 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Guided Mutual Consistency Learning for Semi-Supervised Medical Image Segmentation
Dec 05, 2021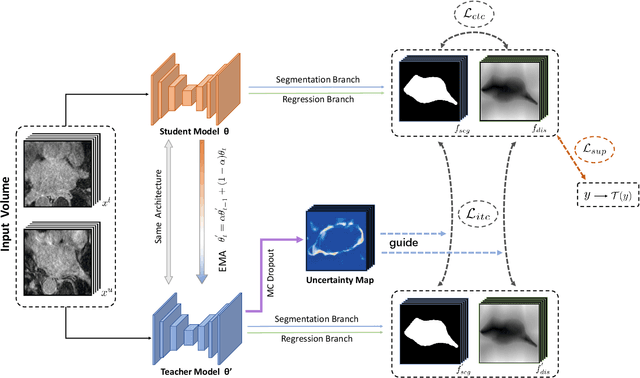
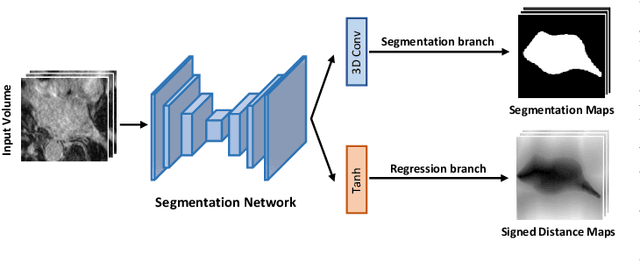
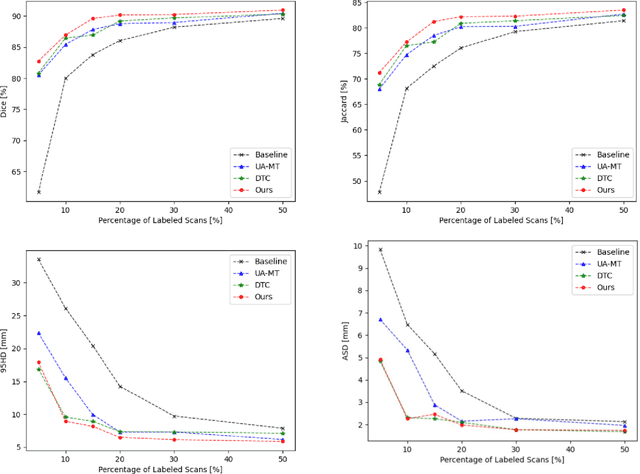
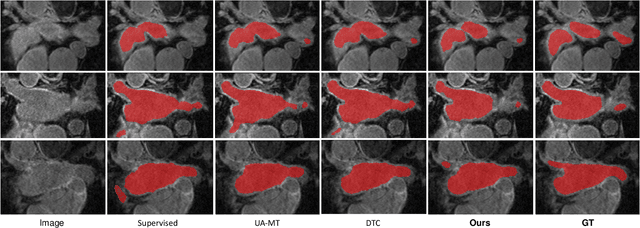
Medical image segmentation is a fundamental and critical step in many clinical approaches. Semi-supervised learning has been widely applied to medical image segmentation tasks since it alleviates the heavy burden of acquiring expert-examined annotations and takes the advantage of unlabeled data which is much easier to acquire. Although consistency learning has been proven to be an effective approach by enforcing an invariance of predictions under different distributions, existing approaches cannot make full use of region-level shape constraint and boundary-level distance information from unlabeled data. In this paper, we propose a novel uncertainty-guided mutual consistency learning framework to effectively exploit unlabeled data by integrating intra-task consistency learning from up-to-date predictions for self-ensembling and cross-task consistency learning from task-level regularization to exploit geometric shape information. The framework is guided by the estimated segmentation uncertainty of models to select out relatively certain predictions for consistency learning, so as to effectively exploit more reliable information from unlabeled data. We extensively validate our proposed method on two publicly available benchmark datasets: Left Atrium Segmentation (LA) dataset and Brain Tumor Segmentation (BraTS) dataset. Experimental results demonstrate that our method achieves performance gains by leveraging unlabeled data and outperforms existing semi-supervised segmentation methods.
