 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariable Selection and Regularization via Arbitrary Rectangle-range Generalized Elastic Net
Dec 14, 2021
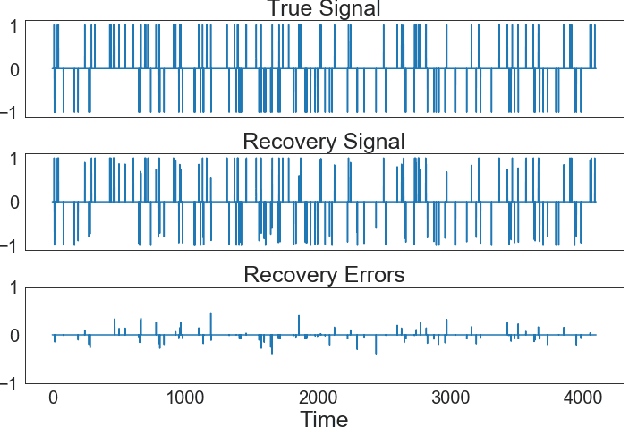
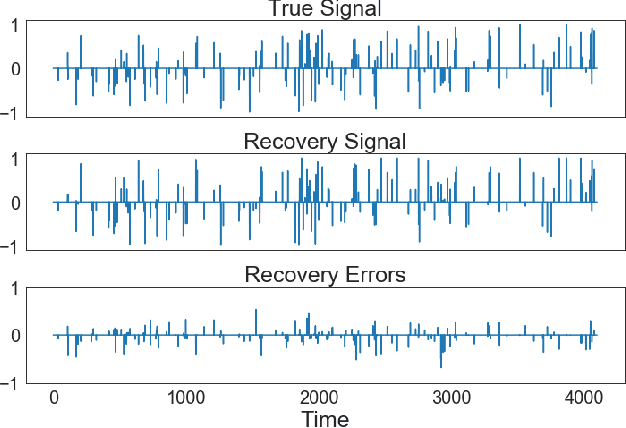
We introduce the arbitrary rectangle-range generalized elastic net penalty method, abbreviated to ARGEN, for performing constrained variable selection and regularization in high-dimensional sparse linear models. As a natural extension of the nonnegative elastic net penalty method, ARGEN is proved to have variable selection consistency and estimation consistency under some conditions. The asymptotic behavior in distribution of the ARGEN estimators have been studied. We also propose an algorithm called MU-QP-RR-W-$l_1$ to efficiently solve ARGEN. By conducting simulation study we show that ARGEN outperforms the elastic net in a number of settings. Finally an application of S&P 500 index tracking with constraints on the stock allocations is performed to provide general guidance for adapting ARGEN to solve real-world problems.
Some Developments in Clustering Analysis on Stochastic Processes
Aug 05, 2019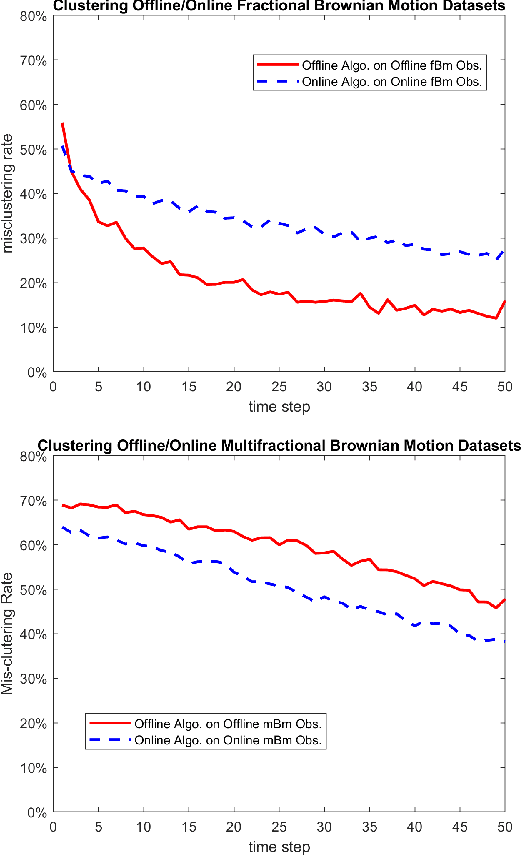
We review some developments on clustering stochastic processes and come with the conclusion that asymptotically consistent clustering algorithms can be obtained when the processes are ergodic and the dissimilarity measure satisfies the triangle inequality. Examples are provided when the processes are distribution ergodic, covariance ergodic and locally asymptotically self-similar, respectively.
