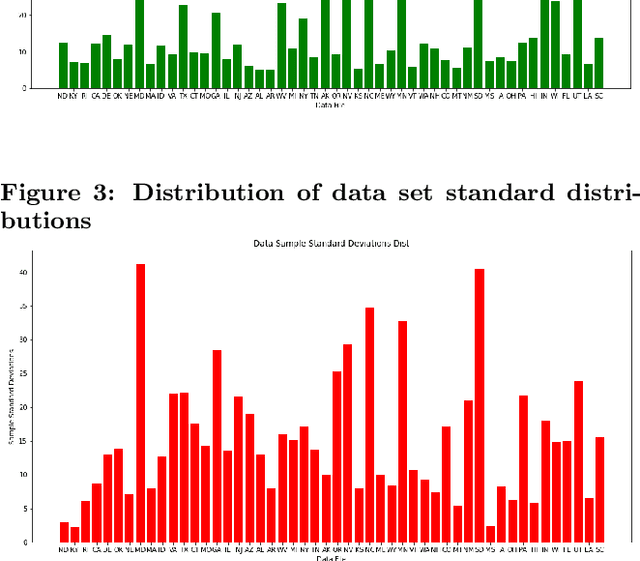
As large scale cloud computing centers become more popular than individual servers, predicting future resource demand need has become an important problem. Forecasting resource need allows public cloud providers to proactively allocate or deallocate resources for cloud services. This work seeks to predict one resource, CPU usage, over both a short term and long term time scale. To gain insight into the model characteristics that best support specific tasks, we consider two vastly different architectures: the historically relevant SARIMA model and the more modern neural network, LSTM model. We apply these models to Azure data resampled to 20 minutes per data point with the goal of predicting usage over the next hour for the short-term task and for the next three days for the long-term task. The SARIMA model outperformed the LSTM for the long term prediction task, but performed poorer on the short term task. Furthermore, the LSTM model was more robust, whereas the SARIMA model relied on the data meeting certain assumptions about seasonality.
CheXphoto: 10,000+ Smartphone Photos and Synthetic Photographic Transformations of Chest X-rays for Benchmarking Deep Learning Robustness
Jul 13, 2020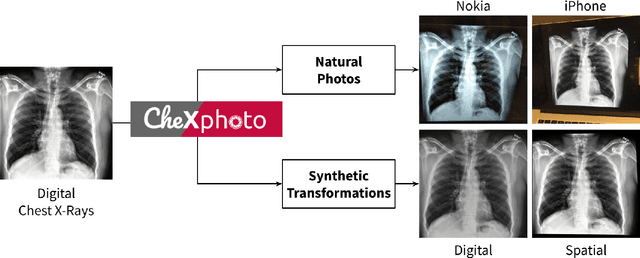
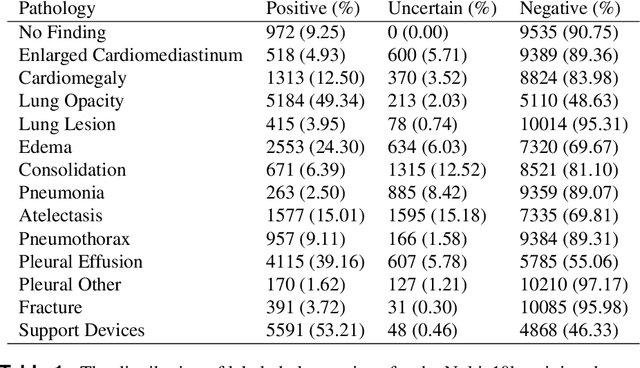
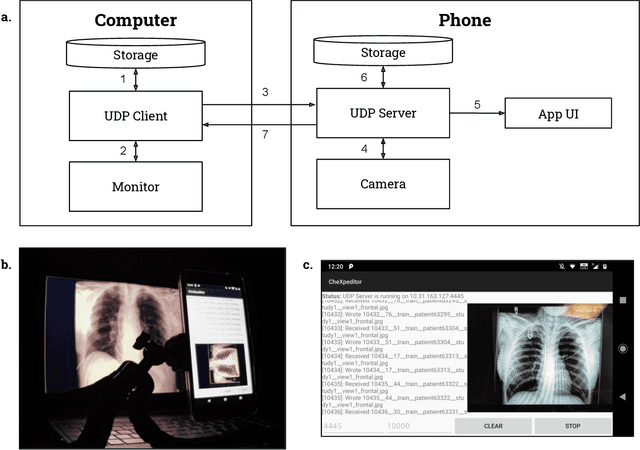
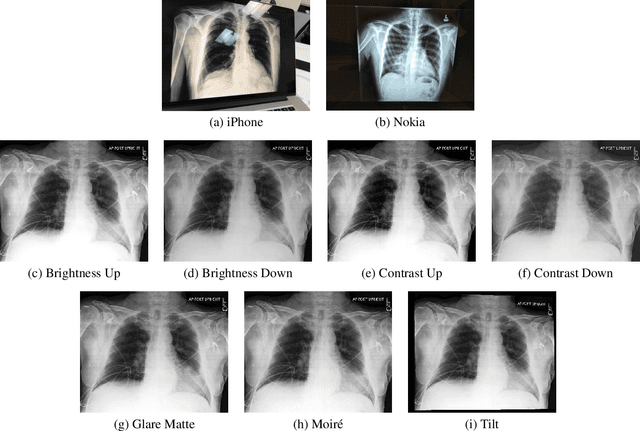
Clinical deployment of deep learning algorithms for chest x-ray interpretation requires a solution that can integrate into the vast spectrum of clinical workflows across the world. An appealing solution to scaled deployment is to leverage the existing ubiquity of smartphones: in several parts of the world, clinicians and radiologists capture photos of chest x-rays to share with other experts or clinicians via smartphone using messaging services like WhatsApp. However, the application of chest x-ray algorithms to photos of chest x-rays requires reliable classification in the presence of smartphone photo artifacts such as screen glare and poor viewing angle not typically encountered on digital x-rays used to train machine learning models. We introduce CheXphoto, a dataset of smartphone photos and synthetic photographic transformations of chest x-rays sampled from the CheXpert dataset. To generate CheXphoto we (1) automatically and manually captured photos of digital x-rays under different settings, including various lighting conditions and locations, and, (2) generated synthetic transformations of digital x-rays targeted to make them look like photos of digital x-rays and x-ray films. We release this dataset as a resource for testing and improving the robustness of deep learning algorithms for automated chest x-ray interpretation on smartphone photos of chest x-rays.