Exploiting Shared Knowledge from Non-COVID Lesions for Annotation-Efficient COVID-19 CT Lung Infection Segmentation
Dec 31, 2020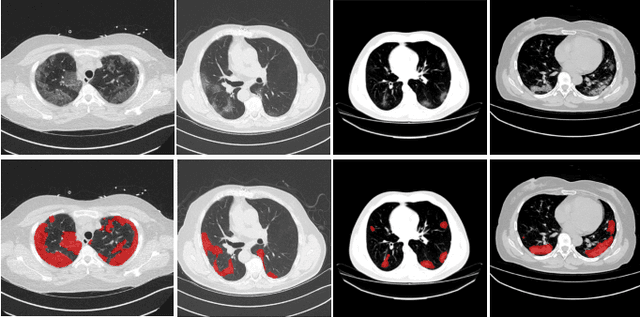
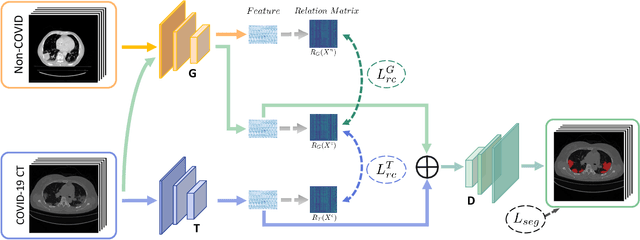
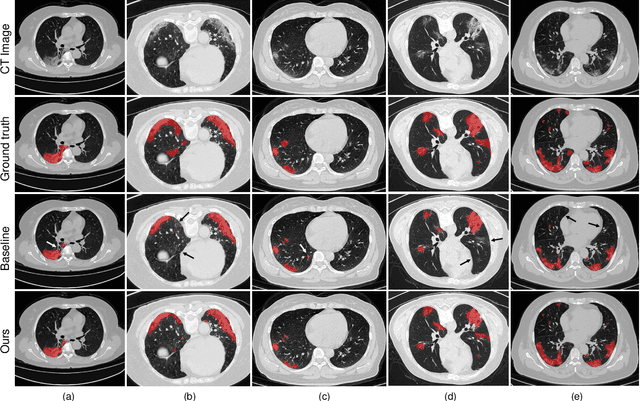
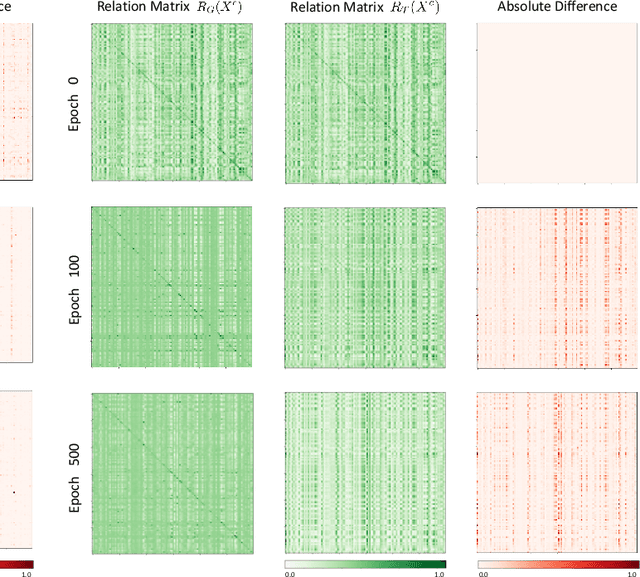
The novel Coronavirus disease (COVID-19) is a highly contagious virus and has spread all over the world, posing an extremely serious threat to all countries. Automatic lung infection segmentation from computed tomography (CT) plays an important role in the quantitative analysis of COVID-19. However, the major challenge lies in the inadequacy of annotated COVID-19 datasets. Currently, there are several public non-COVID lung lesion segmentation datasets, providing the potential for generalizing useful information to the related COVID-19 segmentation task. In this paper, we propose a novel relation-driven collaborative learning model for annotation-efficient COVID-19 CT lung infection segmentation. The network consists of encoders with the same architecture and a shared decoder. The general encoder is adopted to capture general lung lesion features based on multiple non-COVID lesions, while the target encoder is adopted to focus on task-specific features of COVID-19 infections. Features extracted from the two parallel encoders are concatenated for the subsequent decoder part. To thoroughly exploit shared knowledge between COVID and non-COVID lesions, we develop a collaborative learning scheme to regularize the relation consistency between extracted features of given input. Other than existing consistency-based methods that simply enforce the consistency of individual predictions, our method enforces the consistency of feature relation among samples, encouraging the model to explore semantic information from both COVID-19 and non-COVID cases. Extensive experiments on one public COVID-19 dataset and two public non-COVID datasets show that our method achieves superior segmentation performance compared with existing methods in the absence of sufficient high-quality COVID-19 annotations.