Clustering Analysis on Locally Asymptotically Self-similar Processes with Known Number of Clusters
Nov 04, 2018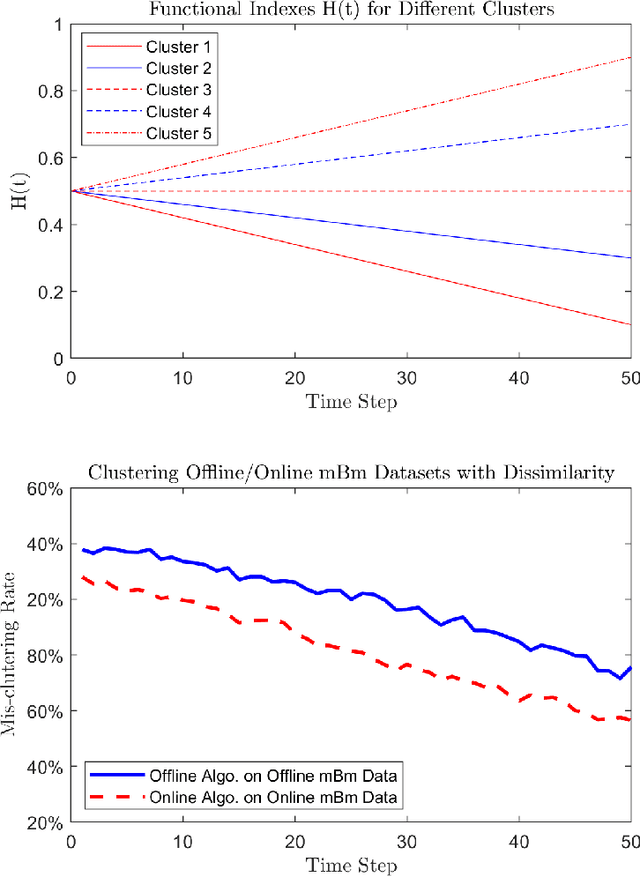
We study the problems of clustering locally asymptotically self-similar stochastic processes, when the true number of clusters is priorly known. A new covariance-based dissimilarity measure is introduced, from which the so-called approximately asymptotically consistent clustering algorithms are obtained. In a simulation study, clustering data sampled from multifractional Brownian motions is performed to illustrate the approximated asymptotic consistency of the proposed algorithms.
Covariance-based Dissimilarity Measures Applied to Clustering Wide-sense Stationary Ergodic Processes
Jan 27, 2018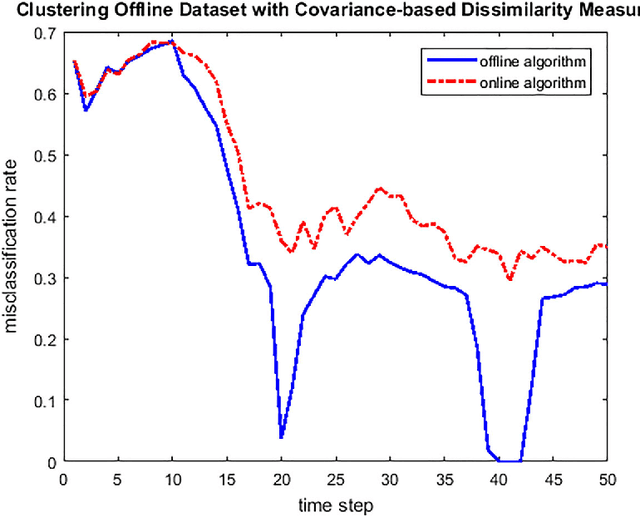
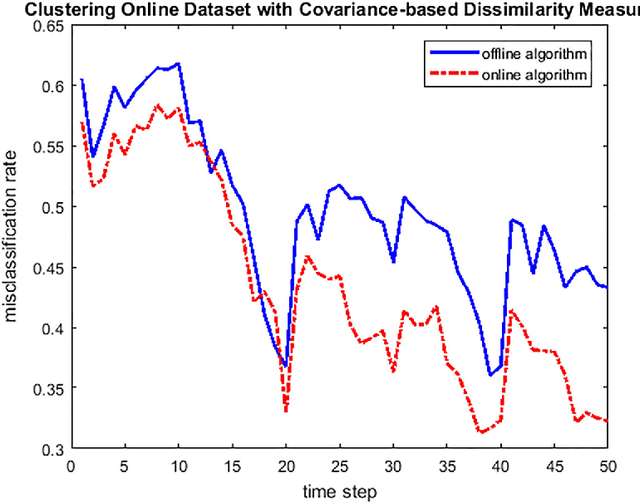

We introduce a new unsupervised learning problem: clustering wide-sense stationary ergodic stochastic processes. A covariance-based dissimilarity measure and consistent algorithms are designed for clustering offline and online data settings, respectively. We also suggest a formal criterion on the efficiency of dissimilarity measures, and discuss of some approach to improve the efficiency of clustering algorithms, when they are applied to cluster particular type of processes, such as self-similar processes with wide-sense stationary ergodic increments. Clustering synthetic data sampled from fractional Brownian motions is provided as an example of application.