 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperresolution Reconstruction of Single Image for Latent features
Nov 25, 2022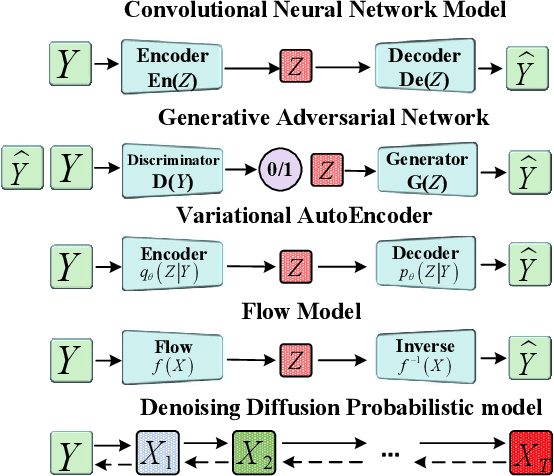

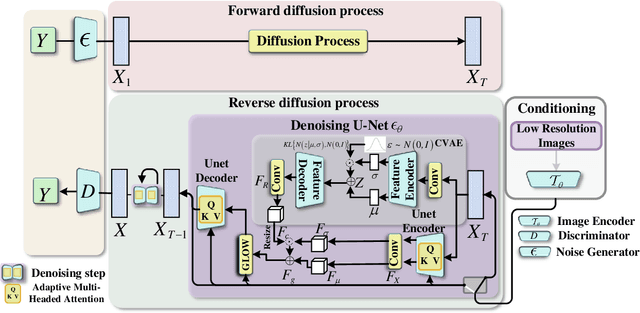
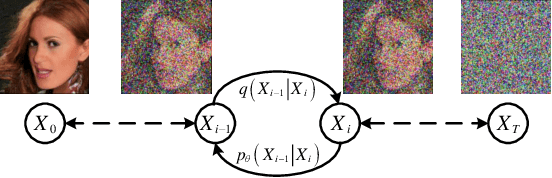
In recent years, Deep Learning has shown good results in the Single Image Superresolution Reconstruction (SISR) task, thus becoming the most widely used methods in this field. The SISR task is a typical task to solve an uncertainty problem. Therefore, it is often challenging to meet the requirements of High-quality sampling, fast Sampling, and diversity of details and texture after Sampling simultaneously in a SISR task.It leads to model collapse, lack of details and texture features after Sampling, and too long Sampling time in High Resolution (HR) image reconstruction methods. This paper proposes a Diffusion Probability model for Latent features (LDDPM) to solve these problems. Firstly, a Conditional Encoder is designed to effectively encode Low-Resolution (LR) images, thereby reducing the solution space of reconstructed images to improve the performance of reconstructed images. Then, the Normalized Flow and Multi-modal adversarial training are used to model the denoising distribution with complex Multi-modal distribution so that the Generative Modeling ability of the model can be improved with a small number of Sampling steps. Experimental results on mainstream datasets demonstrate that our proposed model reconstructs more realistic HR images and obtains better PSNR and SSIM performance compared to existing SISR tasks, thus providing a new idea for SISR tasks.
Domain Shift-oriented Machine Anomalous Sound Detection Model Based on Self-Supervised Learning
Aug 31, 2022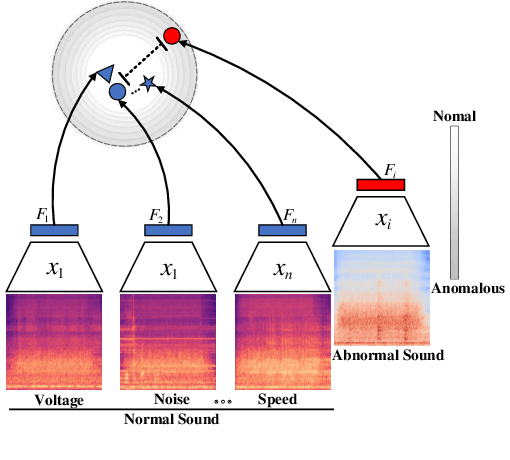
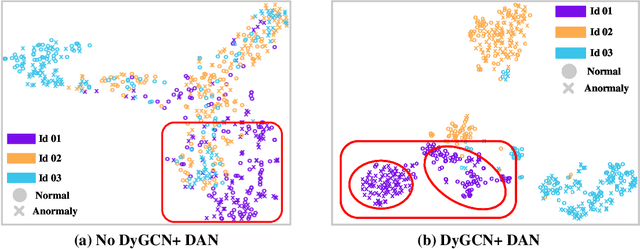
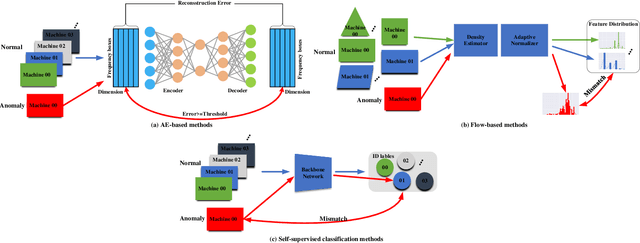
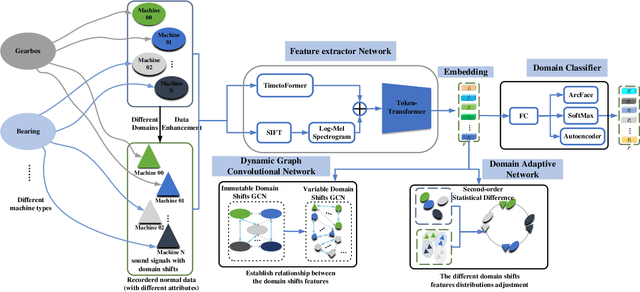
Thanks to the development of deep learning, research on machine anomalous sound detection based on self-supervised learning has made remarkable achievements. However, there are differences in the acoustic characteristics of the test set and the training set under different operating conditions of the same machine (domain shifts). It is challenging for the existing detection methods to learn the domain shifts features stably with low computation overhead. To address these problems, we propose a domain shift-oriented machine anomalous sound detection model based on self-supervised learning (TranSelf-DyGCN) in this paper. Firstly, we design a time-frequency domain feature modeling network to capture global and local spatial and time-domain features, thus improving the stability of machine anomalous sound detection stability under domain shifts. Then, we adopt a Dynamic Graph Convolutional Network (DyGCN) to model the inter-dependence relationship between domain shifts features, enabling the model to perceive domain shifts features efficiently. Finally, we use a Domain Adaptive Network (DAN) to compensate for the performance decrease caused by domain shifts, making the model adapt to anomalous sound better in the self-supervised environment. The performance of the suggested model is validated on DCASE 2020 task 2 and DCASE 2022 task 2.