 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Nonnegative Matrix Factorization via Multi-Scale Graph Regularization
Feb 26, 2026Matrix factorization techniques, especially Nonnegative Matrix Factorization (NMF), have been widely used for dimensionality reduction and interpretable data representation. However, existing NMF-based methods are inherently single-scale and fail to capture the evolution of connectivity structures across resolutions. In this work, we propose persistent nonnegative matrix factorization (pNMF), a scale-parameterized family of NMF problems, that produces a sequence of persistence-aligned embeddings rather than a single one. By leveraging persistent homology, we identify a canonical minimal sufficient scale set at which the underlying connectivity undergoes qualitative changes. These canonical scales induce a sequence of graph Laplacians, leading to a coupled NMF formulation with scale-wise geometric regularization and explicit cross-scale consistency constraint. We analyze the structural properties of the embeddings along the scale parameter and establish bounds on their increments between consecutive scales. The resulting model defines a nontrivial solution path across scales, rather than a single factorization, which poses new computational challenges. We develop a sequential alternating optimization algorithm with guaranteed convergence. Numerical experiments on synthetic and single-cell RNA sequencing datasets demonstrate the effectiveness of the proposed approach in multi-scale low-rank embeddings.
PatSTEG: Modeling Formation Dynamics of Patent Citation Networks via The Semantic-Topological Evolutionary Graph
Feb 03, 2024Patent documents in the patent database (PatDB) are crucial for research, development, and innovation as they contain valuable technical information. However, PatDB presents a multifaceted challenge compared to publicly available preprocessed databases due to the intricate nature of the patent text and the inherent sparsity within the patent citation network. Although patent text analysis and citation analysis bring new opportunities to explore patent data mining, no existing work exploits the complementation of them. To this end, we propose a joint semantic-topological evolutionary graph learning approach (PatSTEG) to model the formation dynamics of patent citation networks. More specifically, we first create a real-world dataset of Chinese patents named CNPat and leverage its patent texts and citations to construct a patent citation network. Then, PatSTEG is modeled to study the evolutionary dynamics of patent citation formation by considering the semantic and topological information jointly. Extensive experiments are conducted on CNPat and public datasets to prove the superiority of PatSTEG over other state-of-the-art methods. All the results provide valuable references for patent literature research and technical exploration.
Tongji University Undergraduate Team for the VoxCeleb Speaker Recognition Challenge2020
Oct 20, 2020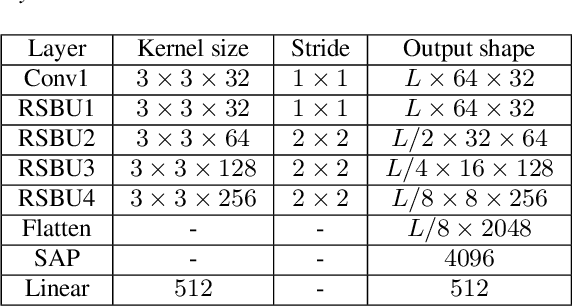
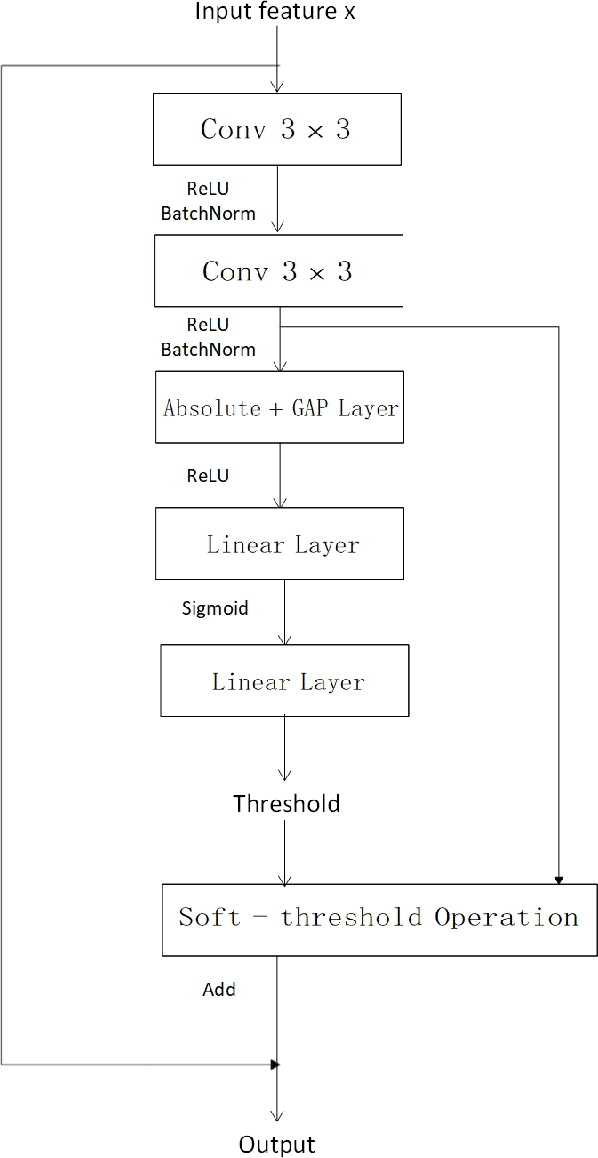

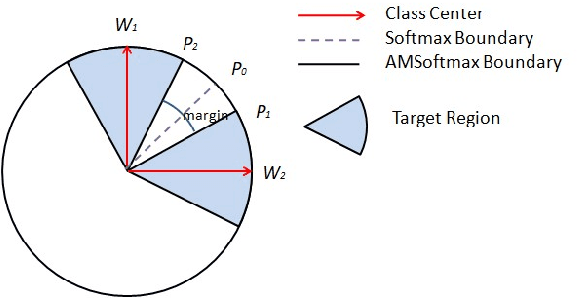
In this report, we discribe the submission of Tongji University undergraduate team to the CLOSE track of the VoxCeleb Speaker Recognition Challenge (VoxSRC) 2020 at Interspeech 2020. We applied the RSBU-CW module to the ResNet34 framework to improve the denoising ability of the network and better complete the speaker verification task in a complex environment.We trained two variants of ResNet,used score fusion and data-augmentation methods to improve the performance of the model. Our fusion of two selected systems for the CLOSE track achieves 0.2973 DCF and 4.9700\% EER on the challenge evaluation set.