 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset and Benchmark for Malaria Life-Cycle Classification in Thin Blood Smear Images
Feb 17, 2021
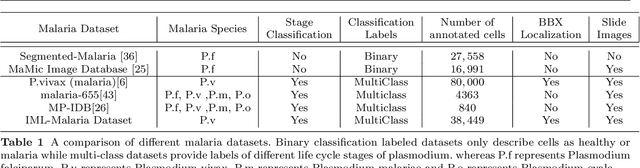


Malaria microscopy, microscopic examination of stained blood slides to detect parasite Plasmodium, is considered to be a gold-standard for detecting life-threatening disease malaria. Detecting the plasmodium parasite requires a skilled examiner and may take up to 10 to 15 minutes to completely go through the whole slide. Due to a lack of skilled medical professionals in the underdeveloped or resource deficient regions, many cases go misdiagnosed; resulting in unavoidable complications and/or undue medication. We propose to complement the medical professionals by creating a deep learning-based method to automatically detect (localize) the plasmodium parasites in the photograph of stained film. To handle the unbalanced nature of the dataset, we adopt a two-stage approach. Where the first stage is trained to detect blood cells and classify them into just healthy or infected. The second stage is trained to classify each detected cell further into the life-cycle stage. To facilitate the research in machine learning-based malaria microscopy, we introduce a new large scale microscopic image malaria dataset. Thirty-eight thousand cells are tagged from the 345 microscopic images of different Giemsa-stained slides of blood samples. Extensive experimentation is performed using different CNN backbones including VGG, DenseNet, and ResNet on this dataset. Our experiments and analysis reveal that the two-stage approach works better than the one-stage approach for malaria detection. To ensure the usability of our approach, we have also developed a mobile app that will be used by local hospitals for investigation and educational purposes. The dataset, its annotations, and implementation codes will be released upon publication of the paper.
Action recognition in real-world videos
Apr 22, 2020
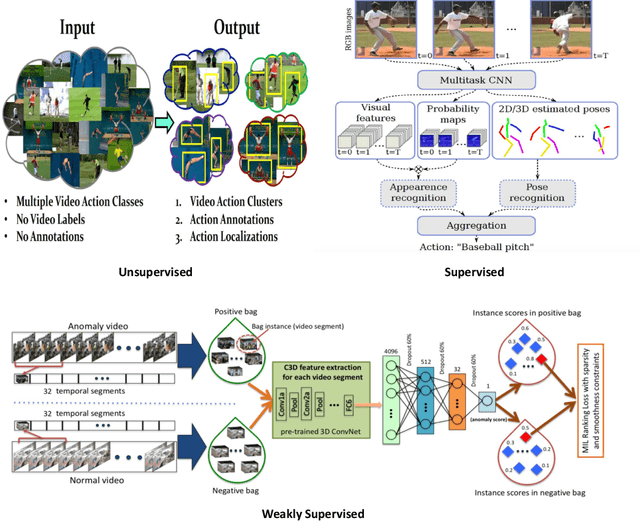
The goal of human action recognition is to temporally or spatially localize the human action of interest in video sequences. Temporal localization (i.e. indicating the start and end frames of the action in a video) is referred to as frame-level detection. Spatial localization, which is more challenging, means to identify the pixels within each action frame that correspond to the action. This setting is usually referred to as pixel-level detection. In this chapter, we are using action, activity, event interchangeably.