Exploring Efficient Volumetric Medical Image Segmentation Using 2.5D Method: An Empirical Study
Oct 13, 2020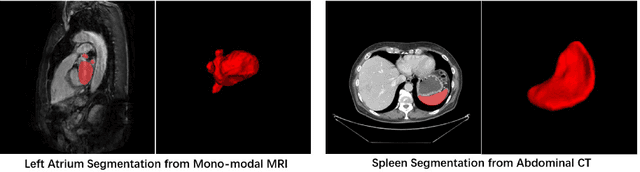
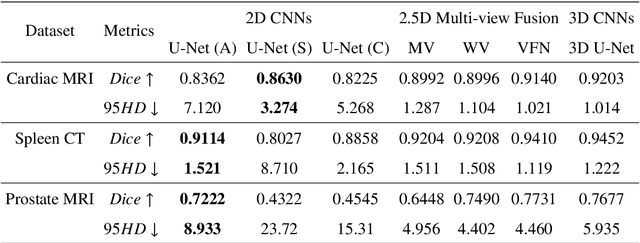
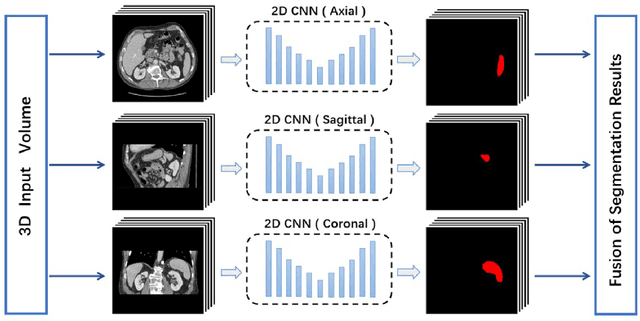
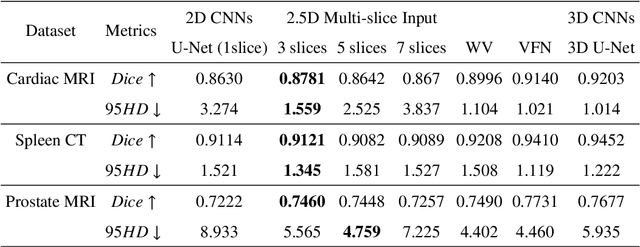
With the unprecedented developments in deep learning, many methods are proposed and have achieved great success for medical image segmentation. However, unlike segmentation of natural images, most medical images such as MRI and CT are volumetric data. In order to make full use of volumetric information, 3D CNNs are widely used. However, 3D CNNs suffer from higher inference time and computation cost, which hinders their further clinical applications. Additionally, with the increased number of parameters, the risk of overfitting is higher, especially for medical images where data and annotations are expensive to acquire. To issue this problem, many 2.5D segmentation methods have been proposed to make use of volumetric spatial information with less computation cost. Despite these works lead to improvements on a variety of segmentation tasks, to the best of our knowledge, there has not previously been a large-scale empirical comparison of these methods. In this paper, we aim to present a review of the latest developments of 2.5D methods for volumetric medical image segmentation. Additionally, to compare the performance and effectiveness of these methods, we provide an empirical study of these methods on three representative segmentation tasks involving different modalities and targets. Our experimental results highlight that 3D CNNs may not always be the best choice. Besides, although all these 2.5D methods can bring performance gains to 2D baseline, not all the methods hold the benefits on different datasets. We hope the results and conclusions of our study will prove useful for the community on exploring and developing efficient volumetric medical image segmentation methods.